SOA思想
1.1 SOA思想介绍
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构件在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
核心概念:面向服务的架构。
特点:
-
分布式的思想 根据业务进行拆分。
-
粗粒度的服务接口分级。
-
标准化的服务接口
-
可从企业外部访问
-
随时可用,可重用的服务
-
松散耦合:服务之间、接口与实现之间、业务组件和传输协议之间
-
支持各种消息模式
-
精确定义的服务契约
1.2将SOA用于开发来说
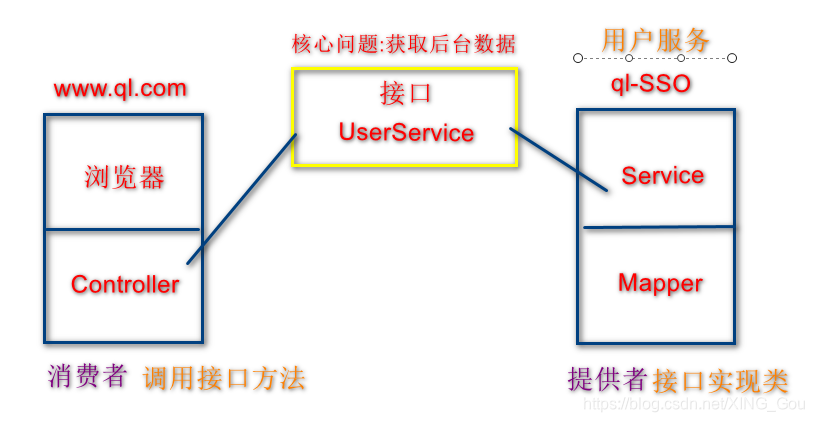
说明:以后的开发中,为了让系统统一的完成调用.则可以采用SOA的方式进行管理。
接口:
-
1.可以是具体的Service接口
-
2.可以具体的url的请求路径
-
但凡前台可以与后台进行交互的都可以称之为接口。
![在这里插入图片描述]()
1.3.对于整个大局来说
1.3.1 企业需求
一个是“信息孤岛”造成基于系统之间互联互通的整合需求;另一个是业务的变化所导致对IT灵活性,以适应变化的需求。
目前国内外基本情况类似,经过30年的信息化建设,许多企业都在不同时期、应用不同技术、与不同的厂商合作,建设了不同规模的应用系统,造成了信息化不是没有系统,而是信息孤岛太多的问题,而且不是没有数据,而是信息不一致,难以整合。因此,互连互通是当前信息化中的核心问题和核心需求。顺便说一句,那些认为中国企业的信息化起步晚,历史负担少,可以快速部署全新SOA,可以运用推倒重来的策略是不了解中国企业信息化,自我想当然的结果。事实上,我国信息化无论是金融、电信、电力等大行业,还是中小工商企业,“孤岛现象”还是非常严重,遗留系统的整合不一定就少,而且我国软件供应商的系统普遍架构能力比较弱,整合难度一点也不低。
这种互联互通需求,既包括企业内的各种应用系统之间的集成,也包括集团企业总部与下属企业、企业与上下游伙伴之间的业务协同。
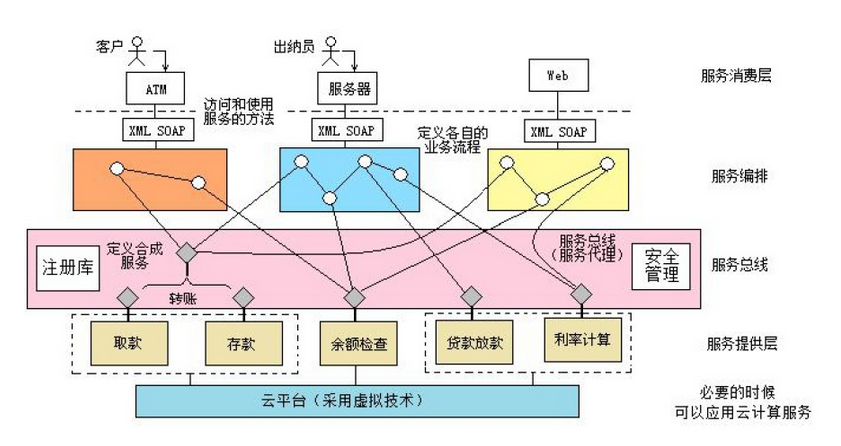
用一个图对大家进行展示SOA基本的面向服务架构: ![]()
技术需要
软件出现最早是用于科学计算,然后是计算机辅助设计、辅助制造等等工业应用。在企业管理领域大规模应用后,业务需求不断的变化、系统不断增加、流程更复杂、系统越来越不堪重负,出现了需求交付方面的重大挑战,以至于人们用“软件危机”来描述软件工业所面临的困境。
软件技术发展过程中,一直在寻求解决四个基本问题的方法:质量问题、效率问题、互操作问题、柔性构造问题。这些问题今天依然困扰着软件行业。
造成这个局面的原因是异构性和标准规范的滞后。
而SOA可以实现:
参考: