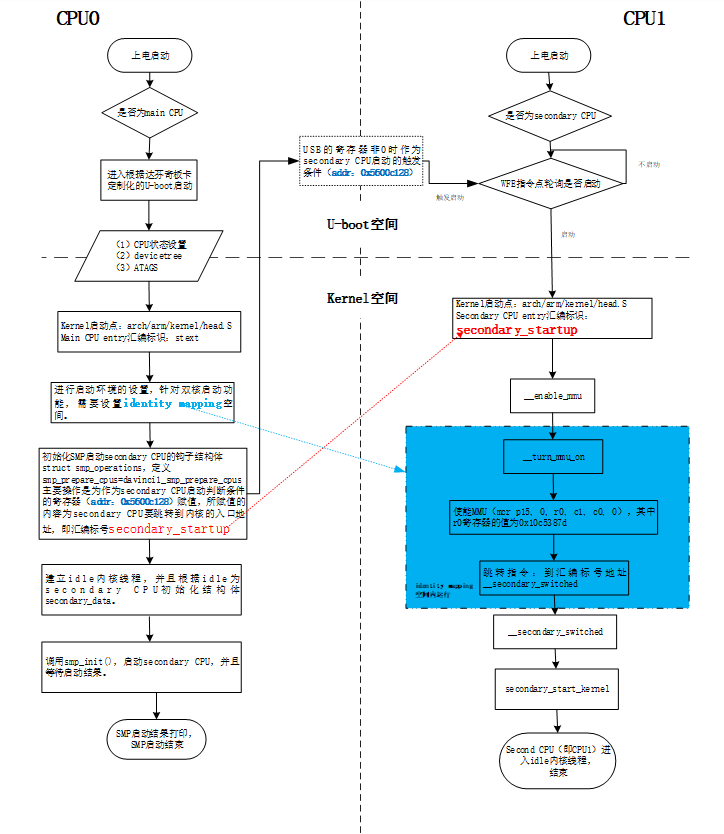
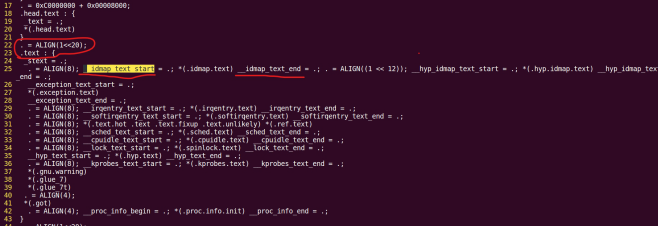
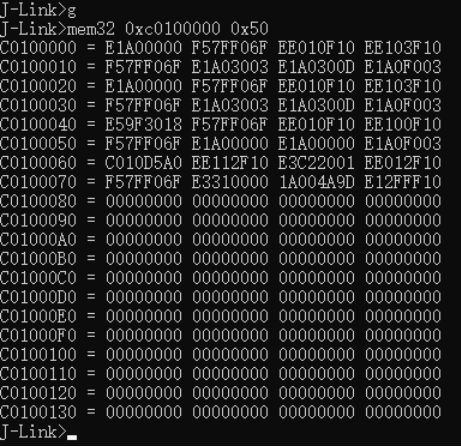
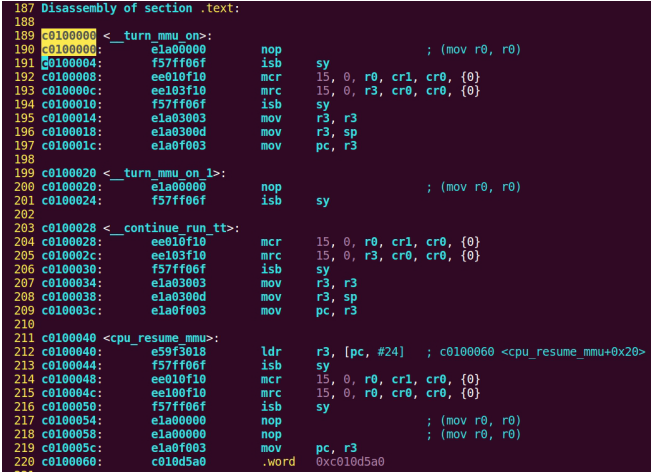
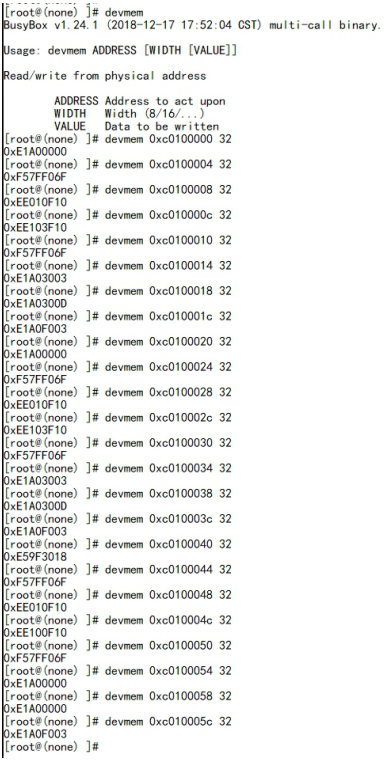
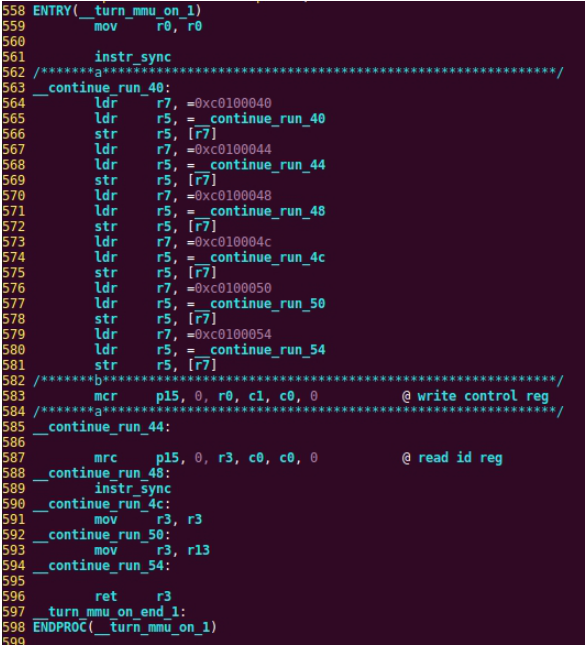
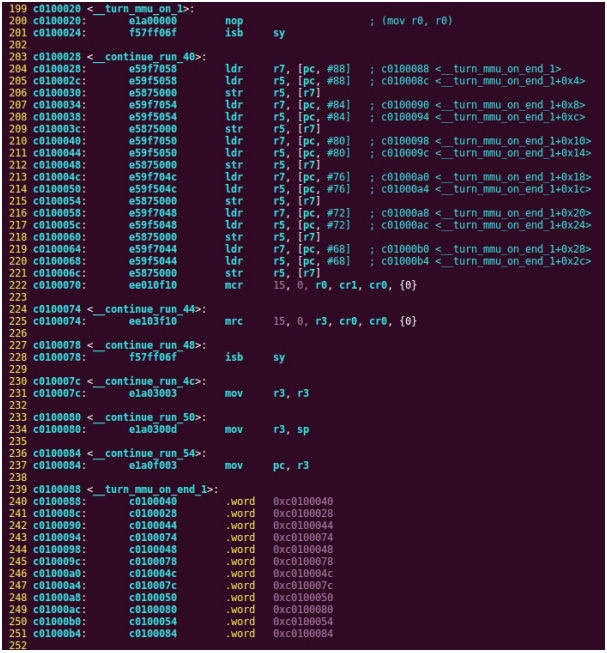
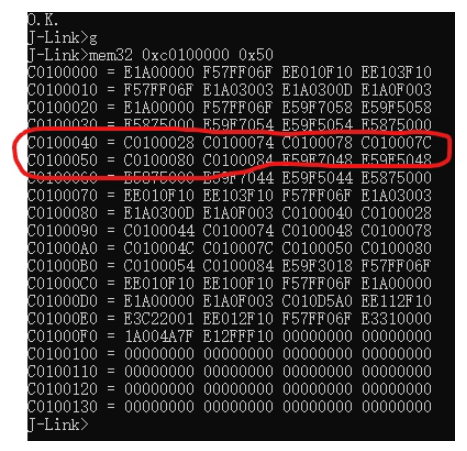
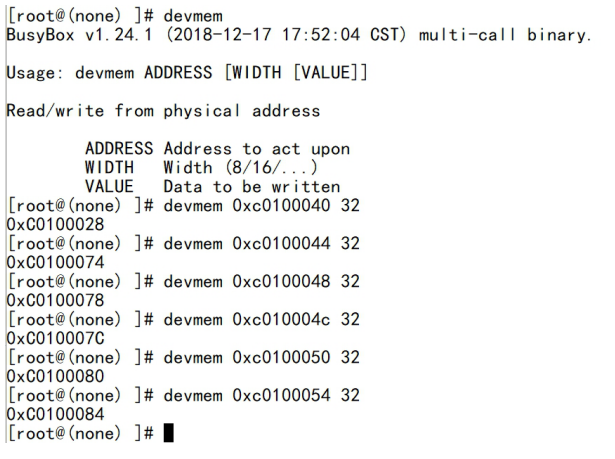
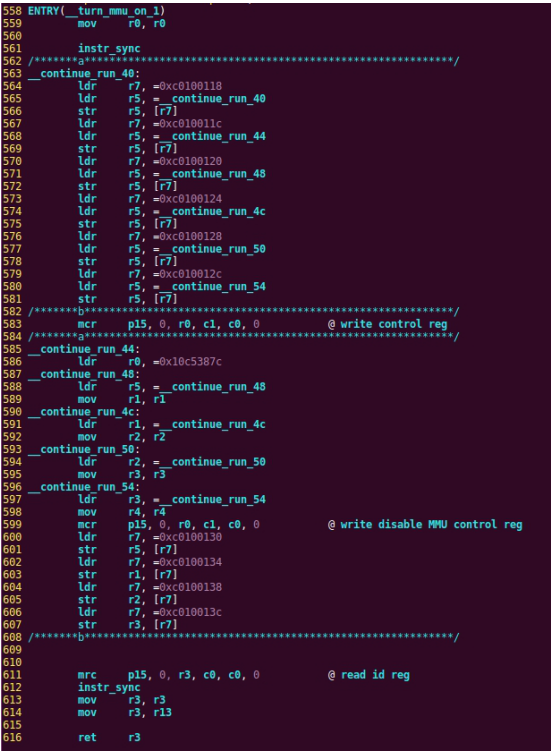
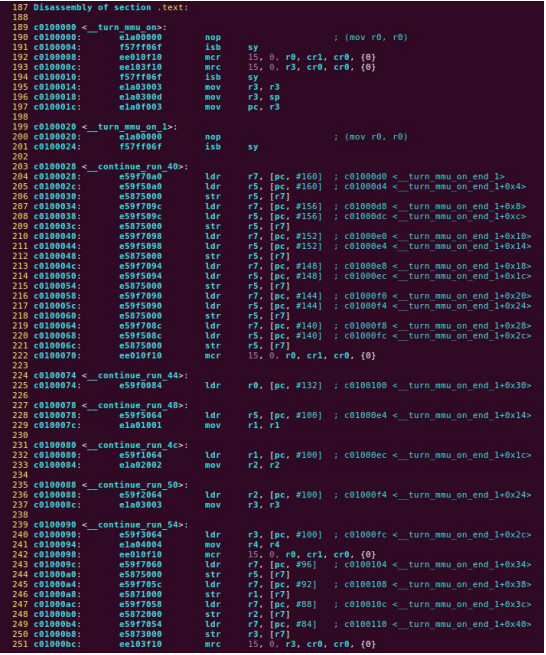
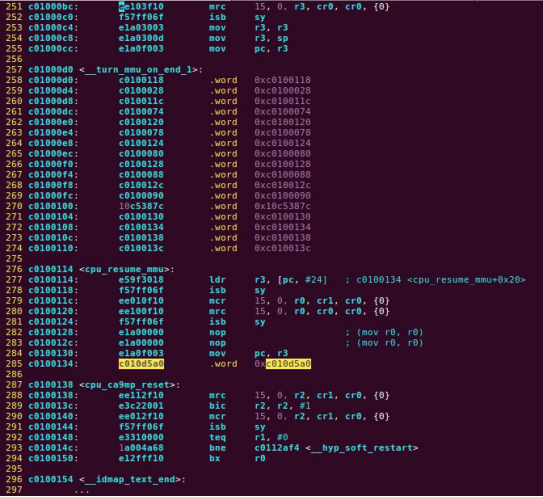
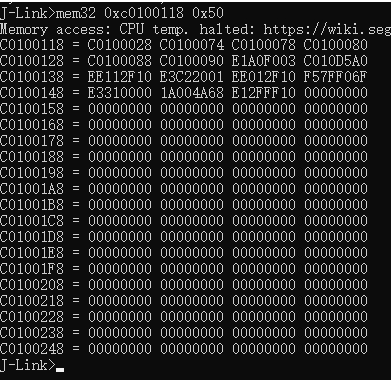
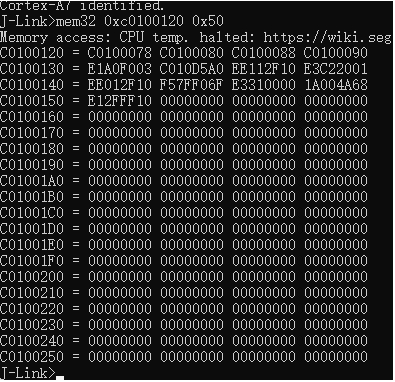
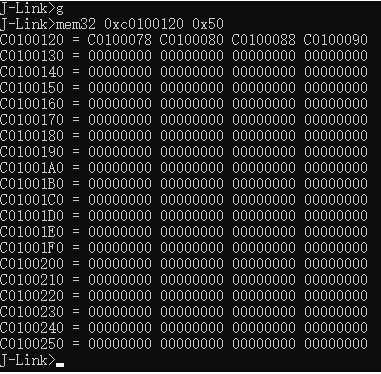
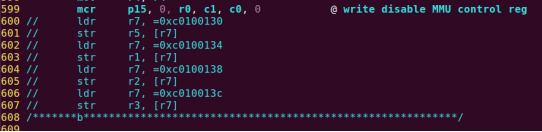
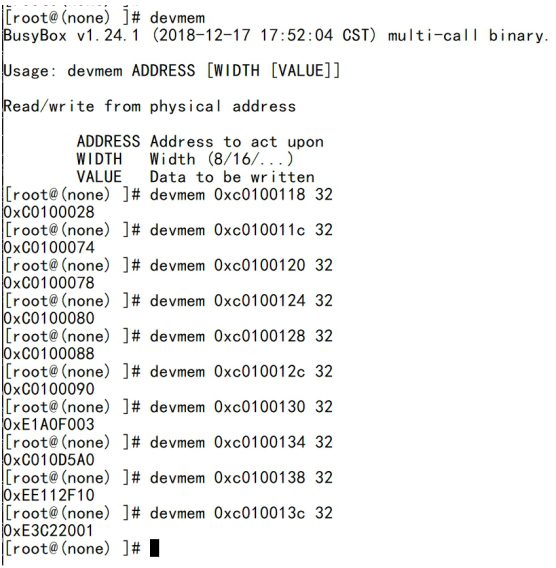
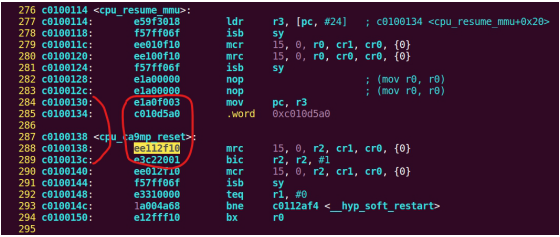
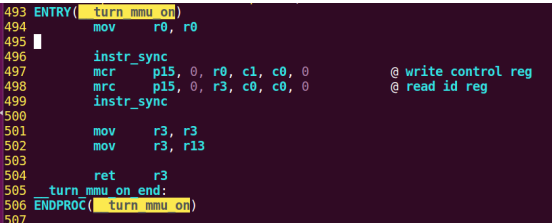
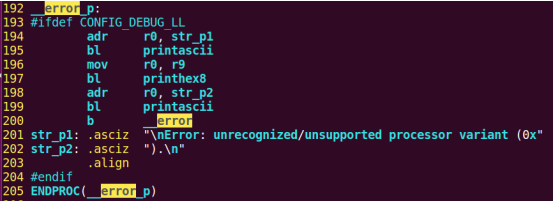
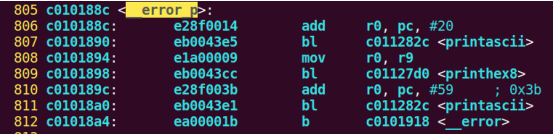
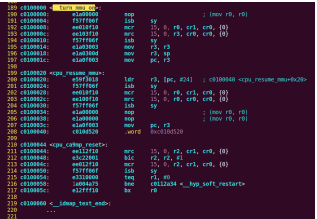
| .text .global __start_ram __start_ram: MRC p15, 0, r0, c0, c0, 5 @ Read MPIDR ANDS r0, r0, #3 cmp r0, #0 beq cpu_0_run b cpu_1_run ldr r0, =0x4000BF00 ldr r1, =0xEEEEEEEE str r1, [r0] ERR_loop: b ERR_loop cpu_0_run: ldr sp, =0x4000B4FF ldr r0, =0x4000BF00 ldr r1, =0x1234abcd str r1, [r0] /* setup page table.*/ ldr r0, =0x40000400 ldr r1, =0x40000c1e str r1, [r0] /* enable mmu.*/ // mov r0, #0 // mcr p15, 0, r0, c7, c1, 0 @ clean ICaches and DCaches // // mcr p15, 0, r0, c7, c10, 4 @ drain write buffer on v4 // // mcr p15, 0, r0, c8, c7, 0 // ldr r5, =0xFFFFFFFF // mcr p15, 0, r5, c3, c0, 0 @ load domain access register // ldr r4, =0x40000000 // mcr p15, 0, r4, c2, c0, 0 @ load page table pointer // mrc p15, 0, r0, c1, c0, 0 // bic r0, r0, #0x3000 // bic r0, r0, #0x0300 // bic r0, r0, #0x0087 // orr r0, r0, #0x0002 // orr r0, r0, #0x0004 // orr r0, r0, #0x1000 orr r0, r0, #0x0001 mcr p15, 0, r0, c1, c0, 0 /* test CPU1 run after open MMU.*/ ldr r0, =0x4000BF30 ldr r1, =0xAAAAAAAA str r1, [r0] ldr r0, =0x4000BF34 ldr r1, =0xBBBBBBBB str r1, [r0] ldr r0, =0x4000BF38 ldr r1, =0xCCCCCCCC str r1, [r0] loop_cpu0: b loop_cpu0 cpu_1_run: ldr sp, =0x4000B8FF ldr r0, =0x4000BF04 ldr r1, =0xabcd1234 str r1, [r0] /* enable mmu.*/ mov r0, r0 mov r0, r0 mov r0, r0 /* setup page table.*/ ldr r0, =0x40000400 ldr r1, =0x40000c1e str r1, [r0] /* enable mmu.*/ // mov r0, #0 // mcr p15, 0, r0, c7, c1, 0 @ clean ICaches and DCaches // // mcr p15, 0, r0, c7, c10, 4 @ drain write buffer on v4 // // mcr p15, 0, r0, c8, c7, 0 ldr r5, =0xFFFFFFFF mcr p15, 0, r5, c3, c0, 0 @ load domain access register ldr r4, =0x40000000 mcr p15, 0, r4, c2, c0, 0 @ load page table pointer mrc p15, 0, r0, c1, c0, 0 // bic r0, r0, #0x3000 // bic r0, r0, #0x0300 // bic r0, r0, #0x0087 // orr r0, r0, #0x0002 // orr r0, r0, #0x0004 // orr r0, r0, #0x1000 orr r0, r0, #0x0001 mcr p15, 0, r0, c1, c0, 0 loop_test_0: /* test CPU1 run after open MMU.*/ ldr r0, =0x4000BF40 ldr r1, =0x33333333 str r1, [r0] ldr r0, =0x4000BF44 ldr r1, =0x55555555 str r1, [r0] ldr r0, =0x4000BF48 ldr r1, =0x77777777 str r1, [r0] b loop_test_0 mov r0, r0 mov r0, r0 mov r0, r0 loop_cpu1: b loop_cpu1 loop: b loop |