1前言
查看华为开发者联盟网站的机器学习服务业务介绍(https://developer.huawei.com/consumer/cn/doc/development/HMS-Guides/ml-introduction-4)
可以看到华为HMS把机器学习服务纳入了文本类,语言类,图片类,人脸人体类四大服务,后面新特性同时不断增加中,其中某些类是文本类服务,文本类服务里面又含了文本识别,文档识别,身份证识别,银行卡识别,通用卡证识别,这些子服务之间都有一些差异和关联呢,可能很多小伙伴会傻傻分不清,今天小编重点剖析下文本类服务,来看下这几个子服务间的差异和关联。
2应用场景差异
首先看下文本类服务包含的子服务内容和对应的场景差异
| 服务 |
场景差异 |
说明 |
| 文字识别 |
稀疏的文本,收据,名片 |
支持的识别范围和场景“广”,啥都能识别,只要是拉丁字符,日韩,中英的文字都可以识别。 |
| 文档识别 |
包含文档的密集文本图片,尺寸文章,合同等 |
需要识别出带一级格式的文本信息,此处需要更多云端的运算能力,有更广泛的语言种类支持能力。 |
| 身份证识别 |
中国大陆二代身份证识别 |
支持的识别范围和场景很“专”,只识别大陆身份证,准确率高。 |
| 银行卡识别 |
全球常见的银行卡(银联,运通,万事达,Visa,JCB)卡号等关键信息识别 |
支持的识别范围和场景很“专”,只识别银行卡,准确率高。 |
| 通用卡证识别 |
任意固定板式的卡证,包括会员卡,通行证,工卡等 |
支持和识别范围和场景介于文本识别和身份证,银行卡识别之间,只要是卡证都可以进行识别。 |
文本类服务SDK有设备端API和云侧API接口两种,设备端的API只在设备端进行处理和分析,使用的是设备自身CPU,GPU等器件的算力,云端的API则需要把数据送到云端,利用云端的服务器资源进行处理和分析,以上服务除文档识别通过计算量吞吐量需要在云端进行处理外,其他服务共用设备端API,本次为了简化分析的范围,我们只讲设备端API服务部分。
2.1场景对比总结
通过以上对比表格我们可以看到,不同能力对应的应用场景是有所不同的:
-
2.1.1文本识别:更像是一个全科考生,上知天文下知地理,只要是文本,都可以识别。
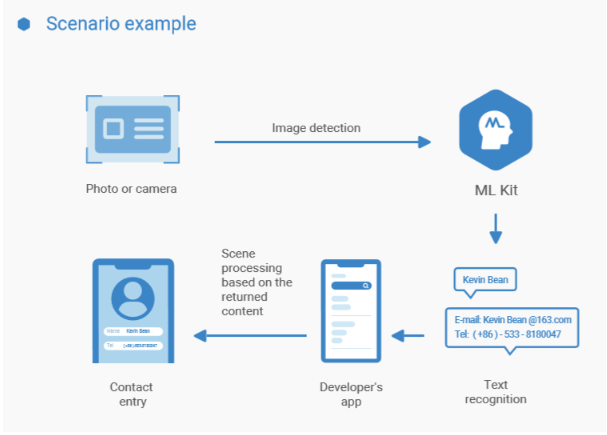
![]()
文本识别使用场景
![]()
文本识别服务本身不提供界面,界面由开发者实现
-
2.1.2身份证识别,银行卡识别:更像是一个偏科生,其他不会,只会成为科,但这一科学的极好。
针对身份证,银行卡提供了更改的定制框,直接对齐框就可以快速进行身份证,银行卡号的提取和识别。
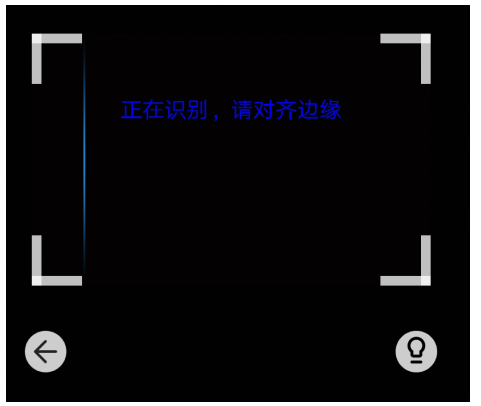
![]()
银行卡识别校准界面
![]()
二代身份证识别校准界面
-
2.1.3通用卡证:则介于以上两类中间,在某些领域有一定的造诣,横向广度和垂直深度都位于中间位置。
可以对所有的卡证进行文本类识别,同时提供了卡证类的对齐框,提示用户对准待识别的卡证。
![]()
通用卡证识别校准界面
2.2该怎么选
很简单,身份证,银行卡识别肯定选身份证识别服务,银行卡识别服务啦,其他卡证类的识别就用通用卡证识别,剩下的场景就用文本识别服务。
3服务集成差异
编译依赖差异
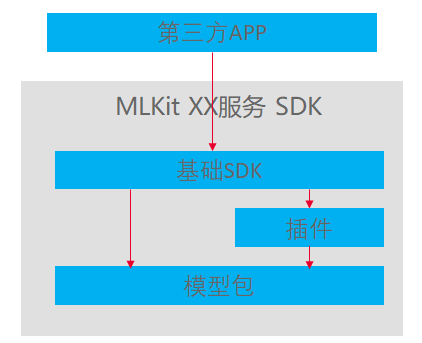
为了便于大家理解,先解释下如下几个概念:
![]()
-
基础SDK
-
相关服务对开发者呈现的接口,所有的API通过基础SDK对外开放
-
插件
-
就是前面场景对比总结中讲到的校准框,提供界面针对图像帧的输入质量做校正,不满足要求的可以提示用户重新放置放。
-
模型包
-
这个是华为HMS ML Kit的各个服务的核心所在,它包含通过机器学习平台输入大量样本进行学习并生成的推理模型文件,以及执行这些推理模型所依赖的轻量化推理框架,承载了所有的图像检测与分析,我面我会在技术差异双向展开分析。
下面小编通过一张表来总结下不同服务对应的编译依赖:
-
| 服务 |
编译依赖 |
示例代码(版本号以官方最新发布为准) |
| 文字识别 |
基础SDK +通用模型包(任选拉丁,日韩,中英) |
//日期基础SDK
实施'com.huawei.hms:ml-computer-vision-ocr:1.0.3.300' // //日期拉丁语文字识别模型包 实现'com.huawei.hms:ml-computer-vision-ocr- latin-model:1.0.3.315' // 约会韩语 文字识别模型包 实现'com.huawei.hms:ml-computer-vision-ocr-jk-model:1.0.3.300' // //中英文文字识别模型包实施'com.huawei.hms:ml-computer-vision-ocr-cn-model:1.0.3.300'
|
| 身份证识别 |
基础SDK +插件(身份证)+专有模型包(身份证) |
//约会基础SDK
实施'com.huawei.hms:ml-computer-vision-icr:1.0.3.300'
//约会识别插件插件包 实现'com.huawei.hms:ml-computer-card-icr-cn -plugin:1.0.3.315' //约会识别模型包 实现'com.huawei.hms:ml-computer-card-icr-cn-model:1.0.3.315'
|
| 银行卡识别 |
基础SDK +插件(银行卡)+专有模型包(银行卡) |
//♡基础SDK
实施'com.huawei.hms:ml-computer-vision-bcr:1.0.3.303' // ♡ 银行卡识别插件包 实现'com.huawei.hms:ml-computer-card-bcr-plugin :1.0.3.300' // 约会 银行卡识别模型包 实现'com.huawei.hms:ml-computer-card-bcr-model:1.0.3.300'
|
| 通用卡证识别 |
基础SDK +插件(通用卡证)+通用模型包(拉丁) |
//日期基础SDK
实施'com.huawei.hms:ml-computer-vision-ocr:1.0.3.300' // //日期拉丁语文字识别模型包 实现'com.huawei.hms:ml-computer-vision-ocr- latin-model:1.0.3.315' // 约会 银行卡识别插件包 实现'com.huawei.hms:ml-computer-card-gcr-plugin:1.0.3.300'
|
编译依赖总结
通过以上编译依赖可以抛光,所有的服务均需要集成对应基础SDK和模型包,但身份证识别,银行卡识别以及通用卡证识别都有对应的插件,也就是前面讲到的校准框。方面,身份证识别和银行卡识别都使用了专有的模型包,而通用卡证识别则使用了通用模型包。
开发差异
先分别看下都是怎么集成的,详细步骤就不在细数了,大家可以直接到开发者联盟上查看对应服务的开发步骤
https://developer.huawei.com/consumer/cn/doc/development/HMS-Guides/ml-introduction-4
在这里简单总结下对应服务的开发步骤:
文字识别
-
创建识别器
MLTextAnalyzer分析器= MLAnalyzerFactory.getInstance()。getLocalTextAnalyzer(setting);
-
创建fram对象,重构图像位图
MLFrame frame = MLFrame.fromBitmap(bitmap);
-
把frame对象传给识别器进行识别
任务<MLText> 任务= analytics.asyncAnalyseFrame (frame);
-
结果处理
任务<MLText> 任务= analytics.asyncAnalyseFrame (frame); task.addOnSuccessListener(new OnSuccessListener <MLText> (){ @ Override public void onSuccess(MLText text){ //识别成功。 } })。addOnFailureListener(new OnFailureListener(){ @ Override public void onFailure(Exception e){ //识别失败。 } });
身份证识别
-
启动界面进行身份证识别
私人无效startCaptureActivity(MLCnIcrCapture.Callback回调,布尔isFront,布尔isRemote)
-
重建回调函数,实现对识别结果的处理
私有MLCnIcrCapture.Callback idCallback = new MLCnIcrCapture.Callback(){ @ Override public void onSuccess(MLCnIcrCaptureResult idCardResult){ //识别成功处理。 } };
银行卡识别
-
启动界面进行银行卡识别
私人无效startCaptureActivity(MLBcrCapture.Callback回调){
-
重建法定函数,实现对识别结果处理
私有MLBcrCapture.Callback回调=新MLBcrCapture.Callback(){ @ Override public void onSuccess(MLBcrCaptureResult bankCardResult){ //识别成功处理。 } };
通用卡证识别
-
启动界面进行通用卡证识别
私有无效的startCaptureActivity(Object object,MLGcrCapture.Callback回调)
-
重建法定函数,实现对识别结果处理
私人MLGcrCapture.Callback回调=新MLGcrCapture.Callback(){ @ Override public int onResult(MLGcrCaptureResult cardResult){
//识别成功处理 返回MLGcrCaptureResult.CAPTURE_STOP; //处理结束,退出识别。 }
};
开发总结
通过以上对比可以发现,除了文本识别不提供界面外,其处理逻辑大同小异,基本都是传要识别的图像给SDK,然后通过通过函数获得识别的结果,这里最核心的差异在于返回内容的结构化数据不同,为了便于理解,小编整理了表格出来:
通过以上分析我们可以得出开发缺点对比:
-
开发杰出对比总结
| 服务 |
开发难度 |
开发说明 |
| 文字识别 |
简单 |
需要开发者获取图片传给SDK,需要对识别后的结果进行信息提取,提取出自己想要的内容 |
| 通用卡证识别 |
很简单 |
直接通过接口即可启动图像获取界面,需要对识别后的结果进行信息提取,提取出自己想要的内容 |
| 身份证识别 |
极简单 |
直接通过接口即可启动图像获取界面,直接通过接口获取已经提取好的文字内容,无需后处理 |
| 银行卡识别 |
极简单 |
直接通过接口即可启动图像获取界面,直接通过接口获取已经提取好的文字内容,无需后处理 |
4技术差异分析
通过以上的差异分析,我们可以看到文本类服务既存在场景,服务集成上的差异,也存在某些关联,某些文本识别和通用卡证识别服务实际上用了相同的通用模型,下面小编前面通过编译依赖分析已经介绍过,文本类服务通常需要集成基础SDK和模型包,有的服务则需要集成插件用于生成校准框,那么模型包又是个什么东西呢?对机器学习有一定了解的小伙伴可能比较清楚,机器学习通常分为收集训练样本,特征捕捉,数据建模,预测等几部分,模型实际上就是机器学习中通过训练样本,特征抽取等动作学习到一个“映射函数”。在华为HMS ML Kit机器学习服务中,仅有这个映射函数还不行,还需要有个东西可以执行它,我们可以推断框架,还有一些算法需要对图像进行前后处理,某些把图像 为了使理解,我们统称以上所有内容为模型文件。为了使这些模型文件可以运行在手机上,还需要对这些模型文件进行优化处理,从而在手机终端上进行优化速度,以及同轴模型文件的大小等等。
差异和关联分析
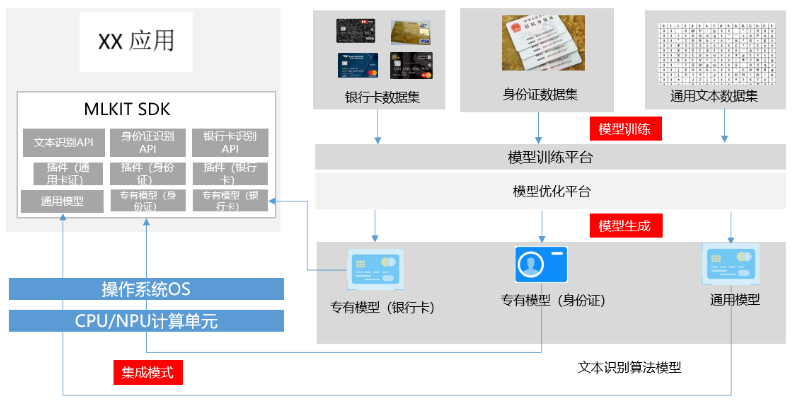
有了以上基础概念介绍,再来看下文本类服各服务间的差异和关联,为了方便理解,小编画了张图,如下所示:
![]()
文本类服务集成模式解析图
文字识别
使用的是通用文本数据集进行的训练,只要是文本都可以识别,他的优点是适用范围广,灵活度高,只要是文字内容,均可以识别。
通用卡证识别
和文本识别采用的数据集是相同的,因此模型文件也不会重复,只是增加了通用卡证插件,主要的作用是确保用户将卡证对准相机正中位置,另外对反光,模糊图像进行识别和过滤,不满足要求提示用户重新调整,这样就可以提高卡证的识别准确率。
身份证&银行卡识别
身份证,银行卡识别服务,采用了身份证,银行卡的专有数据培训集,我们都知道该银行卡上的文字跟普通的印刷体问题有很大的区别,而且存在可能的现象,如果使用通用模型的话,则很难达到非常高的准确率,采用银行卡,身份证专有数据集进行训练,可以让ID,银行卡识别准确率更高,却没有针对身份证,银行卡做了正确性的识别前处理,可以实时动态检测图像质量和倾斜角度,可以生成对准框用于限制卡证的位置摆放,如果模糊,反光和未对准校准框则提示用户重新对准。
5总结
通过以上分析,总结如下:
| 尺寸 |
总结说明 |
| 场景 |
1,文本识别适用范围更广泛,适合任何需要识别文字文本的场景 2,身份证和银行卡识别适用于专门的身份证银行卡识别场景,可以提供超高的识别准确率 3,通用卡证可以适用于所有卡证类的识别场景,并且能够提供相对较高的识别准确率。 |
| 服务集成 |
1,文本类各服务识别内容后返回的结构化数据不同,银行卡,身份证返回的是经过处理后的结构化数据(如卡号,有效期),可供开发者直接获取使用,通用文本和通用卡证则是返回识别到的所有内容,需要开发者通过一定后处理代码做有效信息提取。 2,银行卡,身份证相对通用卡证和文本识别集成开发更加简单 3,文本类各服务需要集成不同的SDK和模型文件 |
| 技术差异 |
1,文本识别和通用卡证识别,使用的是通用模型文件,是通过通用文本数据集进行训练生成的2,银行卡,身份证使用的是专有模型文件,是通过专有的银行卡,身份证数据集训练生成的 |
怎么样,看完这篇文章后,有什么感想,快来发表你的观点吧!
DemoGithub地址:
https://github.com/HMS-MLKit/HUAWEI-HMS-MLKit-Sample
往期链接:
第一期:用华为HMS MLKit SDK三十分钟在安卓上开发一个微笑抓拍神器
https://developer.huawei.com/consumer/cn/forum/topicview?tid=0201198419687680377&fid=18
第二期:安卓开发实战,用华为HMS MLKit图像分割SDK开发一个证件照DIY小程序
https://developer.huawei.com/consumer/cn/forum/topicview?tid=0201203408959360433&fid=18
第三期:安卓开发实战,用HMS MLKit华为机器学习服务开发一个截图翻译小程序
https://developer.huawei.com/consumer/cn/forum/topicview?tid=0201209905778120045&fid=18
第四期:超简单集成华为HMS MLKit机器学习服务银行卡识别SDK,一键实现银行卡绑定
https://developer.huawei.com/consumer/cn/forum/topicview?tid=0201217390745110144&fid=18
第五期:超简单集成华为HMS Core MLKit通用卡证识别SDK,一键实现各种卡绑定
https://developer.huawei.com/consumer/cn/forum/topicview?tid=0201226181206630022&fid=18
第六期:超简单集成HMS ML套件二代身份证识别,一键实名认证
https://developer.huawei.com/consumer/cn/forum/topicview?tid=0201226149614940020&fid=18
下期预告:
基于华为机器学习服务,后面将会有一系列的实战经验分享,大家可以持续关注〜