GaussDB(for MySQL)数据库在写入性能上,在业界同类产品中是最好的,这主要得益于GaussDB(for MySQL)在MySQL内核方面的诸多优化。其中有一项从“送快递”得来灵感的优化——事务异步提交,值得我们分析。
背景
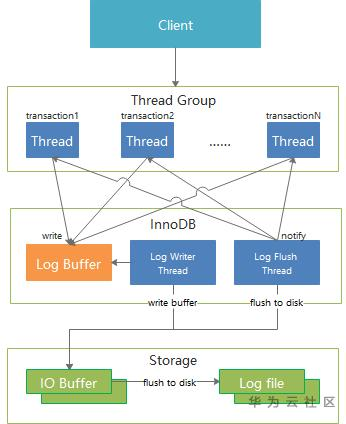
我们先来看看MySQL 8.0的事务提交的大致流程
![]()
图1 MySQL 8.0事务执行流程
以上流程,是MySQL8.0对WAL原则的一种实现,这个流程意味着,任何一个事务的提交,一定要完成write buffer和flush to disk流程。
然而那么这个流程中,有一个问题:每个服务器的CPU是有限的,服务器能处理的Thread也是有上限的,那么当我们的业务的并发数量,远远大于我们服务器能并行处理的数量时,那么后来的事务,只能等待前面的事务提交后才能被处理。在这之前,他们什么也做不了。因此,在大并发场景下,如何进一步提升线程的使用率,是大并发事物写入的一个关键。
灵感来源于生活
一个优化,并不是凭空想象出来的,有时候,往往来源于现实生活。下面,我们先来看看我们身边,和事务提交流程非常类似的一个例子:快递。
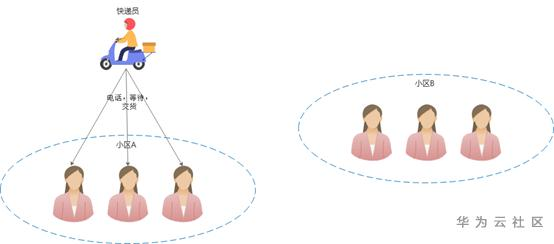
现在的快递配送,一般一个快递员会负责一片区域,快递刚开始兴起时,数量不多,那么一个快递员基本上可以在规定时间内完成配送。
![]()
图2 过去的快递配送
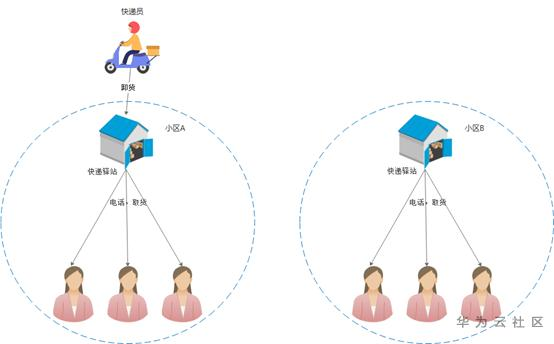
但是,随着快递数量越来越多,一个快递员要在一个小区配送很长的时间,才能到下一个小区,常常导致了快递员无法准时的配送。在这个问题的催动下,随后,一个新的行业开始出现 – 快递驿站。
![]()
图3 现在的快递配送
快递的优化原理
接下来,让我们来看下,快递驿站究竟解决了什么问题。
快递的配送过程中,最耗时的,不是装货,不是卸货,而是电话和等待。配送一个小区的时间,取决于这个最后一个来取快递的人的时间,在最后一个人取完快递钱,快递员除了打电话,做不了其他任何事情(也没有办法通知下一个小区的人,因为最后一个人来取得时间是无法确定的)。那么这个等待的时间,对于快递员来说,就是一种浪费。
快递驿站可以很大程度解决这个问题,快递员到了以后,只需要将快递卸货,即可前往下一个小区,剩下的事情,就可以由驿站的人员来完成,大大提升了快递员的配送效率。
分析
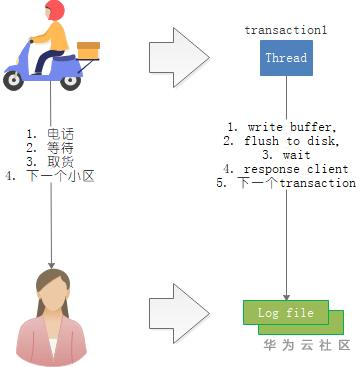
回过头来,我们看看数据库,如果把Transaction线程看做快递员,存储上的文件看做取快递的人,那么我们会发现两者有非常大的相似性。那么我们可以像快递配送优化那样去优化事务的处理流程吗?答案是可以的。
![]()
图4 事务处理和快读配送非常类似
根据快递驿站的优化原理,我们知道,快递驿站帮快递员免去了等待客户取货的时间,那么事务处理过程中,有没有等待的过程呢?答案是有的,存储的IO就是一个较长的等待。数据库使用经验丰富的开发人员来都知道,等待redo日志写入存储的磁盘IO性能,很大程度上决定了数据库的写入性能。对于现代数据库来说,尤其对于GaussDB(for MySQL)这样计算于存储分离的数据库,存储的IO耗时,在事务处理的总耗时中,占据了不小的比例,虽然有log buffer的合并写入,提升并发情况下的整体吞吐,但是如果在等待IO的这段时间中,这些线程能够去做别的事情(例如处理等待中的其他事务)。那么将会有进一步的性能提升。
GaussDB(for MySQL)的优化
既然找到了等待的点,那么我们就可以像快递配送的优化方法,为数据库,也创造一个“快递驿站”,让“快递驿站”来做等待的事情,而事务线程就可以去处理其他等待中的事务,让CPU不会“闲下来”。
![]()
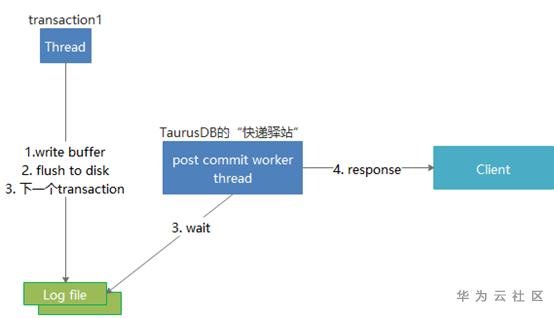
图5 GaussDB(for MySQL)的“快递驿站”
如图5所示,GaussDB(for MySQL)当redo日志的flush to disk动作完成后,即可进行事务提交,但是此时并不应答客户端,而是直接处理下一个事务。同时使用少量”post comit worker线程”,来批量等待日志写入完成(等待的过程其实并不占用CPU),并应答客户端,这就可以让“等待”和“下一个事务的处理”并行化,让CPU“闲不下来”。
实际测试
![]()
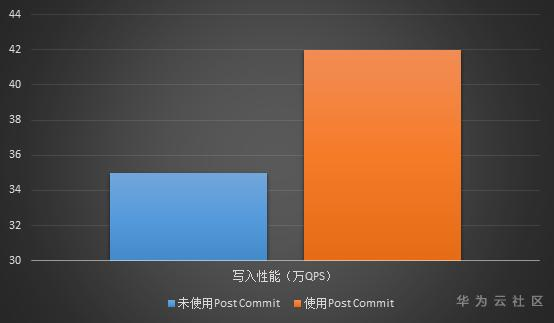
图6 Sysbench write only 模型下写入性能测试
根据实际测试,在标准的sysbench写入模型下,没有使用Post Commit时,极限性能是35万QPS左右,而使用Post commit后,可以到大42万以上的QPS,提升了20%的写入性能。
点击关注,第一时间了解华为云新鲜技术~