微盟“删库跑路“事件已经过去好几天了,据悉,微盟的服务已经全部恢复,对于新用户,已经能够正常开始所有相关的业务活动了,但是对于老用户,数据依然没能全部恢复,根据其官网的信息,目前恢复了商家账户和权益数据,截止到2月28日晚上,大约会有七成的数据完成恢复。
作为B端用户以及广大吃瓜群众,都会有这样的好奇,现在的云计算,容器化部署,弹性扩缩容,数据备份技术等技术已经非常先进了,为什么整个恢复周期还会需要这么长时间。那么今天我就从技术的维度来聊聊我的理解。
正式聊技术前,我想先说说今年罗胖的跨年演讲《时间的朋友》,罗胖谈到“躬身入局”让我这个常年和IT技术打交道的”我辈中人“深有感触,很多时候当我们站在局外的时候,感觉很多事情都不复杂,但是当你投入其中之后,就会发现原来我们只是看到了冰山一角,很多事情要远远比你想的要复杂和困难。
![]()
举个很形象例子,人们通常喜欢采摘低垂的果实,因为就大脑的反馈来讲,低垂的果实是很容易采摘的,但是一个果实看起来低,它未必是真的低,很有可能是你离它太远了,当你走进一些,你会发现它比你最初看起来要高,当你再走进一些,你会发现根本高不可及。
这就像一座山,当你离它很远的时候,会觉得山不高,只有当你亲自走到山脚下,才会认识到自己更本不可能爬上去。这里我配了张图,是我当年在珠穆朗玛峰北坡登山大本营的照片,当时的海拔是5300米左右,我的身后就是传说中海拔8848的世界之巅珠穆朗玛峰,你也许看起来觉得似乎不高啊,那是应为我离得还足够远。换句话说,当你觉得一件事情很简单的时候,往往不是真的简单,而很可能是因为你不懂。
![]()
回到这次微盟事件,也是一样的道理,现代的大型互联网产品,无论是toC的还是toB的,站在用户的角度来看,使用都很简单,但是其背后的架构复杂性就是属于冰山下面的部分,其复杂程度会远远超过你的想象,我就常说一句话“认知限制了你的想象力”。所以,我相信,此时此刻,微盟一定在冰山下面尽着自己最大的努力来推动数据早日恢复。
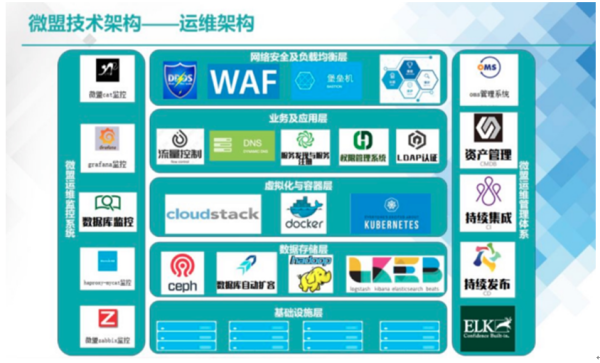
好了,接下来聊聊偏技术的话题。很显然,目前微盟的主要问题是在数据库的恢复上,由于官方并没有公布具体的技术细节,我在网上也只找到一张非常顶层的架构示意图,并没有能获得系统基础架构,尤其是数据库架构方面的详细信息,所以只能从个人经验的角度做一些可能的猜想,目的是想让你能够理解其中的技术复杂程度。
![]()
首先让我们了解一下数据库的运行环境,简化来讲主要有以下三种:
“不上云”:建立在自己的数据中心,完全自己管理硬件、软件和数据,这是云平台普及以前的主流实践。在这种模式下,所有相关的数据库高可用性,容量扩展,数据备份都要有自己非常专业的团队(DBA团队和运维团队)来管理和维护,对企业的技术要求是比较高的。
“全上云”:完全建立在云端环境之上。注意,这里的云可以是公有云,也可以是私有云。云厂商会提供全套的解决方案来支持高可用性,容量扩展和数据备份等特性。可以说,随着云计算的普及以及泛数据库类服务( DBaaS)的快速发展,越来越多的新兴企业会选择这个方案。
“假上云”:这种方案是最奇葩的,有点像用Louis Vuitton的包来装菜,但在行业内也不在少数,应该说这是一个过渡阶段的产物。这种方式就是把云方案当做虚拟机来使用。这种方式和上面的“不上云”很类似,完全没有用好云端的优势,只是把数据中心的机器移到了云端而已。云方案所能提供的容灾、扩容等功能都被阉割了。
对于上面三种方式,“不上云”和“假上云”对于数据的风险相比“全上云”会更大,运维人员在“不上云”和“假上云”的情况下更容易有机会去执行类似“rm -rf /*”和“fdisk”类型的极端操作,而“全上云”,就比较难有机会从操作系统层面执行此类命令,数据库数据也就不会被rm -rf /给删掉。
如果删除操作不是发生在操作系统的数据文件层面(备份通常是以文件形式存在的),那么我们利用数据库自身的特性来恢复误删数据的效率会大大提高。
同样,面对数据的误操作问题(比如,错误地批量update表中数据的某个字段),“全上云”也比“不上云”和“假上云”有明显的优势。这个我是有切身经历的,以前有个项目使用自建数据库,由于某个DBA的误操作,在生产环境的数据库上执行了一条没有加where条件的update语句,直接造成竞拍商品的出价记录字段全部丢失,而后就是艰难的全量回滚和binlog重放,最终耗时4个多小时才恢复。后来同样的误操作发生在了云端数据库,回滚恢复的时间只花了几分钟。
从之前腾讯云对外的回应中,我们可以大概看到微盟被删的数据不在腾讯云上,再结合目前数据恢复的速度来看,我们几乎可以判定很大概率微盟没有采用“全上云”的架构,或者是只有部分数据在云端,而且很可能发生了比较极端的“rm -rf /*”和“fdisk”情况。那么在这种情况下,所有的主从库文件,全量备份文件,增量备份文件以及binlog都一起丢失了。这里的技术挑战主要在于传统IT厂商如何进行磁盘恢复,已经不是任何一个云厂商的技能点所在。
要在这种情况下恢复全部数据,可想而知技术难度是很大的。根据我的粗略理解,至少要跨过下面这些技术的槛。
获取全量备份,如果存在异地的冷备或者灾备,那是比较理想的情况,但是由于全量备份通常非常庞大,所以需要较长的时间完成文件的传输和校验。如果没有异地的全量备份可供使用,那么就必须采取更耗时,而且不能保证一定100%全量成功的磁盘恢复手段。为什么说磁盘恢复会更加耗时,我一会儿来解释。这里还有一个问题就是全量备份可能太“旧”了,这也给后面的恢复带来了更多的时间成本。
获取增量备份,很多时候增量备份没有来得及做异地容灾备份,所以很大概率要从磁盘恢复,这又是大量的时间消耗,而且同样不能保证100%完全恢复。
获取binlog,binlog是记录所有数据库表结构变更(例如CREATE、ALTER TABLE等)以及表数据修改(INSERT、UPDATE、DELETT等)的二进制日志文件,通常以索引文件(后缀为.index)和日志文件(后缀为.00000*)的形式存在磁盘上,通常为了保证binlog记录数据变更的准确性,一般都是采用row格式的binlog,因此文件尺寸也不小,而且文件个数也很多。
有了上面这些作为基本的输入,才能开始数据库层面的数据导入和恢复工作,这个过程也需要花费大量的时间,而且这是基于上述文件都可以100%得到为前提的,如果上述备份文件中出现数据问题,那由此带来的额外时间成本将会变得更大。
最后来说说磁盘文件的恢复。当我们对磁盘等存储介质上的文件进行删除操作,甚至是格式化操作(低级格式化除外)时,磁盘上的数据并没有真正从磁盘上消失,而只是在文件分配表中标注了一下而已,位于数据区的数据本身并没有被立即抹掉。只要文件的数据区没有被后面写入的信息覆盖,那么这些被删除的文件就是可以恢复的,这就是磁盘文件在删除后可以恢复的理论基础。
但是数据库的数据文件和备份文件往往很大,那么只要有个别数据区出现了重写,那么恢复出来的文件就是不完整的,这个时候就需要人为介入来进行修正,这个工作量以及技术难度就会很大,有时还会需要借助专用的仪器设备。在更复杂的情况下,还会采用数据雕刻技术(File Carving),数据雕刻技术是数字取证研究中频繁使用的一种文件恢复技术,它从表面上无差别的二进制数据集即原始磁盘映象中提取文件,而不利用磁盘的文件系统类型。
除此之外,像微盟如此庞大的系统,各个垂直事业部可能都有各自的业务数据库,这些数据库甚至可能采用了不同的方案,这种架构上的异构性也会给恢复过程带来极大的挑战。另外,即使部分数据恢复完成之后,也不能立即上线,而要等其他相关数据恢复,并且做好数据的的交叉校验,确保数据的万无一失,这些都需要大量的时间。
这些只是我能想到的一些情况,我站的也很远,也是从旁观者的维度在看问题,所以,我相信实际情况会比我所描述的更为复杂。我们还没法对最终的恢复结果作出推断,能够做的只有等待。