致谢:
- 非常感谢多个网友的积极参与和反馈,提出这么多的好意见,让sqltoy越来越坚实可靠!
开源地址:
更新内容
1、优化了执行输出,避免存在2次日志输出现象,导致日志分析干扰
2、改进批量操作的日志输出信息,增加了批量执行的记录数量
3、修复特定情况下存储过程调用bug
4、修复报表集成使用sqltoy自身的汇总计算前面的命名空间没有处理的缺陷
5、分页优化代码优化
快速了解 sqltoy-orm:
- sqltoy是全新一代的ORM框架,兼顾jpa对象式操作的优势,同时极大增强了查询功能,辅以科学的sql编写模式、巧妙的缓存翻译集成、极致的分页优化以及针对大规模数据下的分库分表、超复杂场景下的mongodb、elastic、clickhouse组合应用!
- sqltoy给你带来了多种主键策略,除常规的UUID、sequence、identity外,还包含雪花算法和基于redis产生有规则的业务主键等。
- sqltoy还提供了针对统计分析的:数据旋转、无限级分组计算、同比环比等来减少开发者写复杂sql。
- sqltoy在很多方面提供了极为实用的方法,如:树形表处理、isUnique、findTop、getRandomResult、updateFetch等等
- sqltoy不走jooq全对象式、mybatis全sql式这种不是天就是地的极端路子,紧贴项目实战发展起来的框架,让各自技术以合理的方式应用于合理的地方!
简要举例介绍(因篇幅问题部分举例):
- JPA式的CRUD,但规避了其不足,提供了默认的SqlToyCRUDService(简单的则无需写service方法) 和 SqlToyLazyDao(开发无需自己写Dao,只需要写Service业务逻辑),可以了解类似于update、updateAll、saveOrUpdate等内在逻辑,减少了数据库交互,考虑了高并发和业务对象变更的特征!
@Autowired
private SqlToyCRUDService sqlToyCRUDService;
//基于对象保存
sqlToyCRUDService.save(staffInfo);
//基于对象更新(字段值为null的不会参与变更)
sqlToyCRUDService.update(staffInfo);
//深度变更,全部字段都参与变更
sqlToyCRUDService.updateDeeply(staffInfo);
//基于对象更新(制定强制修改的字段)
sqlToyCRUDService.update(staffInfo,new String[]{"staffName","onDuty"});
//基于对象更新
sqlToyCRUDService.saveOrUpdate(staffInfo);
//加载对象
sqlToyCRUDService.load(new StaffInfoVO("S190715009"));
//加锁获取对象
sqlToyCRUDService.load(new StaffInfoVO("S190715009"),LockMode.UPGRADE);
//判断对象是否唯一
sqlToyCRUDService.isUnique(staffInfo, "staffCode");
//delete\deleteAll\updateAll\loadAll 等等不一一写完
//单表对象查询,直接传参模式
List<StaffInfoVO> staffVOs = sqlToyLazyDao.findEntity(StaffInfoVO.class,
EntityQuery.create().where("#[staffName like ?] #[ and status=?]").values("陈", 1).lock(LockMode.UPGRADE)
.orderBy("staffName").orderByDesc("createTime"));
//单表查询,对象传参模式
List<StaffInfoVO> staffVOs = sqlToyLazyDao.findEntity(StaffInfoVO.class,
EntityQuery.create().where("#[staffName like :staffName] #[ and status=:status]")
.values(new StaffInfoVO().setStatus(1).setEmail("test3@aliyun.com")));
//代码中链式查询并删除
Long deleteCount = sqlToyLazyDao.deleteByQuery(StaffInfoVO.class,
EntityQuery.create().where("status=:status").values(new StaffInfoVO().setStatus(1)));
//链式变更
Long updateCount = sqlToyLazyDao.updateByQuery(StaffInfoVO.class,
EntityUpdate.create().set("staffName", "张三").where("staffName like ? and status=?").values("陈", 1));
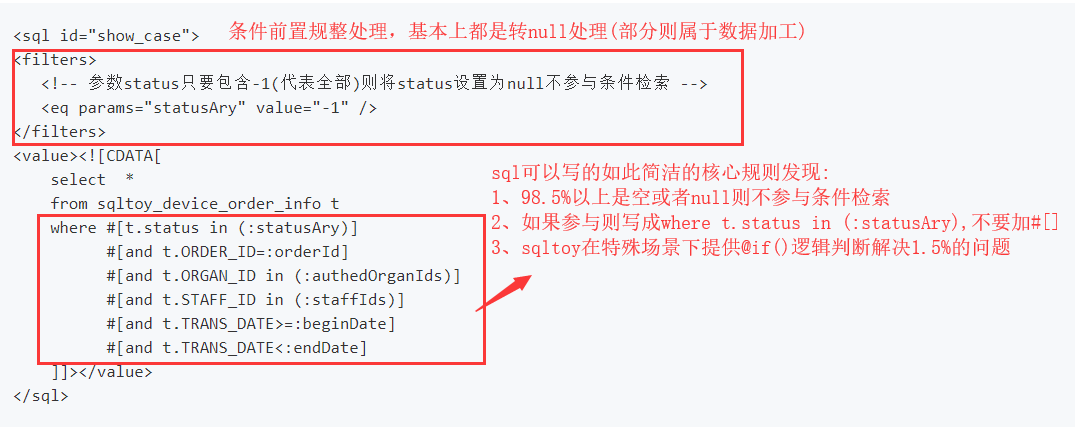
- 更强大的查询,sqltoy强调复杂查询建议放置于xml中跟代码分离(但是可以写在代码中的),不要见xml就反,请深入了解之后再反!
//sqltoy统一的规则就是直接传递sql语句或者对应的sqlId,并不是说sql只能写在xml中(推荐但不绝对)
findBySql(final String sqlOrSqlId, final String[] paramsNamed, final Object[] paramsValue,
final Class<T> voClass)
//嫌弃上面的格式化传参也可以使用这样链式查询
sqlToyLazyDao.findByQuery(new QueryExecutor("sqltoy_order_search").names("orderId", "authedOrganIds")
.values(null, authedOrgans).resultType(DeviceOrderInfoVO.class));
![]()
我们对比一下mybatis的实现(很简单的sql写的如此让人不愿意写!):
![]()
- 缓存翻译,利用缓存减少关联查询,简化sql同时大幅提升效率
![]()
![]()
![]()