本文适合有编程经验的程序员,是一篇机器学习的”Hello world!”,没什么理论知识,在意理论准确性的人请绕道。
前言
人工智能无疑是近年来最火热的技术话题之一,以机器学习为代表的人工智能技术,已经慢慢渗透到我们生活的方方面面,任何事物只要沾上机器学习的边,似乎就变得高大上了。作为处于技术大潮中程序员,我们离机器学习是那么地近,却又
“只在此山中,云深不知处”。
为什么要用Java/Kotlin?
不可否认,Python才是机器学习中的主流语言,但是以我实际的机器学习项目来看,Python适用于算法研究,它的稳定性和生态难以支撑起一个大型的应用,随着Spark、dl4j等一系列java组件的流行,可以预见java将会是大型机器学习应用的主流平台。
由此可知机器学习技术的应用,是Java程序员未来的核心能力之一,但是作为程序员的我们,该如何入门机器学习呢?在此我们先抛开机器学习中那些繁杂的概念,从机器学习中最有代表性的聚类算法开始实践。
没错,我是以Java的名义“骗”你进来的,但我相信Java基础良好的人,阅读以下的Kotlin代码完全没有问题,下面的代码也完全可以翻译成Java代码,这刚好是一个很有意义的练习。本文的示例代码之所以用Kotlin,完全是Kotlin能更简洁地表达我的相法,且与Java的兼容性相当完美。
唯一的背景知识
机器学习有无数分类和具体方法,聚类算法或者再具体点K均值聚类无疑是其中最有代表性的一种无监督学习方法,它像很多普通统计学算法一样简单,却又具备了训练、预测等能力,使用起来与深度学习很接近,是入门机器学习绝好算法。
在此用作者本人的语言通俗易懂地解释一下K均值聚类(k-means):
一种自动的分类算法:将一堆具有相似数值属性的对象集合,归类到K个类别中,通过不断地迭代使类别内的数据具有最大的相似性、类别之间能最大程度地相互区别。
大道至简,通过简单的聚类算法,我们可以:
- 代替人工,对海量的用户数据进行更快速的自动化分类;
- 根据自动聚类结果,发现潜在规律,如:买尿布的奶爸往往会给自己再买几瓶啤酒;
- 通过聚类结果,更快速地对新数据进行归类或预测,比如:以历史数据聚类结果为模型,根据体检身理数据快速预测某人的疾病风险;
- 加速高维数据的查找速度,如:按图片深度特征对图库进行聚类,以便通过分层查找快速从数以亿计的图片中找到相似度最高的商品集(类似百度搜图、淘宝拍立淘)
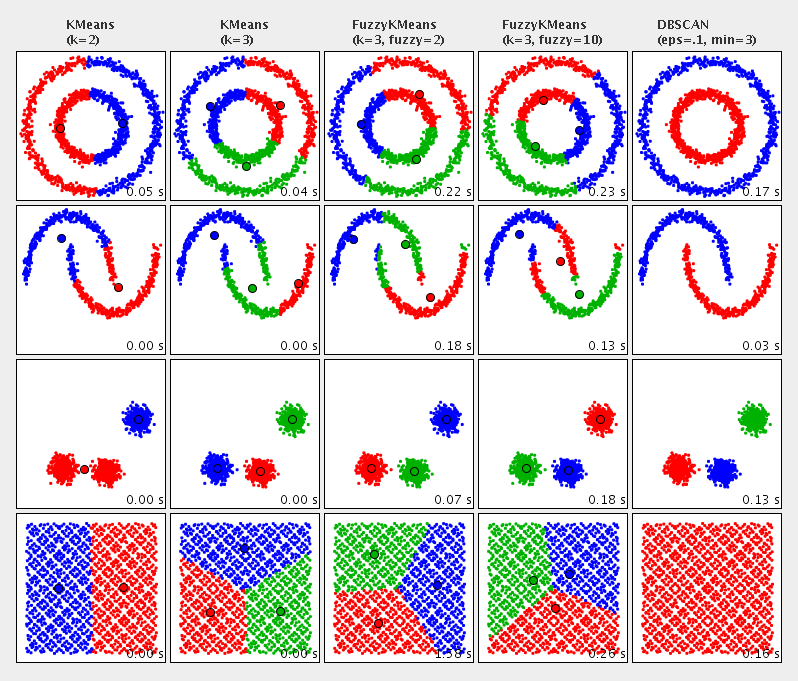
借用Apache Commons Math文档中的聚类算法对比图,来理解下聚类到底是做啥:
![Comparison of clustering algorithms]()
图中用不同颜色表示不同类簇,展示了各种二维数据集聚类后的效果。
动手实践
原始需求:
某司门户网站分为以下栏目:
| 视频 |
文学 |
漫画 |
动画 |
汽车 |
导航 |
杂志 |
邮箱 |
医疗 |
证券 |
新闻 |
钱包 |
商界 |
运营人员整理了本季度2万个用户访问量数据,希望根据这些数据,对本站用户进行画像,并进一步推出有针对性的营销活动,及精准地投递广告。
说明:数据文件为“,”分隔的csv文件,第一列是用户id,后面13列是用户对每个栏目的访问量。
分析步骤:
- 对数进行处理以供分析
- 对处理后的数据进行聚类
- 将聚类类别解读为用户分类画像
- 根据用户分类画像提出有针对性营销活动
- 将有针对性的营销活动推达每个用户
代码实践:
1. 使用Maven创建工程
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.jetbrains.kotlin \
-DarchetypeArtifactId=kotlin-archetype-jvm \
-DarchetypeVersion=1.3.70 \
-DgroupId=org.ctstudio \
-DartifactId=customer-cluster \
-Dversion=1.0
命令执行完成后,用你喜欢的IDE导入maven工程。
2. 添加依赖
我们用到了commons-csv来解析数据,用commons-math3提供的聚类算法,顺便也用到了Kotlin的jdk8扩展特性。在实际使用时,你可以使用自己喜欢的csv组件,绝大部分支持机器学习的组件比如Spark和Mahout都包含了k-means聚类算法,只要掌握了基本用法,很容易按需替换。
<!-- 使用kotlin8的jdk8扩展,主要是简化文件打开代码 -->
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib-jdk8</artifactId>
<version>${kotlin.version}</version>
</dependency>
<!-- 用来导入、导出CSV格式的数据文件 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.6</version>
</dependency>
<!-- 主要用到了其中的聚类算法 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
2. 下载数据
将以下两个文件下载到本地,供代码使用,如放入前述工程的根目录:
3. 编写代码
读取数据并结构化为用户PV列表:
// 定义用户PV实体类,实现Clusterable以便聚类算法使用
// 其中id为第一列用户id,pv为double[]表示用户对各栏目的访问量,clusterId为分类,供保存结果时使用
class UserPV(var id: Int, private val pv: DoubleArray, var clusterId: Int = 0) : Clusterable {
override fun getPoint(): DoubleArray {
return pv
}
override fun toString(): String {
return "{id:$id,point:${point.toList()}}"
}
}
// 使用commons-csv读取数据文件为UserPV列表
fun loadData(filePath: String): List<UserPV> {
val fmt = CSVFormat.EXCEL
FileReader(filePath).use { reader ->
return CSVParser.parse(reader, fmt).records.map {
val uid = it.first().toIntOrNull() ?: 0
val pv = DoubleArray(13) { i ->
it[i + 1]?.toDoubleOrNull() ?: 0.0
}
UserPV(uid, pv)
}
}
}
数据预处理,去掉异常数据,处理记录中的异常值,并将访问量归一化
// 过滤或处理异常数据,实际业务中,可能需要做更多过滤或处理
// 过滤无效的用户id
val filteredData = originData.filter { it.id > 0 }
// 负数的访问量处理为0
filteredData.forEach { it.point.forEachIndexed { i, d -> if (d < 0.0) it.point[i] = 0.0 } }
// 对PV数据归一化
normalize(filteredData)
归一化代码:
fun <T : Clusterable> normalize(points: List<T>, dimension: Int = points.first().point.size) {
val maxAry = DoubleArray(dimension) { Double.NEGATIVE_INFINITY }
val minAry = DoubleArray(dimension) { Double.POSITIVE_INFINITY }
points.forEach {
maxAry.assignEach { index, item -> max(item, it.point[index]) }
minAry.assignEach { index, item -> min(item, it.point[index]) }
}
// 此处用到了Kotlin的操作符重载,封装了对double[]元素的逐个元素操作
val denominator = maxAry - minAry
points.forEach {
// 此处代码逻辑:(x - min)/(max - min)
it.point.assignEach { i, item -> (item - minAry[i]) / denominator[i] }
}
}
所谓归一化,是指通过(value-min)/(max-min)将数据全部转化到0~1的范围之内,以避免因为某个版块的访问量特别大影响聚类效果。
对数据调用聚类算法:
// 创建聚类算法实例,"5"为想要归类的类别数量
// 实际情况下包括k值在内的更多参数需要不断调整、聚类、评估来达到最佳的聚类效果
val kMeans = KMeansPlusPlusClusterer<UserPV>(5)
// 使用算法对处理后的数据进行聚类
val clusters = kMeans.cluster(filteredData)
往往在一开始,我们并不知道数据分多少类是最合适的,此时就需要评估算法来评估不同中心点下的聚类效果。
Calinski-Harabasz是一个很常用的评估算法,基本思想就是类内部越紧凑、类间距离越大,则得分越高。可惜java目前还没有开源的版本,好在我提交给Apache Commons Math的代码,已经被commons-math4接受了,大家尽可期待。此处直接用我已经写好的Kotlin版,你也可以自己实现:
// 创建聚类算法
val kMeans = KMeansPlusPlusClusterer<UserPV>(5)
// 对数据集进行聚类
val clusters = kMeans.cluster(filteredData)
// 创建Calinski-Harabaszy评估算法
val evaluator = CalinskiHarabasz<UserPV>()
// 为刚才的聚类结果评分
val score = evaluator.score(clusters)
有了聚类、评分代码,我们需要动态挑选出最合适的k值即聚类中心数:
val evaluator = CalinskiHarabasz<UserPV>()
var maxScore = 0.0
var bestKMeans: KMeansPlusPlusClusterer<UserPV>? = null
var bestClusters: List<CentroidCluster<UserPV>>? = null
for (k in 2..10) {
val kMeans = KMeansPlusPlusClusterer<UserPV>(k)
val clusters = kMeans.cluster(filteredData)
val score = evaluator.score(clusters)
//挑选出分数最高的聚类簇
if (score > maxScore) {
maxScore = score
bestKMeans = kMeans
bestClusters = clusters
}
println("k=$k,score=$score")
}
//打印最佳的聚类中心数
println("Best k is ${bestKMeans!!.k}")
通过对比多个k值的评分,我们得出将用户分为三类是最合适的,此时我们可以将聚类结果保存下来,估分析解读
// 保存中心点数据
fun saveCenters(
clusters: List<CentroidCluster<UserPV>>,
fileCategories: String,
fileCenters: String
) {
// 从categories.csv中读取版块标题
val categories = readCategories(fileCategories)
// 保存按版块标题与聚类中心点
writeCSV(fileCenters) { printer ->
printer.print("")
printer.printRecord(categories)
for (cluster in clusters) {
//每类用户数
printer.print(cluster.points.size)
//每类访问量均值
printer.printRecord(cluster.center.point.toList())
}
}
}
...
saveCenters(clusters, "categories.csv", "centers.csv")
用户所属分类,通常也需要保存下来,作为以后针对每个用户提供个性化服务的依据:
//保存用户id-类别对应关系到csv文件
fun saveClusters(
clusters: List<CentroidCluster<UserPV>>,
fileClusters: String
) {
writeCSV(fileClusters) { printer ->
var clusterId = 0
clusters.flatMap {
clusterId++
it.points.onEach { p -> p.clusterId = clusterId }
}.sortedBy { it.id }.forEach { printer.printRecord(it.id, it.clusterId) }
}
}
...
saveClusters(clusters, "clusters.csv")
注意此处保存为CSV仅供演示,根据实际业务,你可能需要将用户id-分类对应关系写入数据库。
4. 聚类结果解读
使用Excel打开centers.csv文件,我们可以将每列中的最大值(代表了归一化的每类用户的平均访问量)用背景色标出作为本类用户的特点:
![]()
从以上表格不难看出我们的用户可以分为三类:
- 有7010人喜欢视频、文学、动漫
- 有8151人关注汽车、导航、杂志和邮箱
- 有4839人喜欢医疗、证券、新闻、钱包和商界
如果结合用户的其它注册信息,我们甚至可以给出用户一些较明确的画像,比如结合年龄、性别:喜欢电影和动漫的大学生、关注汽车&时尚的职场人士、关注健康&理财的家庭主妇...
总结
如果你看到这里,会发现上手机器学习也不是那么难,代码运行起来嗖嗖的,也不需要太多框架和组件。如果你的数据够大,比如过亿,也可以期待我正在给Apache Commons Math贡献的小批量k-means聚类算法(将随commons-math4发布),相比换用Spark等这些框架,算法带来的可谓是指数级的性能提升。当然当你的数据大到单机难以承载之时,那些分布式框架还是必不可少的。
想要学好机器学习,掌握理论知识是必不可少的,千里之行,始于足下,让我们先从掌握聚类算法开始,此文之外你还有必要去搜索一些聚类算法的理论知识来加深自己的理解。
下次,我可能要用通俗易懂的方式,给大家讲一些深入(其实也没太深)机器学习的必要前提知识,比如如何从一维空间推导、理解多维空间,方差、欧式距离。当然我是实践高手,但不是理论高手,这些知识,都是为了引出我一个实际AI项目的案例:-)
参考