![]()
对于数据开发人员来说,手写sql是比较熟悉的了,就有这样一道题,面试时需要手写sql,这就是非常经典的连续登录问题,大厂小厂都爱问,这种题说简单也不简单,说难也不难,关键是要有思路。
hql统计连续登陆的三天及以上的用户
这个问题可以扩展到很多相似的问题:连续几个月充值会员、连续天数有商品卖出、连续打车、连续逾期。
数据提供
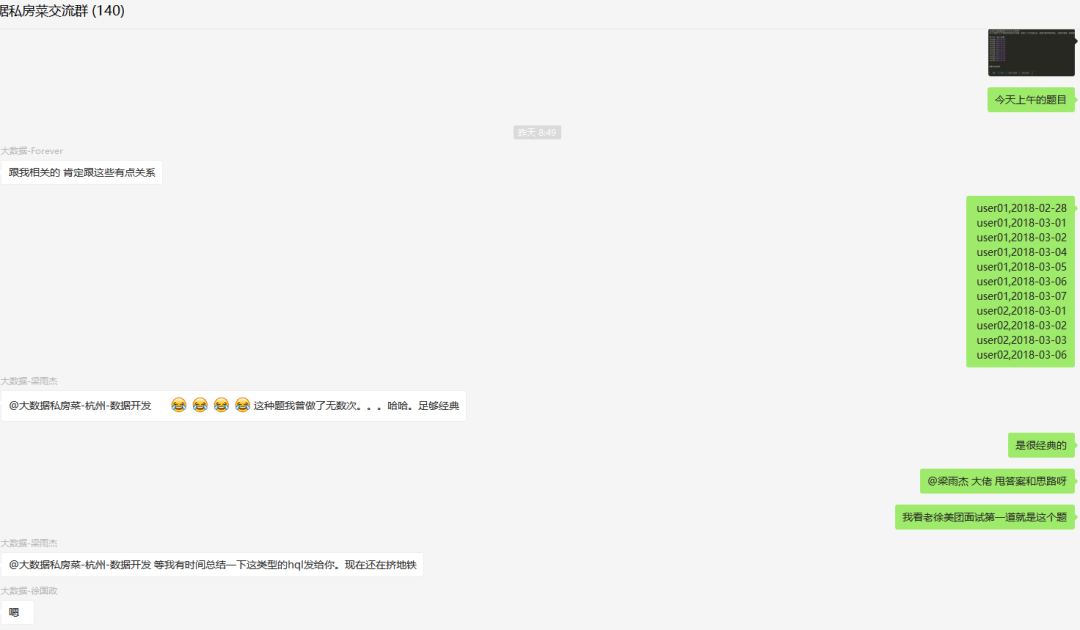
用户ID、登入日期 user01,2018-02-28 user01,2018-03-01 user01,2018-03-02 user01,2018-03-04 user01,2018-03-05 user01,2018-03-06 user01,2018-03-07 user02,2018-03-01 user02,2018-03-02 user02,2018-03-03 user02,2018-03-06
输出字段
+---------+--------+-------------+-------------+--+| uid | times | start_date | end_date |+---------+--------+-------------+-------------+--+
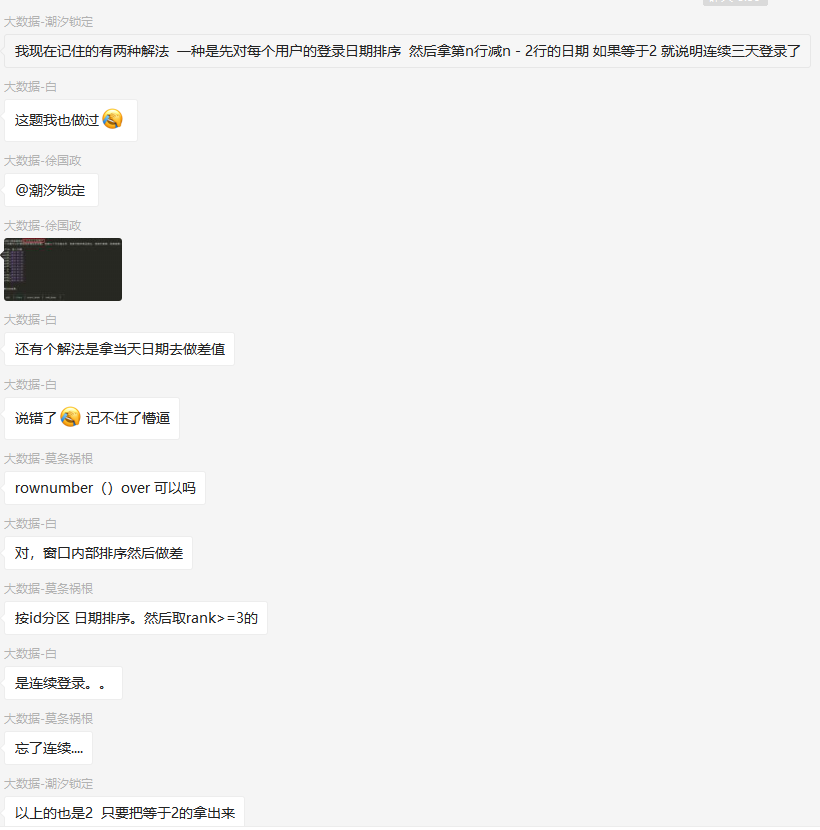
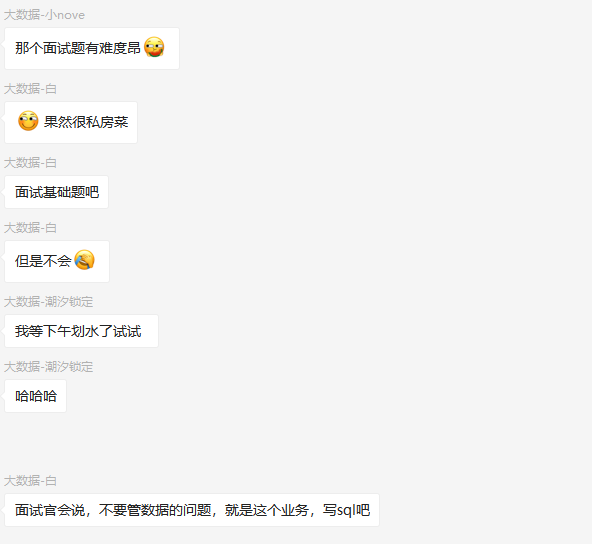
这道题在群里发出后,大家就展开了激烈的讨论:
![]()
![]()
![]()
可以看出来,有很多种不同的解决方案。
这里就为大家提供一种比较常见的方案:
create table wedw_dw.t_login_info( user_id string COMMENT '用户ID',login_date date COMMENT '登录日期')row format delimitedfields terminated by ',';
hdfs dfs -put /test/login.txt /data/hive/test/wedw/dw/t_login_info/
select * from wedw_dw.t_login_info;+----------+-------------+--+| user_id | login_date |+----------+-------------+--+| user01 | 2018-02-28 || user01 | 2018-03-01 || user01 | 2018-03-02 || user01 | 2018-03-04 || user01 | 2018-03-05 || user01 | 2018-03-06 || user01 | 2018-03-07 || user02 | 2018-03-01 || user02 | 2018-03-02 || user02 | 2018-03-03 || user02 | 2018-03-06 |+----------+-------------+--+
select t2.user_id as user_id,count(1) as times,min(t2.login_date) as start_date,max(t2.login_date) as end_datefrom( select t1.user_id ,t1.login_date ,date_sub(t1.login_date,rn) as date_diff from ( select user_id ,login_date ,row_number() over(partition by user_id order by login_date asc) as rn from wedw_dw.t_login_info ) t1) t2group by t2.user_id,t2.date_diffhaving times >= 3;
+----------+--------+-------------+-------------+--+| user_id | times | start_date | end_date |+----------+--------+-------------+-------------+--+| user01 | 3 | 2018-02-28 | 2018-03-02 || user01 | 4 | 2018-03-04 | 2018-03-07 || user02 | 3 | 2018-03-01 | 2018-03-03 |+----------+--------+-------------+-------------+--+
select user_id ,login_date ,row_number() over(partition by user_id order by login_date asc) as rn from wedw_dw.t_login_info
+----------+-------------+-----+--+| user_id | login_date | rn |+----------+-------------+-----+--+| user01 | 2018-02-28 | 1 || user01 | 2018-03-01 | 2 || user01 | 2018-03-02 | 3 || user01 | 2018-03-04 | 4 || user01 | 2018-03-05 | 5 || user01 | 2018-03-06 | 6 || user01 | 2018-03-07 | 7 || user02 | 2018-03-01 | 1 || user02 | 2018-03-02 | 2 || user02 | 2018-03-03 | 3 || user02 | 2018-03-06 | 4 |+----------+-------------+-----+--+
2.用登录日期减去排序数字rn,得到的差值日期如果是相等的,则说明这两天肯定是连续的
select t1.user_id ,t1.login_date ,date_sub(t1.login_date,rn) as date_diff from ( select user_id ,login_date ,row_number() over(partition by user_id order by login_date asc) as rn from wedw_dw.t_login_info ) t1 ;
+----------+-------------+-------------+--+| user_id | login_date | date_diff |+----------+-------------+-------------+--+| user01 | 2018-02-28 | 2018-02-27 || user01 | 2018-03-01 | 2018-02-27 || user01 | 2018-03-02 | 2018-02-27 || user01 | 2018-03-04 | 2018-02-28 || user01 | 2018-03-05 | 2018-02-28 || user01 | 2018-03-06 | 2018-02-28 || user01 | 2018-03-07 | 2018-02-28 || user02 | 2018-03-01 | 2018-02-28 || user02 | 2018-03-02 | 2018-02-28 || user02 | 2018-03-03 | 2018-02-28 || user02 | 2018-03-06 | 2018-03-02 |+----------+-------------+-------------+--+
3.根据user_id和日期差date_diff 分组,最小登录日期即为此次连续登录的开始日期start_date,最大登录日期即为结束日期end_date,登录次数即为分组后的count(1)
select t2.user_id as user_id,count(1) as times,min(t2.login_date) as start_date,max(t2.login_date) as end_datefrom( select t1.user_id ,t1.login_date ,date_sub(t1.login_date,rn) as date_diff from ( select user_id ,login_date ,row_number() over(partition by user_id order by login_date asc) as rn from wedw_dw.t_login_info ) t1) t2group by t2.user_id,t2.date_diffhaving times >= 3;
+----------+--------+-------------+-------------+--+| user_id | times | start_date | end_date |+----------+--------+-------------+-------------+--+| user01 | 3 | 2018-02-28 | 2018-03-02 || user01 | 4 | 2018-03-04 | 2018-03-07 || user02 | 3 | 2018-03-01 | 2018-03-03 |+----------+--------+-------------+-------------+--+
以上仅提供了一种解决方案,小伙伴有其他方案的话,可以进群交流哦
![]()
2020大数据面试题真题总结(附答案)
微信交流群
朋友面试数据研发岗遇到的面试题
clickhouse实践篇-SQL语法
clickhouse实践篇-表引擎
简单聊一聊大数据学习之路
朋友面试数据专家岗遇到的面试题
HADOOP快速入门
数仓工程师的利器-HIVE详解
Hive调优,每一个数据工程师必备技能
OLAP引擎—Kylin介绍
Hbase从入门到入坑
Kafka
Datax-数据抽取同步利器
Spark数据倾斜解决方案
Spark统一内存管理机制
数据治理之数据质量管理
数据治理之元数据管理
数据仓库中的维表和事实表
星型模型和雪花模型
知识点总结——数仓表一览
缓慢变化维常见解决方案
数据仓库是如何分层的?