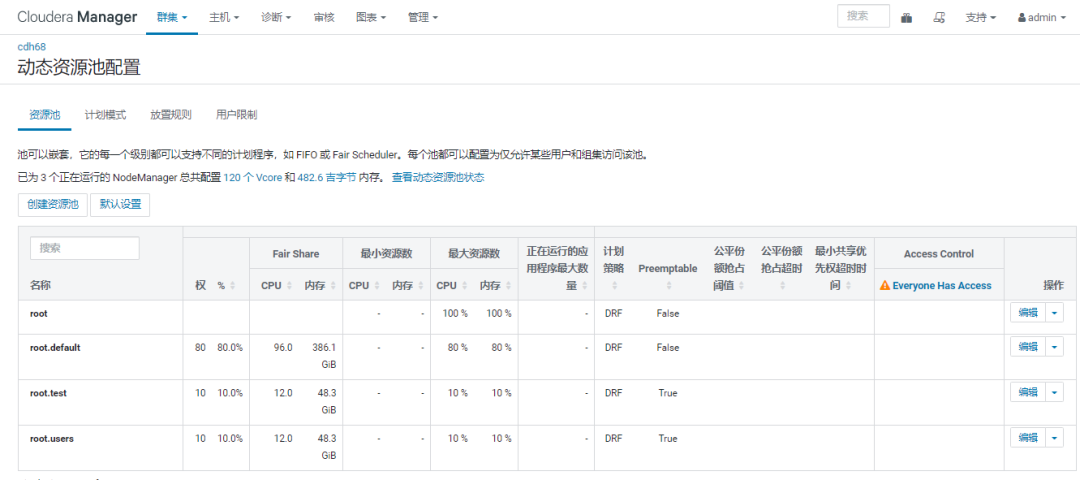
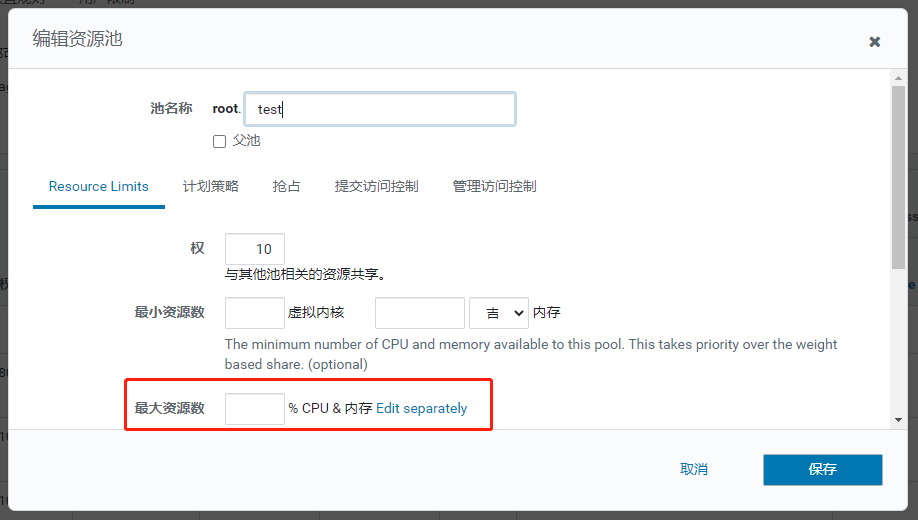
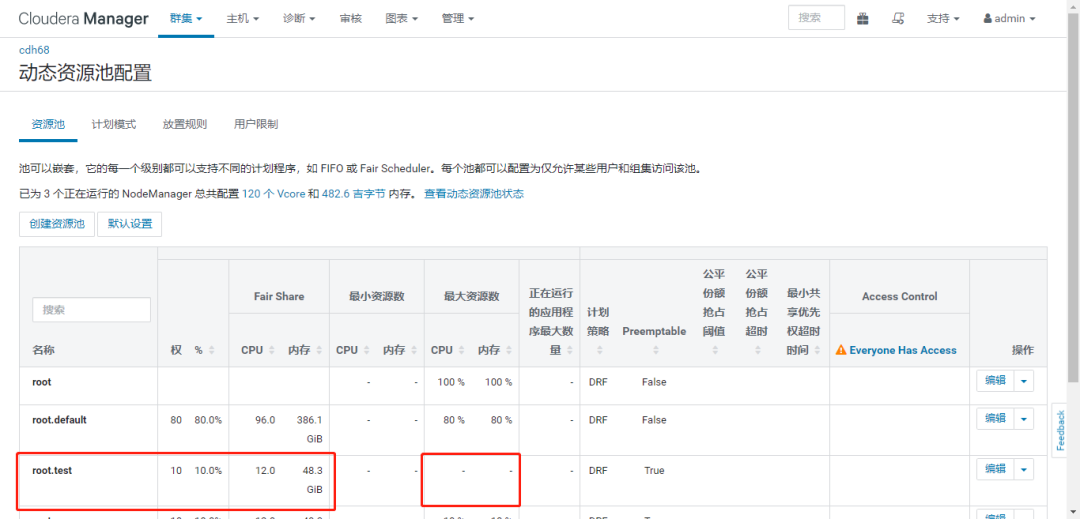
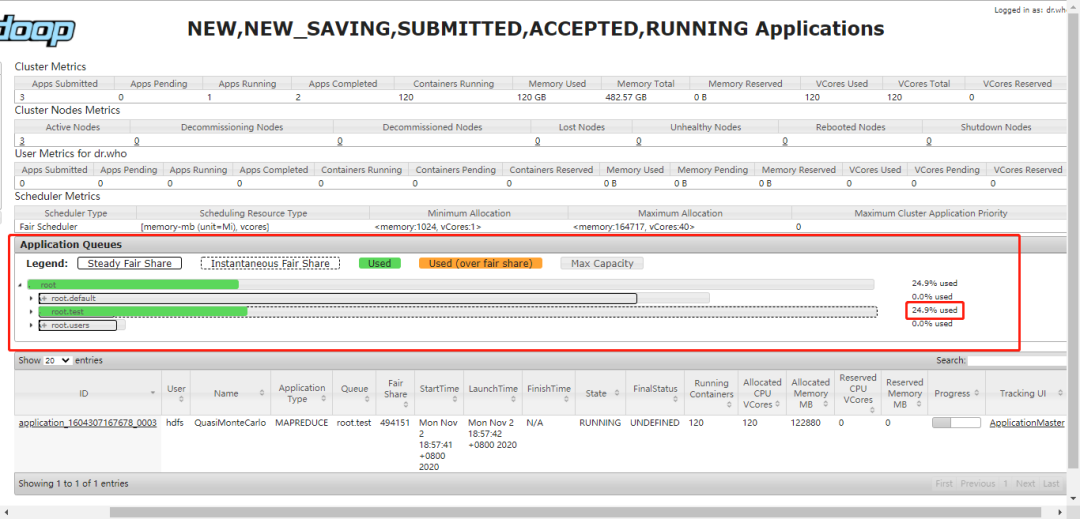

从勾股定理到余弦相似度-程序员的数学基础
大部分程序员由于理工科的背景,有一些高数、线性代数、概率论与数理统计的数学基础。所以当机器学习的热潮来临的时候,都跃跃欲试,对机器学习的算法以及背后的数学思想有比较强烈的探索欲望。 本文的作者就是其中的一位。然而实践的过程中,又发现数学知识的理解深度有些欠缺,在理解一些公式背后的意义时,有些力不从心的感觉。因此梳理了一些数学上的知识盲点,理顺自己的知识脉络,顺便分享给有需要的人。 本文主要讲解余弦相似度的相关知识点。相似度计算用途相当广泛,是搜索引擎、推荐引擎、分类聚类等业务场景的核心点。为了理解清楚余弦相似度的来龙去脉,我将会从最简单的初中数学入手,逐步推导出余弦公式。然后基于余弦公式串讲一些实践的例子。 一、业务背景 通常我们日常开发中,可能会遇到如下的业务场景。 精准营销,图像处理,搜索引擎 这三个看似风马牛不相及的业务场景,其实面临一个共同的问题就是相似度的计算。例如精准营销中的人群扩量涉及用户相似度的计算;图像分类问题涉及图像相似度的计算,搜索引擎涉及查询词和文档的相似度计算。相似度计算中,可能由于《数学之美》的影响,大家最熟悉的应该是余弦相似度。那么余弦相似度是怎么推导出来...