本章节主要讲解Alertmanager高可用的搭建与配置的详细的内容。
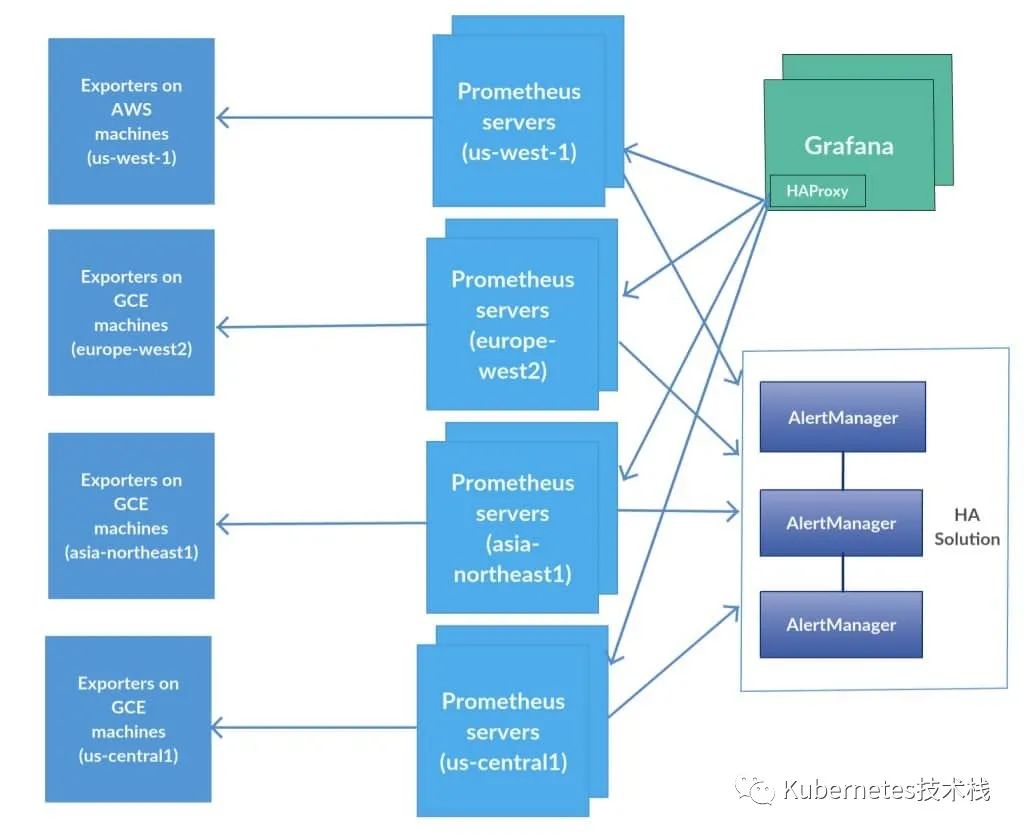
为了提升Prometheus的服务可靠性,我们会部署两个或多个的Prometheus服务,两个Prometheus具有相同的配置(Job配、告警规则、等),当其中一个Down掉了以后,可以保证Prometheus持续可用。
AlertManager自带警报分组机制,即使不同的Prometheus分别发送相同的警报给Alertmanager,Alertmanager也会自动把这些警报合并处理。
| 去重 |
分组 |
路由 |
| Daduplicates |
Groups |
Route |
| 将相同的警报合并成一个 |
根据定义的分组 |
经过路由分发给指定的receiver |
虽然Alertmanager 能够同时处理多个相同的Prometheus的产生的警报,如果部署的Alertmanager是单节点,那就存在明显的的单点故障风险,当Alertmanager节点down机以后,警报功能则不可用。
解决这个问题的方法就是使用传统的HA架构模式,部署Alertmanager多节点。但是由于Alertmanager之间关联存在不能满足HA的需求,因此会导致警报通知被Alertmanager重复发送多次的问题。
![]() alertmanager-ha
alertmanager-ha
Alertmanager为了解决这个问题,引入了Gossip机制,为多个Alertmanager之间提供信息传递机制。确保及时的在多个Alertmanager分别接受到相同的警报信息的情况下,不会发送重复的警报信息给Receiver.
Gossip 机制
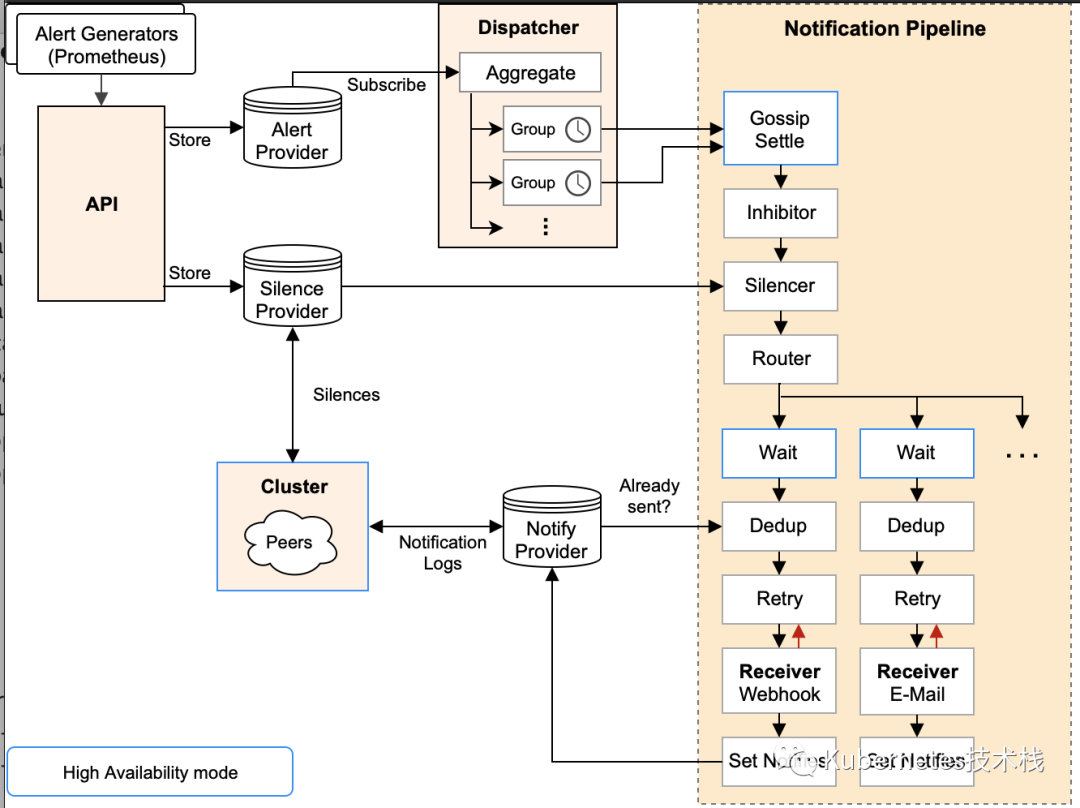
要知道什么是Gossip机制,必须了解清楚Alertmanager中的每一次警报通知是如何产生的,下面一图很详细的阐述了警报个流程:
![]() alertmanager-ha
alertmanager-ha
| 阶段 |
描述 |
Silence |
在这个阶段中Alertmanager会判断当前通知是否匹配任何静默规则;如果没有则进入下一个阶段,否则会中断流程不发送通知。 |
Wait |
Alertmanager 会根据当前集群中所处在的顺序[index],等待 index * 5s 的时间。 |
Dedup |
当等待结束完成,进入 Dedup 阶段,这时会判断当前Alertmanager TSDB中警报是否已经发送,如果发送则中断流程,不发送警报。 |
Send |
如果上面的未发送,则进入 Send 阶段,发送警报通知。 |
Gossip |
警报发送成功以后,进入最后一个阶段 Gossip ,通知其他Alertmanager节点,当前警报已经发送成功。其他Alertmanager节点会保存当前已经发送过的警报记录。 |
Gossip俩个关键:
-
Alertmanager 节点之间的Silence设置相同,这样确保了设置为静默的警报都不会对外发送
-
Alertmanager 节点之间通过Gossip机制同步警报通知状态,并且在流程中标记Wait阶段,保证警报是依次被集群中的Alertmanager节点读取并处理。
搭建本地 Alertmanager 集群
启动Alertmanager集群之前,需要了解一些集群相关的参数
| 参数 |
说明 |
--cluster.listen-address="0.0.0.0:9094" |
集群服务监听端口 |
--cluster.peer |
初始化关联其他节点的监听地址 |
--cluster.advertise-address |
广播地址 |
--cluster.gossip-interval |
集群消息传播时间,默认 200s |
--cluster.probe-interval |
各个节点的探测时间间隔 |
# 直接复制之前已经安装过的Alertmanager文件夹
cp -r alertmanager/ /usr/local/alertmanager01cp -r alertmanager/ /usr/local/alertmanager02cp -r alertmanager/ /usr/local/alertmanager03
# 复制完成以后,写入启动脚本,
# Alertmanager01cat << EOF> /lib/systemd/system/alertmanager01.service[Unit]Description=alertmanagerDocumentation=https://prometheus.io/After=network.targetStartLimitIntervalSec=0
[Service]Type=simpleUser=prometheusExecStart=/usr/local/alertmanager01/bin/alertmanager \--config.file=/usr/local/alertmanager01/conf/alertmanager.yml \--storage.path=/usr/local/alertmanager01/data \--web.listen-address=":19093" \--cluster.listen-address=192.168.1.220:19094 \--log.level=debugRestart=alwaysRestartSec=1
[Install]WantedBy=multi-user.targetEOF
# Alertmanager02
cat << EOF> /lib/systemd/system/alertmanager02.service[Unit]Description=alertmanagerDocumentation=https://prometheus.io/After=network.targetStartLimitIntervalSec=0
[Service]Type=simpleUser=prometheusExecStart=/usr/local/alertmanager02/bin/alertmanager \--config.file=/usr/local/alertmanager02/conf/alertmanager.yml \--storage.path=/usr/local/alertmanager02/data \--web.listen-address=":29093" \--cluster.listen-address=192.168.1.220:29094 \--cluster.peer=192.168.1.220:19094 \--log.level=debugRestart=alwaysRestartSec=1
[Install]WantedBy=multi-user.targetEOF
# Alertmanager03
cat <<EOF > /lib/systemd/system/alertmanager03.service[Unit]Description=alertmanagerDocumentation=https://prometheus.io/After=network.targetStartLimitIntervalSec=0
[Service]Type=simpleUser=prometheusExecStart=/usr/local/alertmanager03/bin/alertmanager \--config.file=/usr/local/alertmanager03/conf/alertmanager.yml \--storage.path=/usr/local/alertmanager03/data \--web.listen-address=":39093" \--cluster.listen-address=192.168.1.220:39094 \--cluster.peer=192.168.1.220:19094 \--log.level=debugRestart=alwaysRestartSec=1
[Install]WantedBy=multi-user.targetEOF
# 开启systemd脚本启动systemctl enable alertmanager01 alertmanager02 alertmanager03systemctl start alertmanager01 alertmanager02 alertmanager03
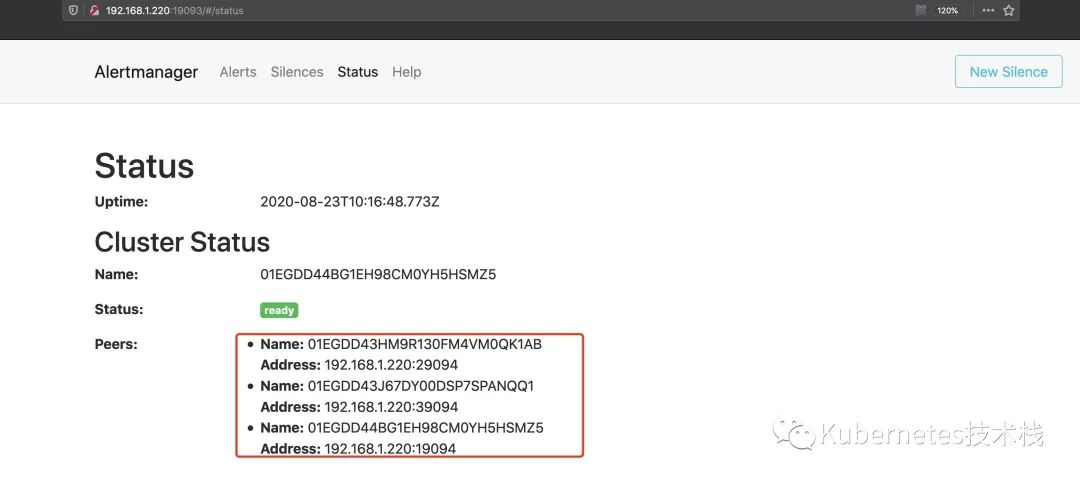
启动完成后,就可以访问http://192.168.1.220:19093可以看到以下集群状态了,我这里是为了测试,本地启动了多个端口,如果是实际生产环境中,是不同节点以及不同的IP,这些根据自己的需求设计即可。
![]() alert-gossip
alert-gossip
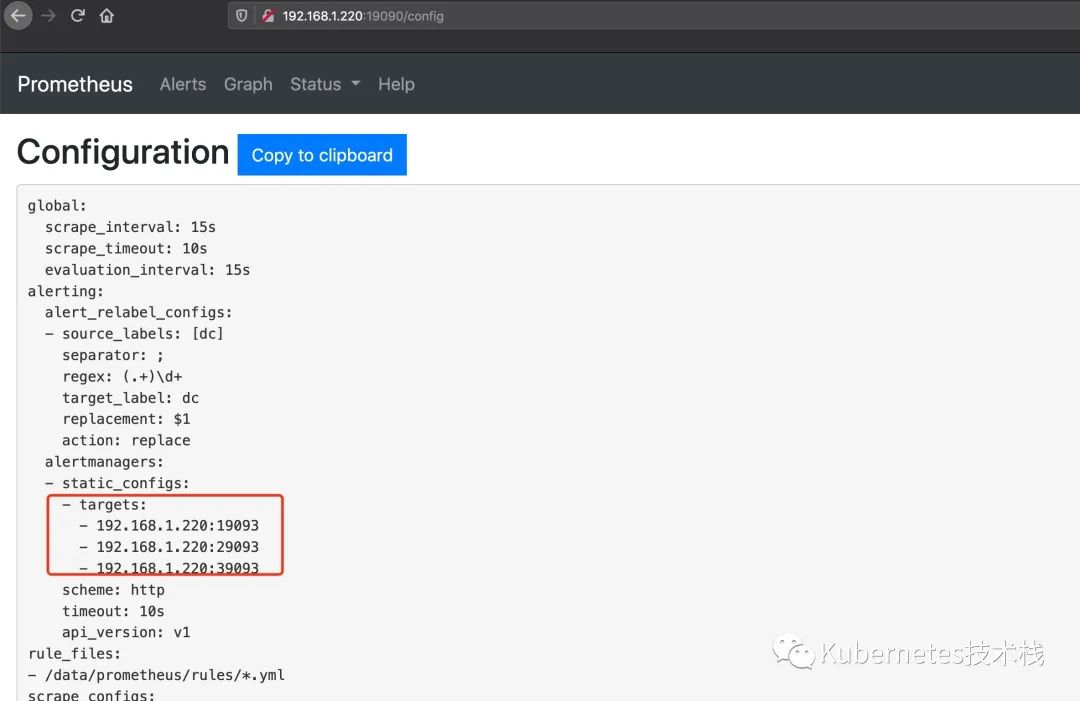
Prometheus中的配置:
alerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: #- targets: ['127.0.0.1:9093'] - targets: ['192.168.1.220:19093','192.168.1.220:29093','192.168.1.220:39093']
配置完成以后,重启或者reloadPrometheus服务,访问http://192.168.1.220:19090/config就可以看到具体的配置信息了。
![]() prom-config
prom-config
到此,Alertmanager集群配置就完成了,对于进群中的警报测试很简单,直接down掉一个端口,然后触发警报,看看警报是否可以正常发送。
![]()