![]()
作者: 凹凸曼 - 朱飞飞
背景
最近在接到一个开发 React 组件库的需求,组件库在开发过程中,刚写完一个组件打算给同事用,同事立马来了个灵魂拷问“啊?这个组件怎么用”。emmm,我寻思直接告诉它下一次又忘了,还是老老实实写个文档吧。
文档写到一半,@#%#¥……#@麻烦死了。这么多组件,每个组件都需要有对应的文档,写起来太耗时了,手写文档比写个组件还麻烦。为了能快点完(xia)成(ban)任(hui)务(jia)。于是研究下那些优秀的组件库到底是怎么做的,看了下Quark夸克组件库的文档生成,大受启发,以下内容是讲讲关于如何优雅地偷懒并把组件文档都做好的。
为什么要自动生成文档
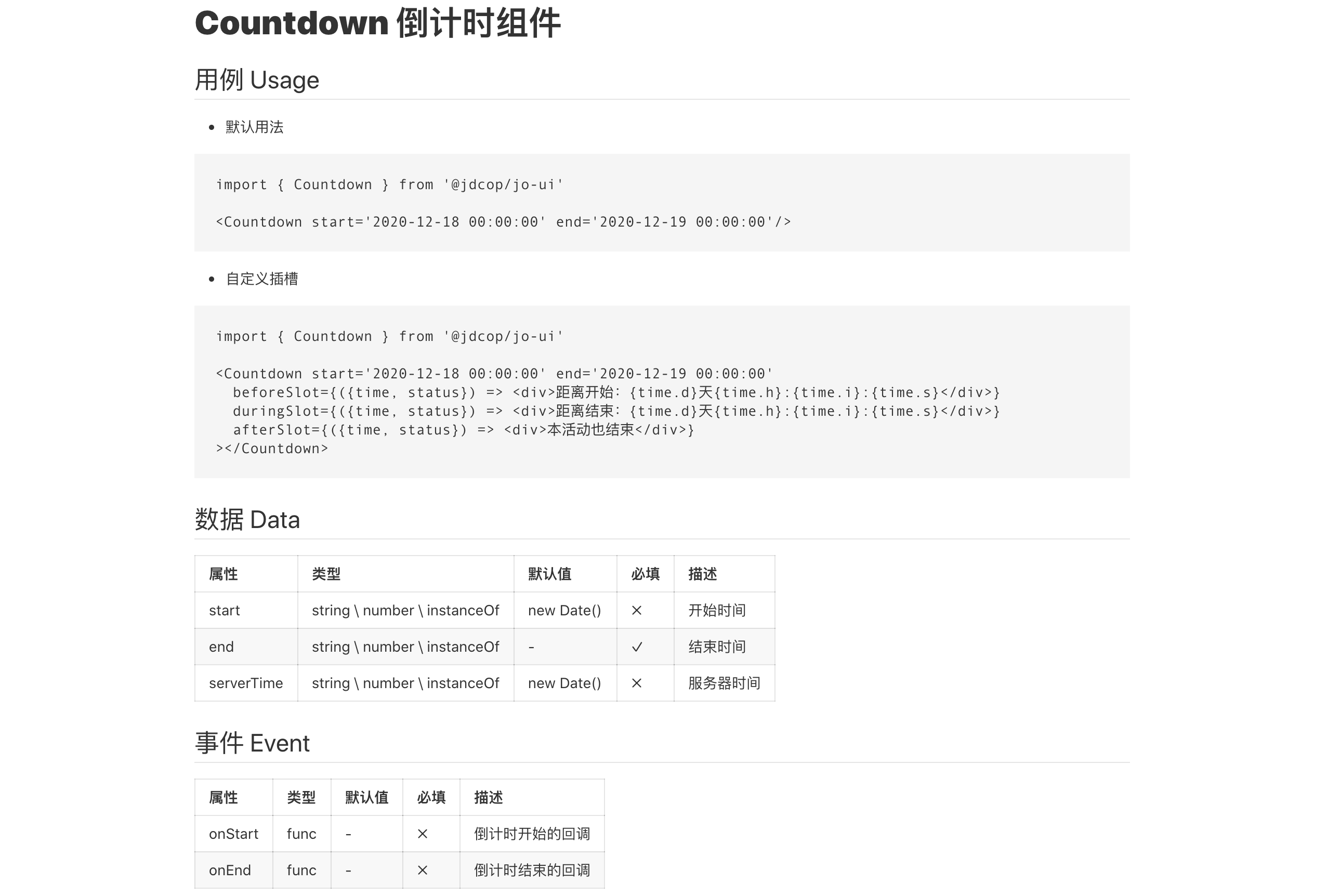
聊这个事情之前,我们先看看文档希望长什么样子
![组件文档]()
组件文档需要什么内容
- 提供组件的介绍说明
- 提供组件的属性列表
propTypes
- 提供组件调用的案例
usage
- 提供组件调用的演示案例/源码
如果要把这些内容都通过 markdown 去写,写完耗费的时间可能比做一个简单的组件还多,为了把更多的精力投入到开发更优质的组件当中,我们需要文档生成自动化。
文档自动化后能为我们带来什么?
- 统一文档格式,抹平不同开发者写文档的格式差异
- 节省写文档的时间来做更多有意(tou)义(lan)的事情
我们拿一个小案例来尝试一下
react-docgen
开始进入正题,先简单介绍下文档自动生成的主角 react-docgen ,官方对于它的介绍是这样的:
react-docgen 是一个 CLI 和工具箱,可帮助从 React 组件中提取信息并从中生成文档。它使用 ast 类型和@ babel / parser 将源解析为 AST,并提供处理此 AST 的方法以提取所需的信息。输出/返回值是一个 JSON blob / JavaScript 对象。
简单来说就是:它能提取组件的相关信息
安装
用 yarn 或 npm 安装模块:
yarn add react-docgen --dev
npm install --save-dev react-docgen
关于它的 API 可以参考官方文档 https://www.npmjs.com/package/react-docgen
偷偷再分享一个高级版的 react-styleguidist https://github.com/styleguidist/react-styleguidist
例子
我们先写一个人物的组件,里面包含 姓名、爱好、事件回调
// ./Persion/index.jsx
import React, { Component } from 'react'
import PropTypes from 'prop-types'
/**
* 人物组件
* @description 这是关于人物组件的描述内容
* @class Persion
* @extends {Component}
*/
class Persion extends Component {
/**
* 处理睡觉的回调
* @param {string} name 姓名
*/
handleSleep = (name) => {
console.log(`${name} 开始睡觉`)
this.props.onSleep()
}
render() {
const { name, hobbies } = this.props
return (
<div onClick={this.handleSleep.bind(this, name)}>
<p>姓名:{name}</p>
<p>爱好:{hobbies.join(',')}</p>
</div>
)
}
}
Persion.propTypes = {
/**
* 姓名
*/
name: PropTypes.string.isRequired,
/**
* 爱好
*/
hobbies: PropTypes.array,
/**
* 睡觉的事件回调
*/
onSleep: PropTypes.func
}
Persion.defaultProps = {
name: '张三',
hobbies: ['睡觉', '打王者']
}
export default Persion
我们定义了一个人物的组件,在组件类注释中描述了组件的基本信息, 同时在propTypes和defaultTypes中也对组件的属性参数进行了定义和属性注释
组件的基本信息都写的差不多了,那么我们先开始使用react-docgen去提取组件的相关信息。
// ./docgen.js
const path = require('path')
const fs = require('fs-extra')
const reactDocs = require('react-docgen')
const prettier = require('prettier')
// 读取文件内容
const content = fs.readFileSync(path.resolve('./Persion/index.jsx'), 'utf-8')
// 提取组件信息
const componentInfo = reactDocs.parse(content)
// 打印信息
console.log(componentInfo)
这里写了一个简单的读取文件和解析的过程,并把提取到的信息打印出来,以下是组件信息提取后的内容 componentInfo
{
"description":"
人物组件
@description 这是关于人物组件的描述内容
@class Persion
@extends {Component}"
,
"displayName":"Persion",
"methods":[
{
"name":"handleSleep",
"docblock":"
处理睡觉的回调
@param name 姓名
",
"modifiers":[
],
"params":[
{
"name":"name",
"description":"姓名",
"type":{
"name":"string"
},
"optional":false
}
],
"returns":null,
"description":"处理睡觉的回调"
}
],
"props":{
"name":{
"type":{
"name":"string"
},
"required":false,
"description":"姓名",
"defaultValue":{
"value":"'张三'",
"computed":false
}
},
"hobbies":{
"type":{
"name":"array"
},
"required":false,
"description":"爱好",
"defaultValue":{
"value":"['睡觉', '打王者']",
"computed":false
}
},
"onSleep":{
"type":{
"name":"func"
},
"required":false,
"description":"睡觉的事件回调"
}
}
}
关于 react-docgen 提取的信息中,解释下下面几个参数
displayName 组件名称description 组件的类注释methods 组件定义的方法props 组件的属性参数
其中这里的props是我们组件文档的核心内容,在提取的内容中,已经涵盖了属性的 属性名、属性描述、类型、默认值、是否必传。这些内容满足我们阅读组件文档所需要的属性信息。
有了所需的componentInfo信息之后,下一步我们需要把它转换成 markdown (至于为什么要用 markdown 我就不解释了 8)
// ./docgen.js
// 生成markdown文档
fs.writeFileSync(path.resolve('./Persion/index.md'), commentToMarkDown(componentInfo))
// 把react-docgen提取的信息转换成markdown格式
function commentToMarkDown(componentInfo) {
let { props } = componentInfo
const markdownInfo = renderMarkDown(props)
// 使用prettier美化格式
const content = prettier.format(markdownInfo, {
parser: 'markdown'
})
return content
}
function renderMarkDown(props) {
return `## 参数 Props
| 属性 | 类型 | 默认值 | 必填 | 描述 |
| --- | --- | --- | --- | ---|
${Object.keys(props)
.map((key) => renderProp(key, props[key]))
.join('')}
`
}
function getType(type) {
const handler = {
enum: (type) =>
type.value.map((item) => item.value.replace(/'/g, '')).join(' \\| '),
union: (type) => type.value.map((item) => item.name).join(' \\| ')
}
if (typeof handler[type.name] === 'function') {
return handler[type.name](type).replace(/\|/g, '')
} else {
return type.name.replace(/\|/g, '')
}
}
// 渲染1行属性
function renderProp(
name,
{ type = { name: '-' }, defaultValue = { value: '-' }, required, description }
) {
return `| ${name} | ${getType(type)} | ${defaultValue.value.replace(
/\|/g,
'<span>|</span>'
)} | ${required ? '✓' : '✗'} | ${description || '-'} |
`
}
上面的转换 markdown 的代码其实做的事情比较少,主要是以下几个步骤
- 遍历
props对象中的每个属性,
- 解析属性
prop,提取属性名、类型、默认值、必填、描述、生成对应的 markdown 表格行。
- 生成 markdown 内容,通过
prettier美化 markdown 代码。
经过转换后最终生成我们这个 markdown 的文件
## 参数 Props
| 属性 | 类型 | 默认值 | 必填 | 描述 |
| ------- | ------ | ------------------ | ---- | -------------- |
| name | string | '张三' | ✗ | 姓名 |
| hobbies | array | ['睡觉', '打王者'] | ✗ | 爱好 |
| onSleep | func | - | ✗ | 睡觉的事件回调 |
拓展优化
这个案例只简单讲述了如何解析props并生成 markdown 的参数 Props模块的流程,在现实项目中,以上流程还有很多可以优化的空间,我们还可以通过很多自定义规则进行各种骚操作。
比如我们不希望把参数的数据属性(name、hobbies)和回调属性(onSleep)都放到同一个 Props 表格中,我们希望可以进行属性上的分类。
在属性描述的注释中,我们可以通过 @xx (或者 ¥%#@^!【】……你喜欢就好)进行不同的描述定义和分类,最终在属性解析的步骤中进行信息的深度的拆分解析分类,生成更加复杂多元的文档。
经过一些改造后,我们通过在注释中添加不同规则的定义描述,得到更优雅美观的文档模块
Persion.propTypes = {
/**
* @text 姓名
* @category data
*/
name: PropTypes.string.isRequired,
/**
* @text 爱好
* @category data
*/
hobbies: PropTypes.array,
/**
* @text 睡觉的事件回调
* @category event
*/
onSleep: PropTypes.func
}
## 数据 Data
| 属性 | 类型 | 默认值 | 必填 | 描述 |
| ------- | ------ | ------------------ | ---- | ---- |
| name | string | '张三' | ✗ | 姓名 |
| hobbies | array | ['睡觉', '打王者'] | ✗ | 爱好 |
## 事件 Event
| 属性 | 类型 | 默认值 | 必填 | 描述 |
| ------- | ---- | ------ | ---- | -------------- |
| onSleep | func | - | ✗ | 睡觉的事件回调 |
当然还有很多比如description或者methods等都可以进行不同的解析并生成对应的markdown模块,数据信息提取出来了,其实最终怎么进行ast解析取决自身的具体业务要求。
小结
在日常开发的过程中,我们除了组件的代码编写外,还有很多流程上、边角上的工作需要做,这些事情往往都比较琐碎又必须要做。我们多借助工具去解决我们的工作中那些零星简单的任务,从而达到高(jiu)效(xiang)完(kuai)成(dian)工(xia)作(ban)的目标。开发者都是懒惰的(可能只有我??),不然怎么会有这么多自动化的产物呢~
参考资料: [1] react-docgen 仓库文档 https://github.com/reactjs/react-docgen#readme
欢迎关注凹凸实验室博客:aotu.io
或者关注凹凸实验室公众号(AOTULabs),不定时推送文章:
![欢迎关注凹凸实验室公众号]()