软件业有如时尚业,新产品,新技术,新概念层出不穷,作为码农,如果不了解业内最新的技术动向,往往会陷入闭门造车的困境。睁眼看世界对于我们的产品开发和设计都是非常有意的一件事情。但是如今,各种会议层出不穷,会议质量良莠不齐,或者很多我想参加的会议发生在离我十万八千里的美洲,欧洲,非洲,南极洲,作为码农的我们既没钱,又没时间去参加这些会议。不要担心,刚哥这里会找一些顶级会议的内容,分享给大家,能让大家坐在家里,也依然能够领略这些顶级会议的精彩内容。
![]()
今天我要带给大家的是2018年底,在西雅图举办的Kubecon的一场分享,来自谷歌K8s团队的工程师Saad Ali分享的《Kubernetes设计原则》。这场会议虽然已经过去一年了,但是我觉得本会议的内容非常值得学习,我们大都知道K8s是如何工作的,但是本文带我们了解k8s背后的设计原则,以及为什么要这样设计。以下是该分享的摘要:
Kubernetes设计原则:了解原因
Kubecon西雅图2018
对于跨云和本地环境在分布式系统上管理和部署工作负载,Kubernetes很快变得不可或缺。
虽然现在大多数人都熟悉如何使用Kubernetes,但很少有人知道其背后的“为什么”?为什么Kubernetes API看起来是这样的?为什么Kubernetes组件仅通过Kubernetes API相互交互?当您可以轻松地直接从pod引用卷时,为什么会有PersistentVolumeClaim对象?
为了回答这些问题并帮助您对Kubernetes进行更深入的了解,本讲座将揭示支撑Kubernetes设计的原理。
原则1. Kubernetes APIs 是声明性的而非命令性的
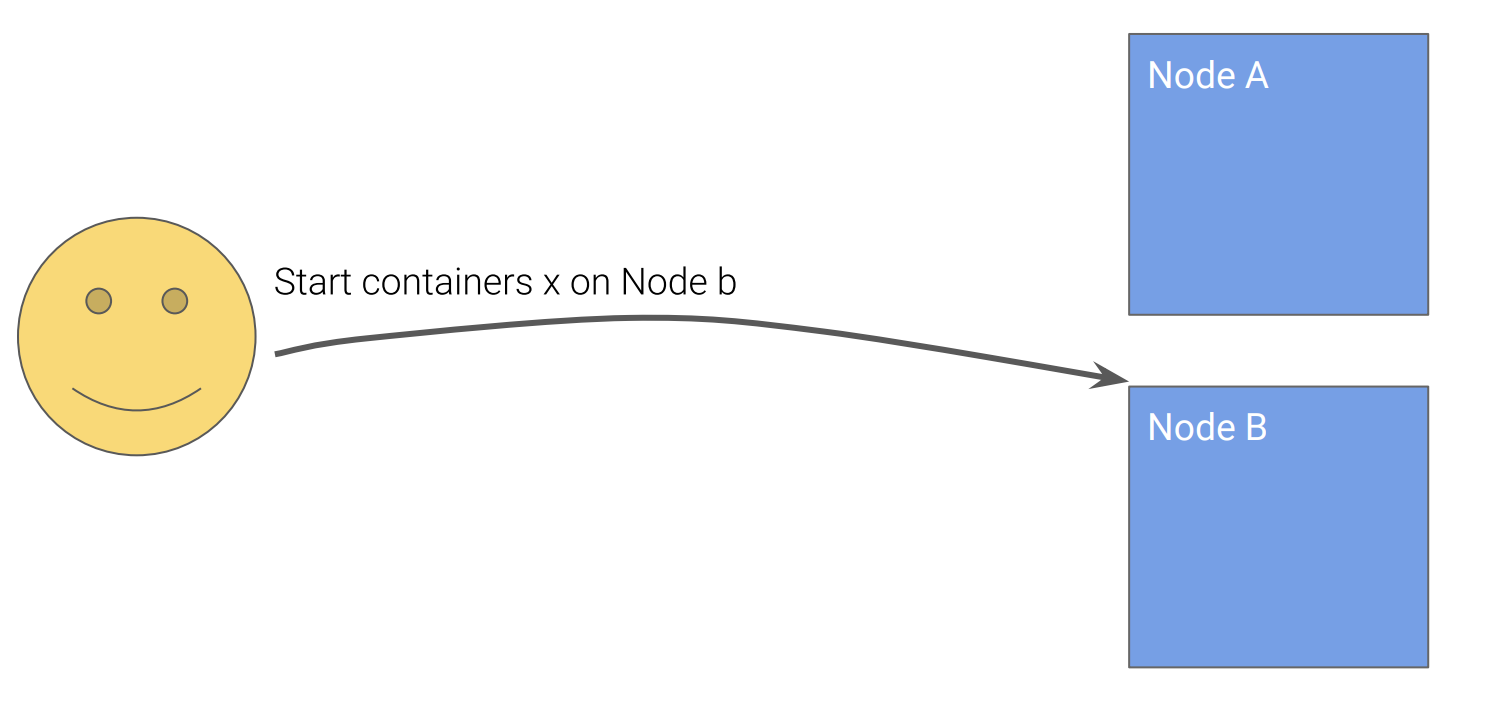
我们从最简单的一个例子开始,要如何在一台节点上启动需要运行的任务。
![]()
最简单的方式就是发送一个命令,启动容器。
![]()
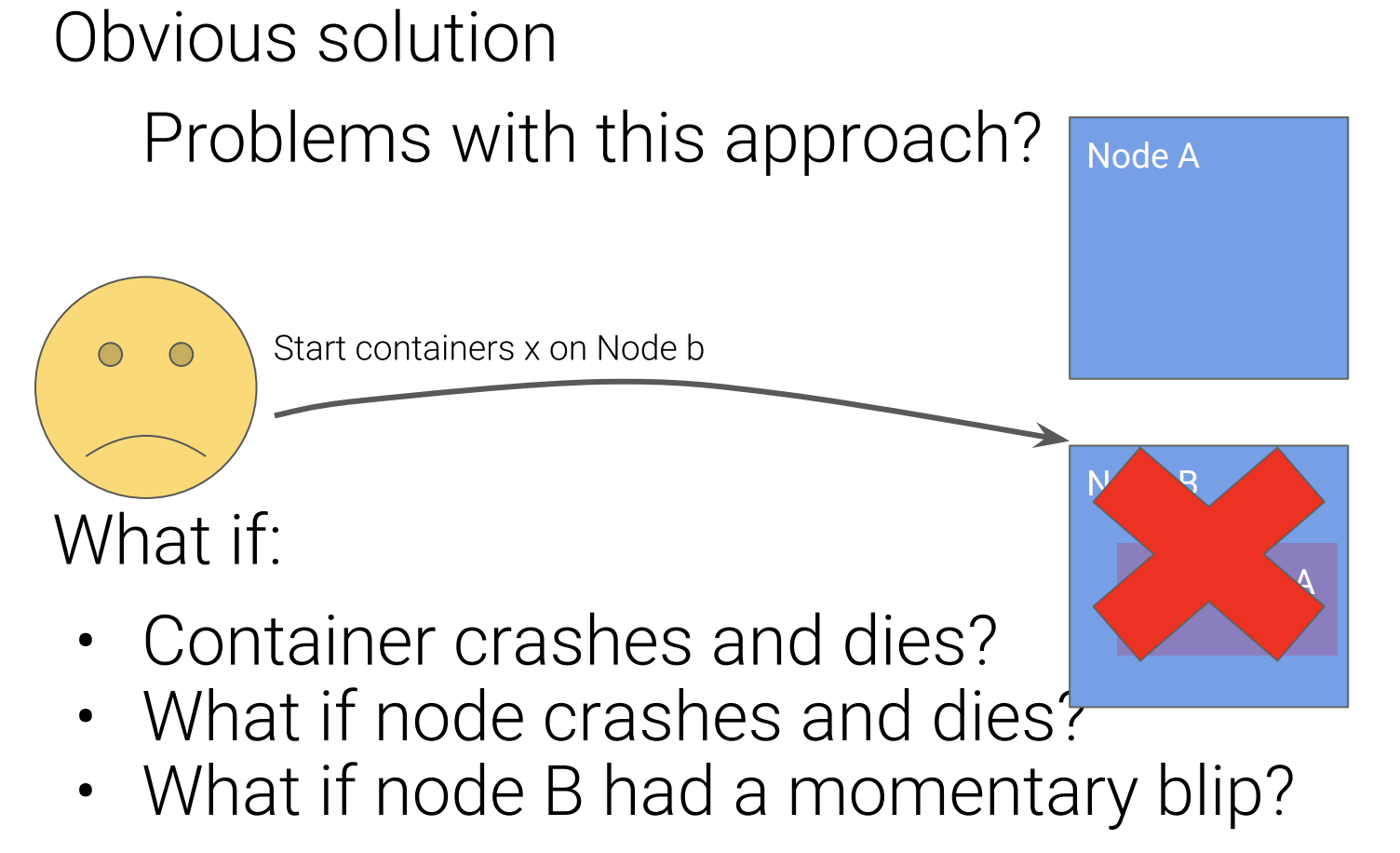
但是这样做的话,如果容器,节点崩溃,或者节点临时不可访问的时候,用户就必须监控和存储每一个节点和容器的状态,捕获所有的异常,并做异常处理。也就是说把所有的复杂的异常处理的逻辑交给客户端来做。
这就引入了Kubernetes的第一个设计原则:
Kubernetes APIs 是声明性的而非命令性的 ( Kubernetes APIs are declarative rather then imperative )
命令式:
- 用户:提供一系列的指令来驱动系统达到制定状态。
- 系统:执行指令
- 用户:监控系统,根据系统状态,提供进一步的指令
声明式:
下图是一个声明式API的例子:
- 用户创建一个API对象
![]()
- 所用的组件并行工作来达到该状态。
![]()
声明式的API支持自动恢复。例如
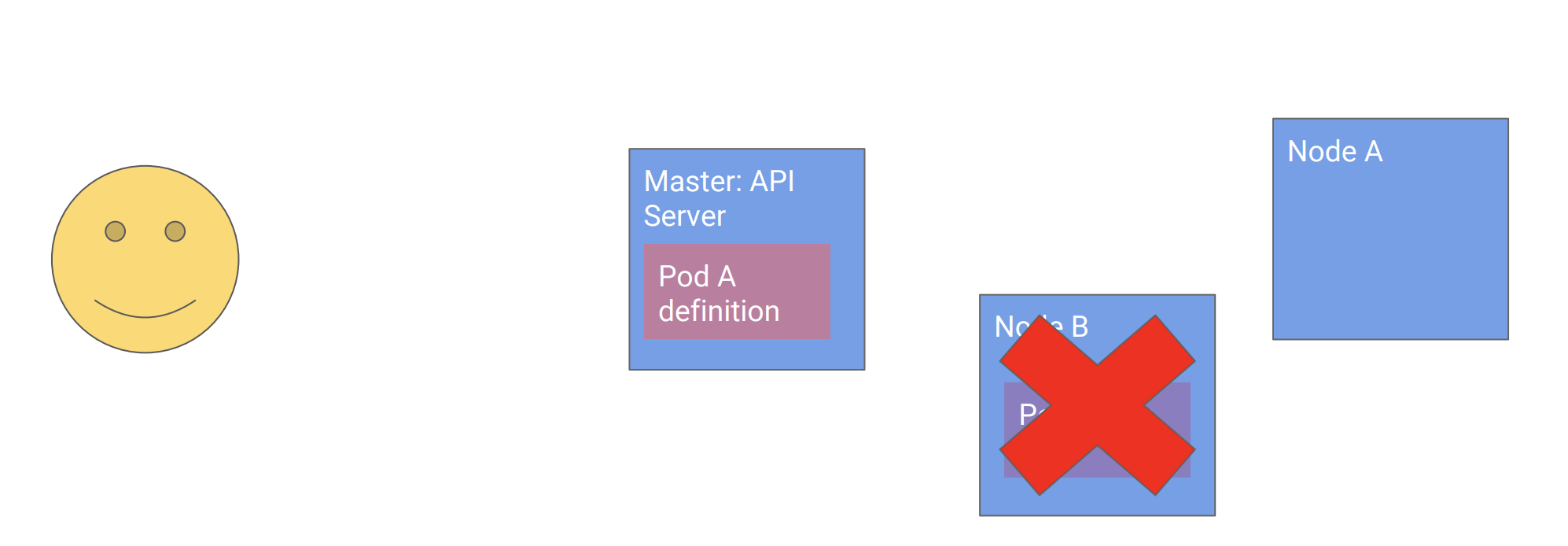
- 节点B挂了
![]()
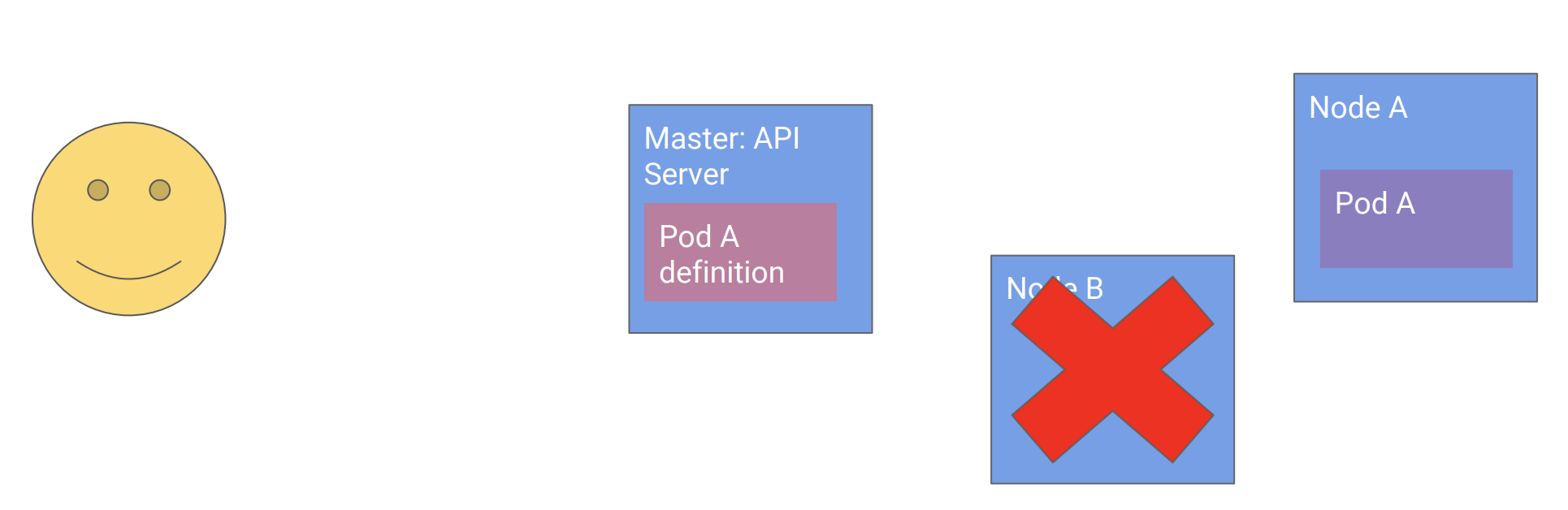
- 系统自主地把Pod移动到健康的节点A上
![]()
这里需要注意主节点只是存储了Pod的定义声明,而不会向节点B发送命令,如果那样做,主节点就会变得和我们之前提到的客户端一样,复杂而脆弱,且难以扩展。这就引入了K8s的第二个设计原则:
Kubernetes控制平面是透明的,没有隐藏的内部API ( The Kubernetes control plane is transparent. There are no hidden internal APIs. )
原则2. Kubernetes控制平面是透明的,没有隐藏的内部API
之前:
- 主节点:提供一系列的指令来驱动节点达到制定状态。
- 节点:执行主节点发来的指令
- 主节点:监控每一个节点,根据节点状态,提供进一步的指令
现在:
- 主节点:定义想要达到的状态
- 节点:独立工作以达到主节点定义的状态
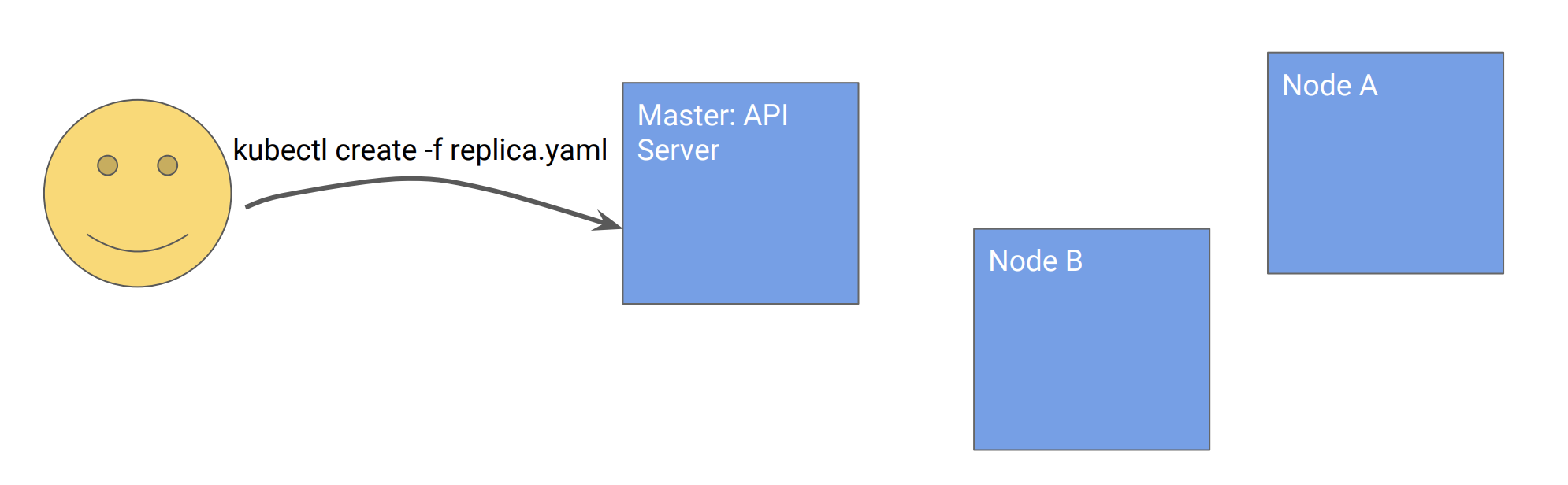
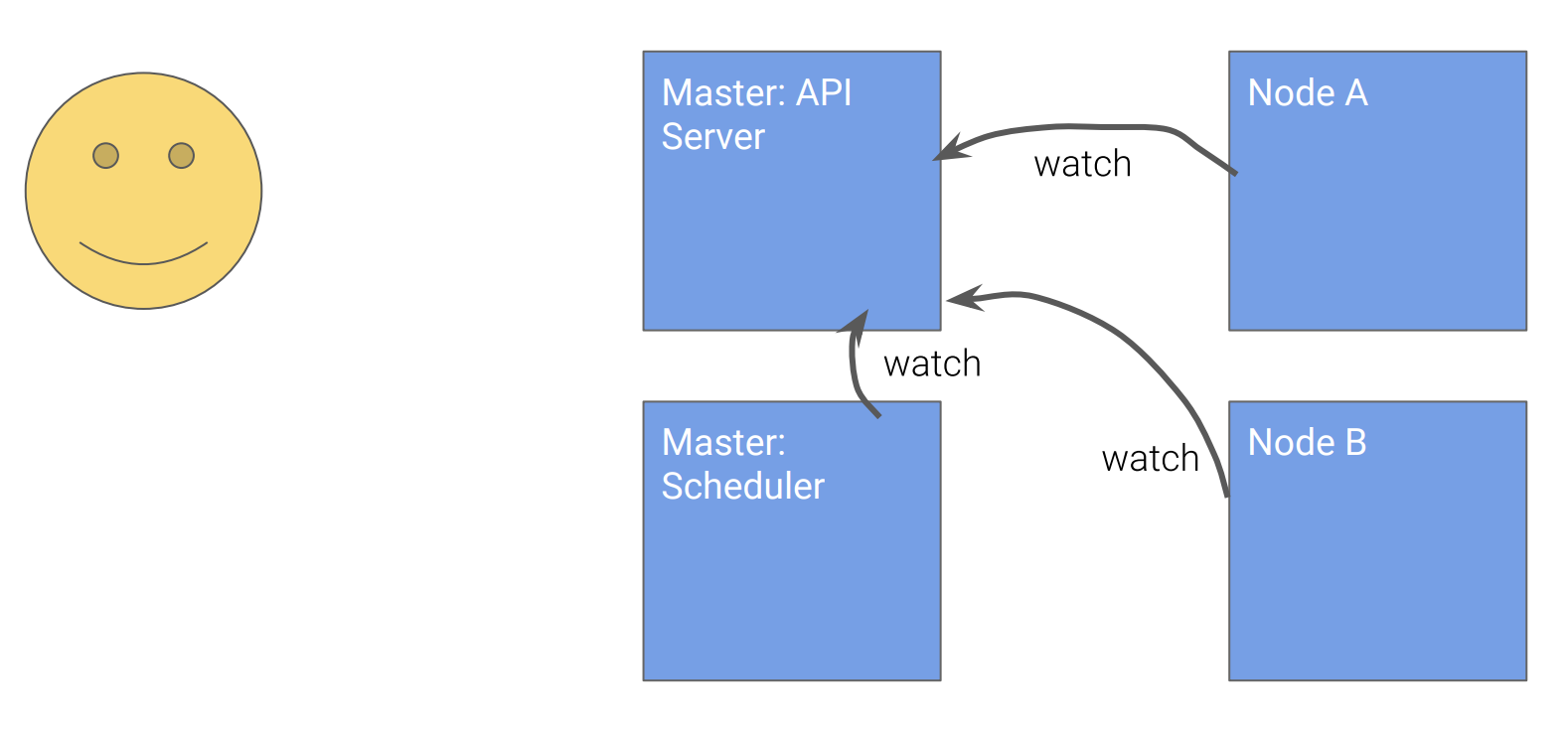
我们来看一个Pod创建的例子:
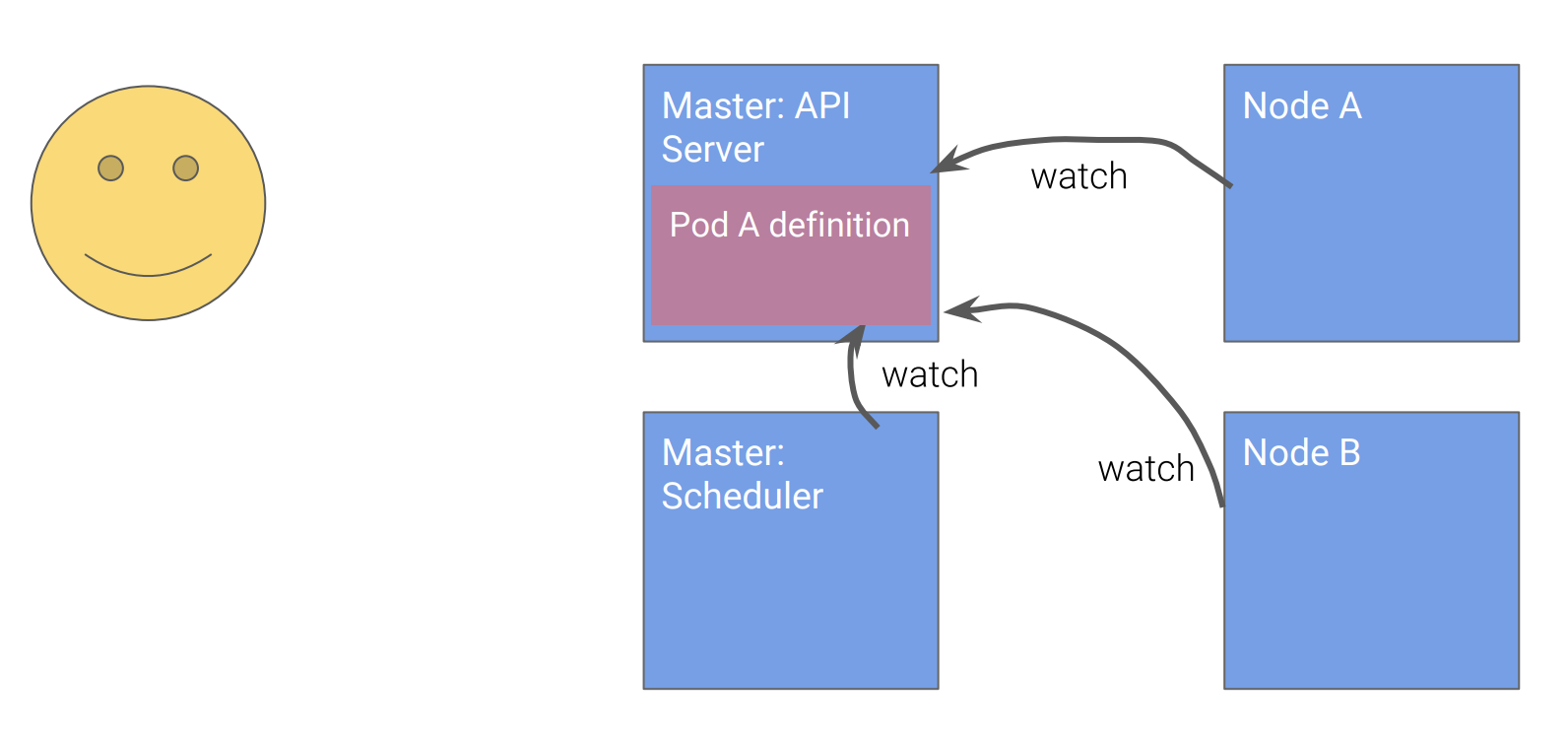
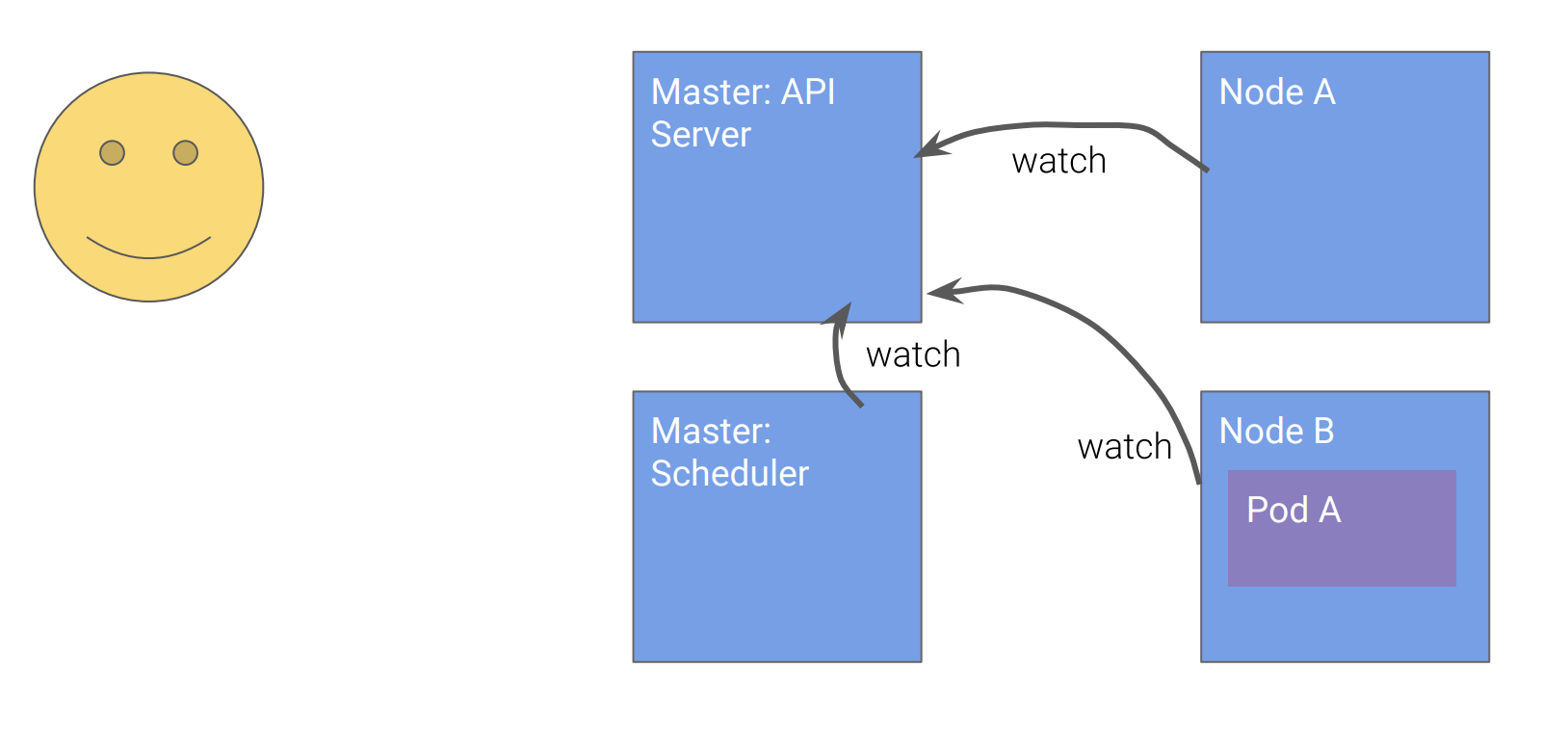
如下图所示,所有的组件都监视Kubernetes API,然后决定自己应该怎么做。
![]()
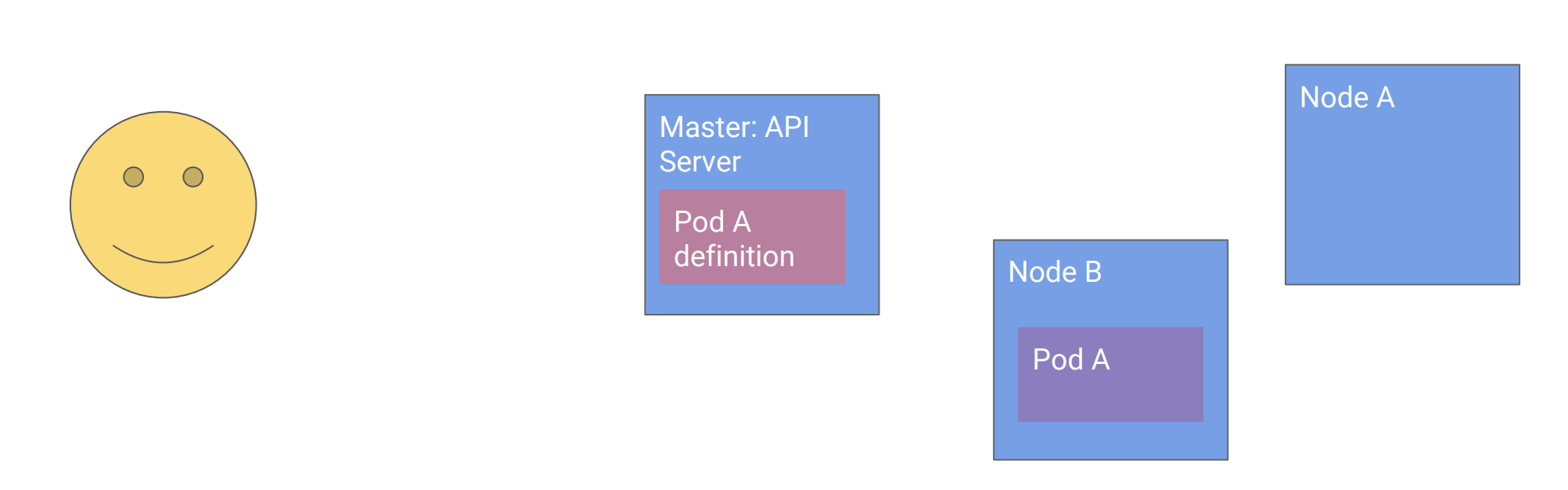
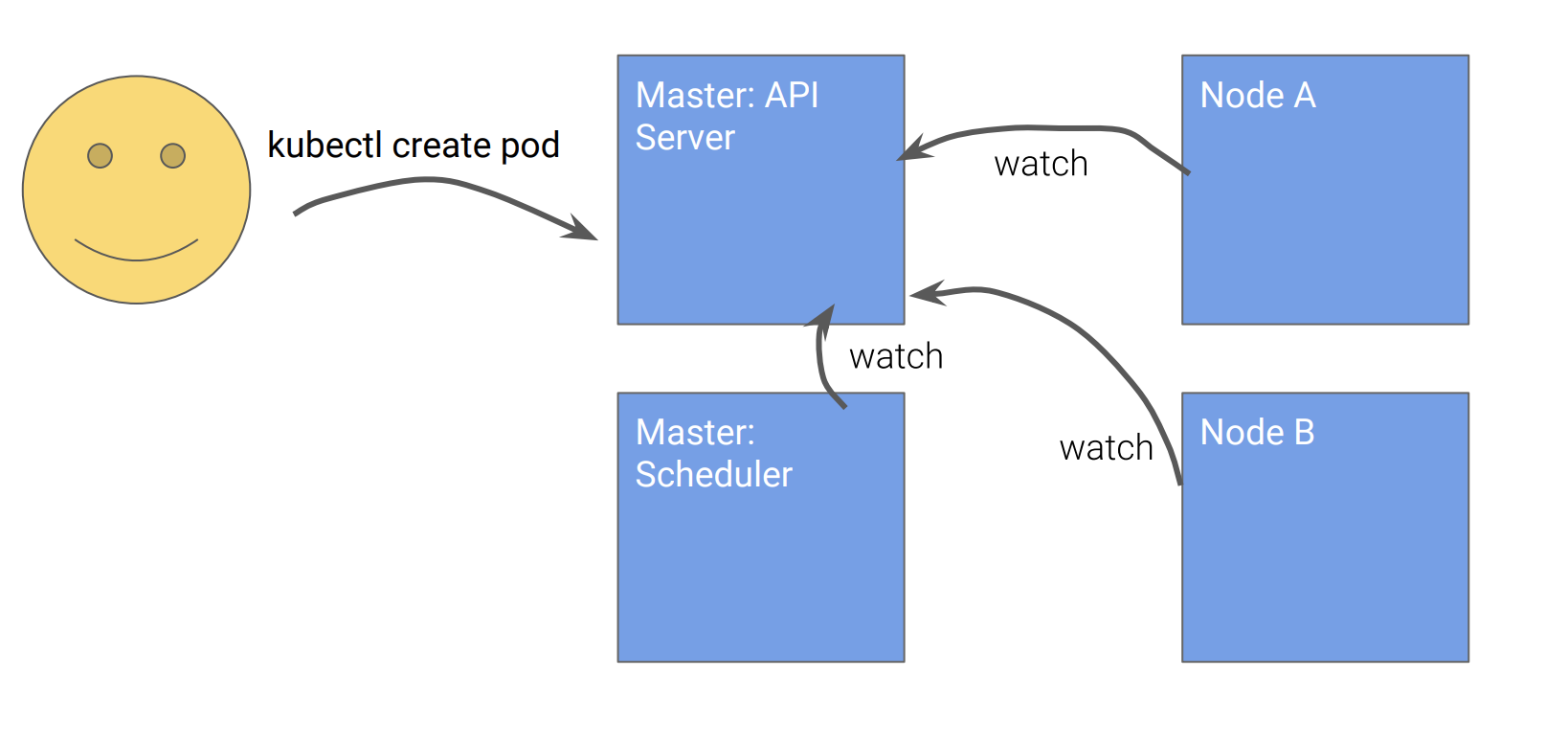
用户调用API声明要创建的Pod
![]()
主节点创建Pod的定义
![]()
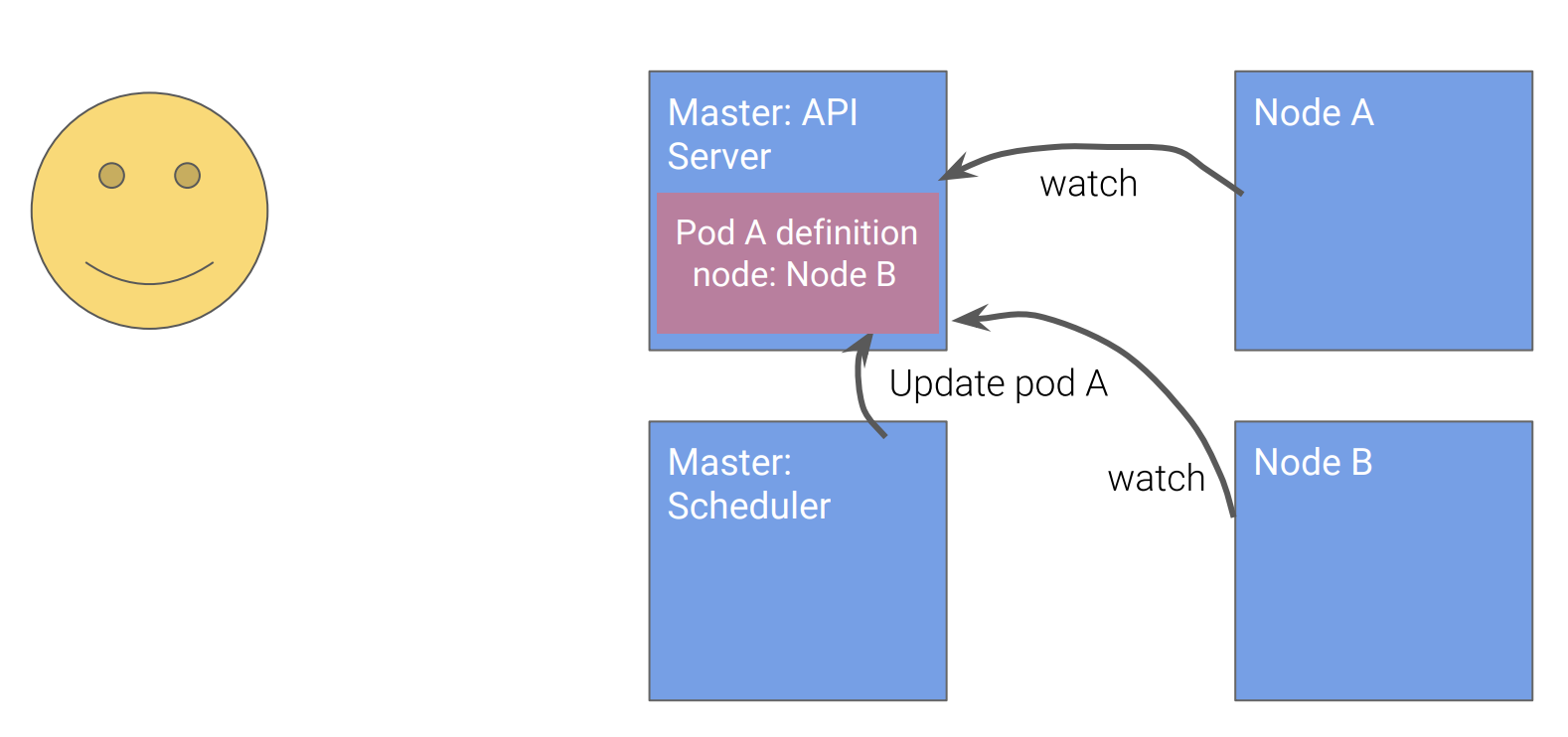
Scheduler通过API观察到Pod A的定义,通过调度运算,决定要在Node B上创建Pod A,并通过API更新主节点上的Pod A的定义。
![]()
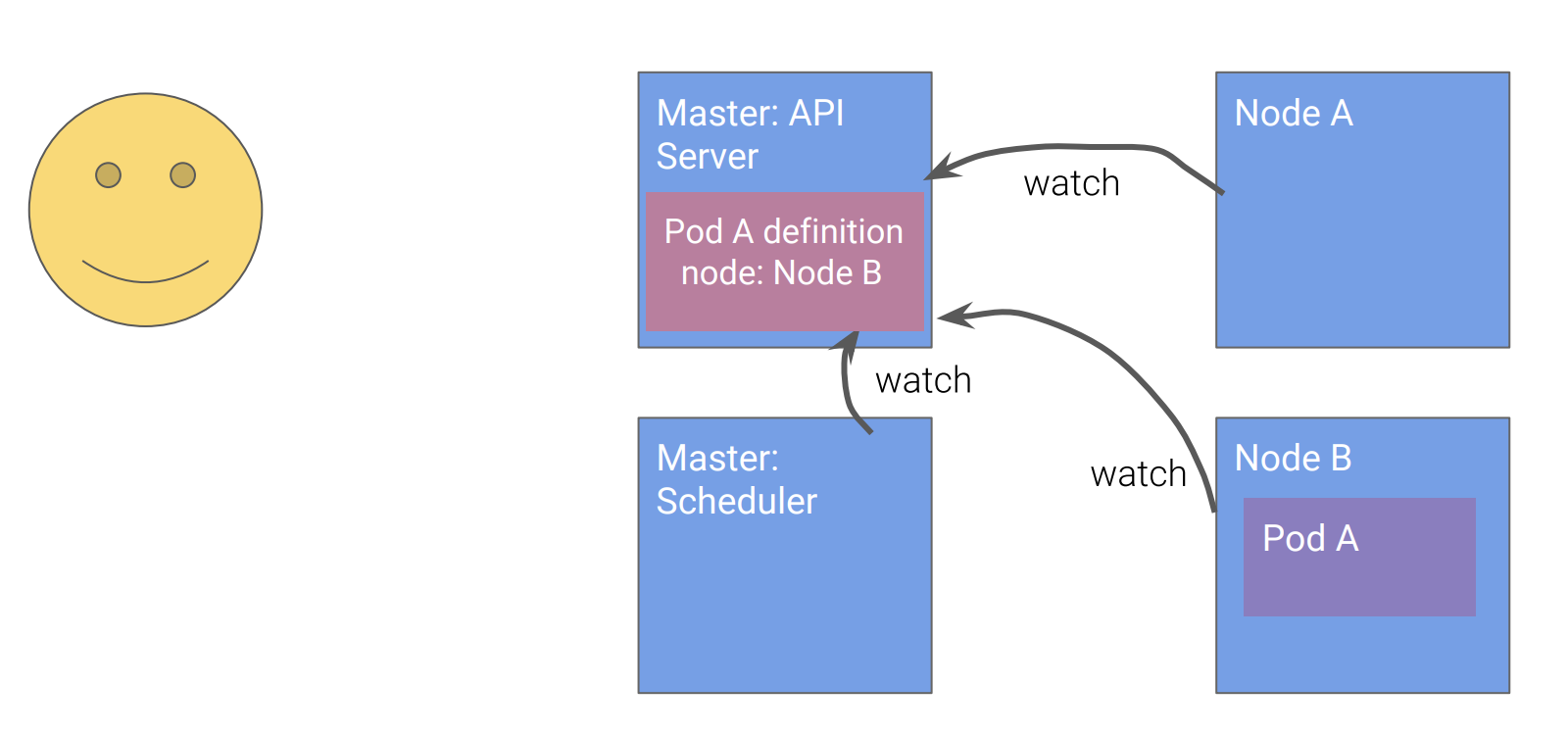
Node B观察到Pod A的定义是在自己的管辖范围,启动Pod A
![]()
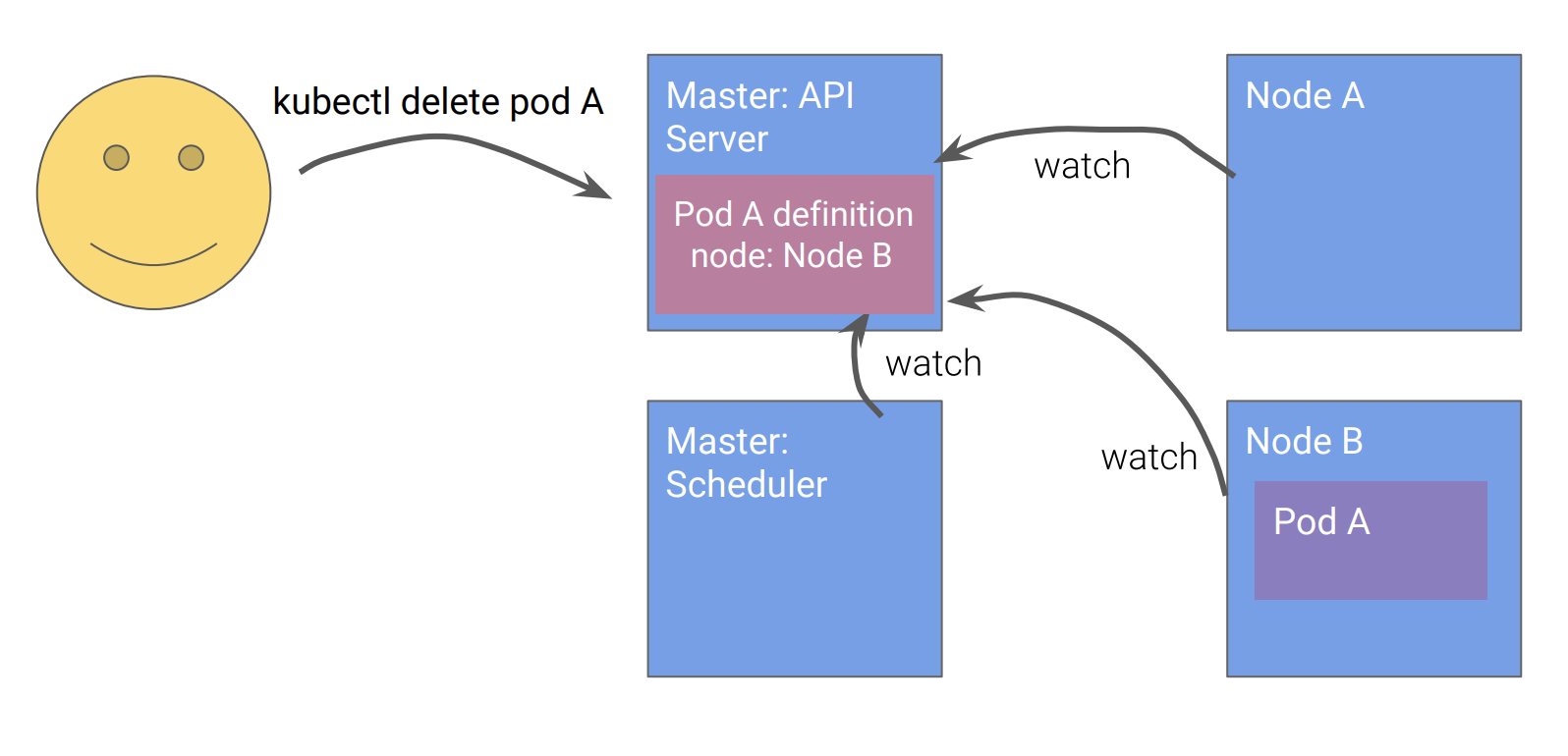
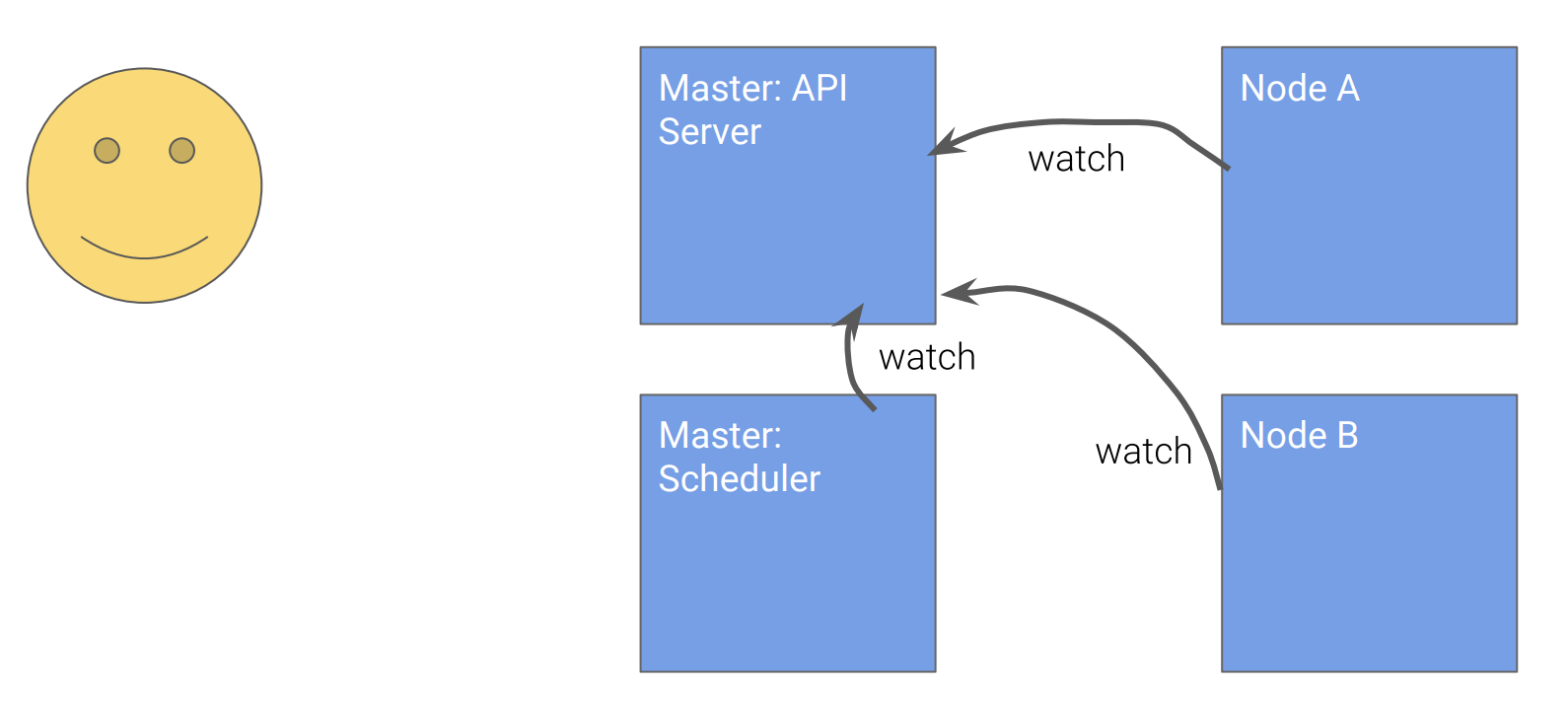
用户通过API删除 Pod A
![]()
节点B发现 Pod A被删除
![]()
节点B删除Pod A
![]()
这样做的能促成一个更简单,跟健壮的系统设计,并很容易从故障状态中恢复。系统没有单点故障,主节点的职责非常简单
这样做的另一个好处是,系统更容易扩展和组合。因为没有内部隐藏的API,用户可以很容易的用自定的组件替代已有组件,或者增加自定义的功能。
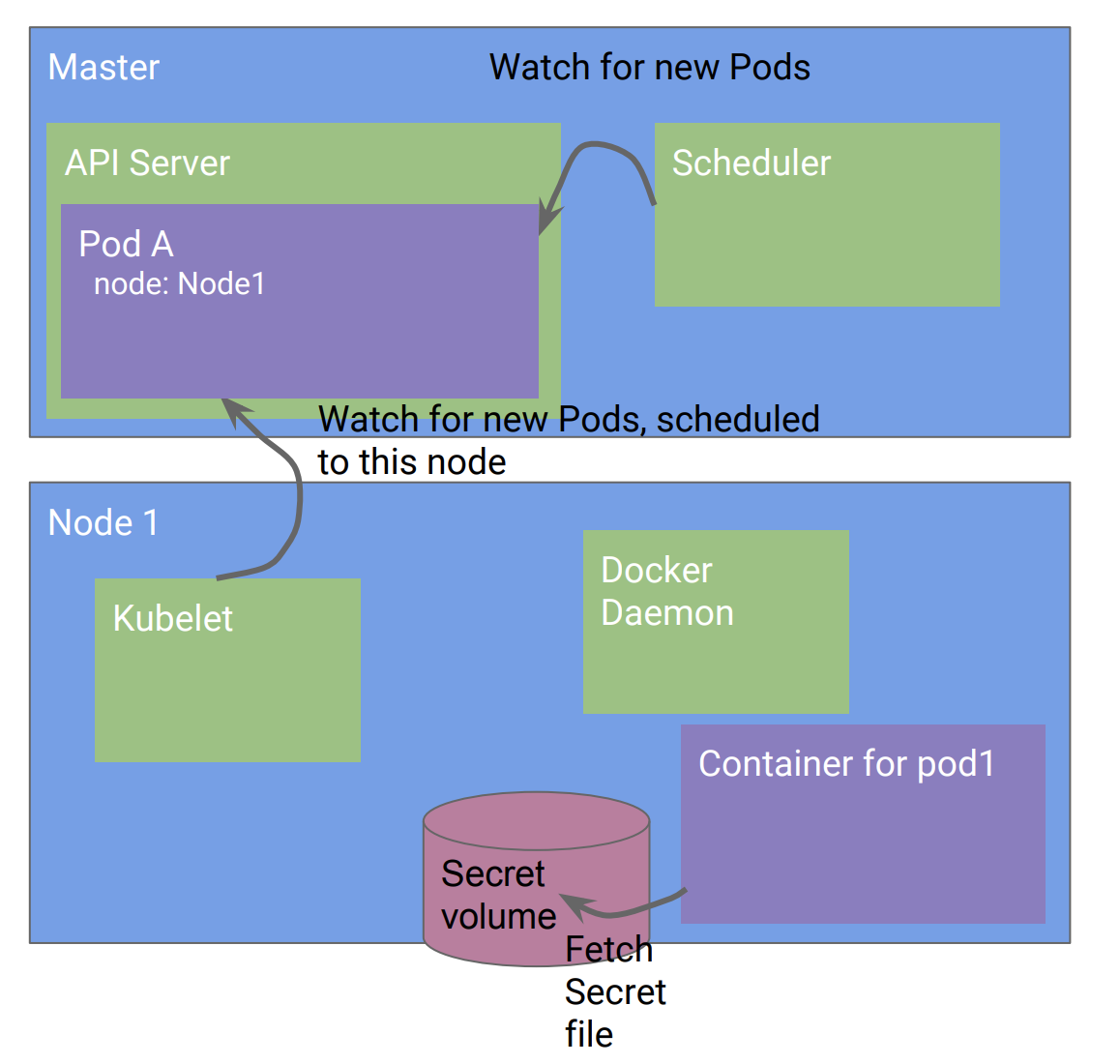
K8s还有很多对象对业务是很重要的,例如存储密码的密匙文件secret,配置configmap,或者下行API提供Pod的基本信息。那么应用程序必须修改为调用KubeAPI来或者这些信息么?
这就引入了Kubernetes的第三个设计原则
满足用户的需求 ( Meet the user where they are )
原则3. 满足用户的需求
之前:
- 应用程序必须被修改为知道K8s的存在,调用KubeAPI
现在:
- 应用程序可以从环境变量加载配置文件或者密匙文件,所以不需要修改
![]()
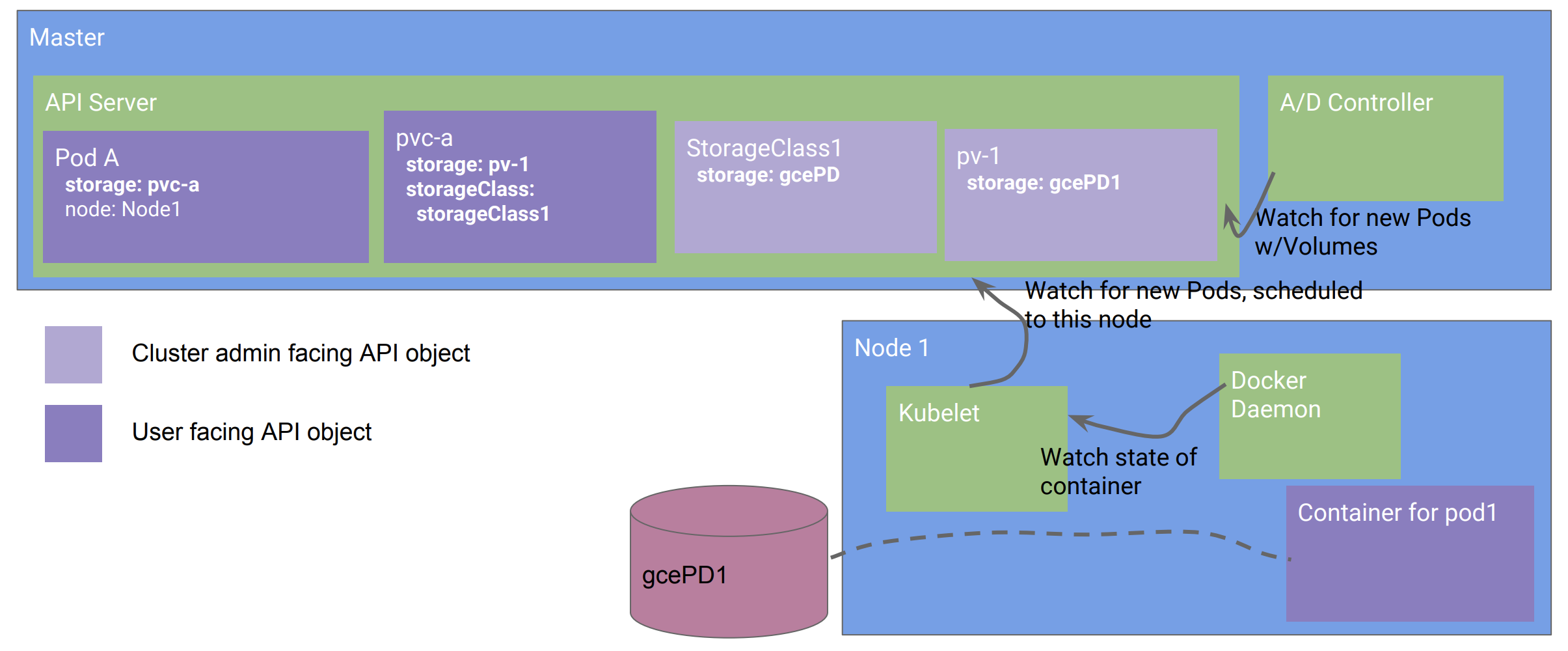
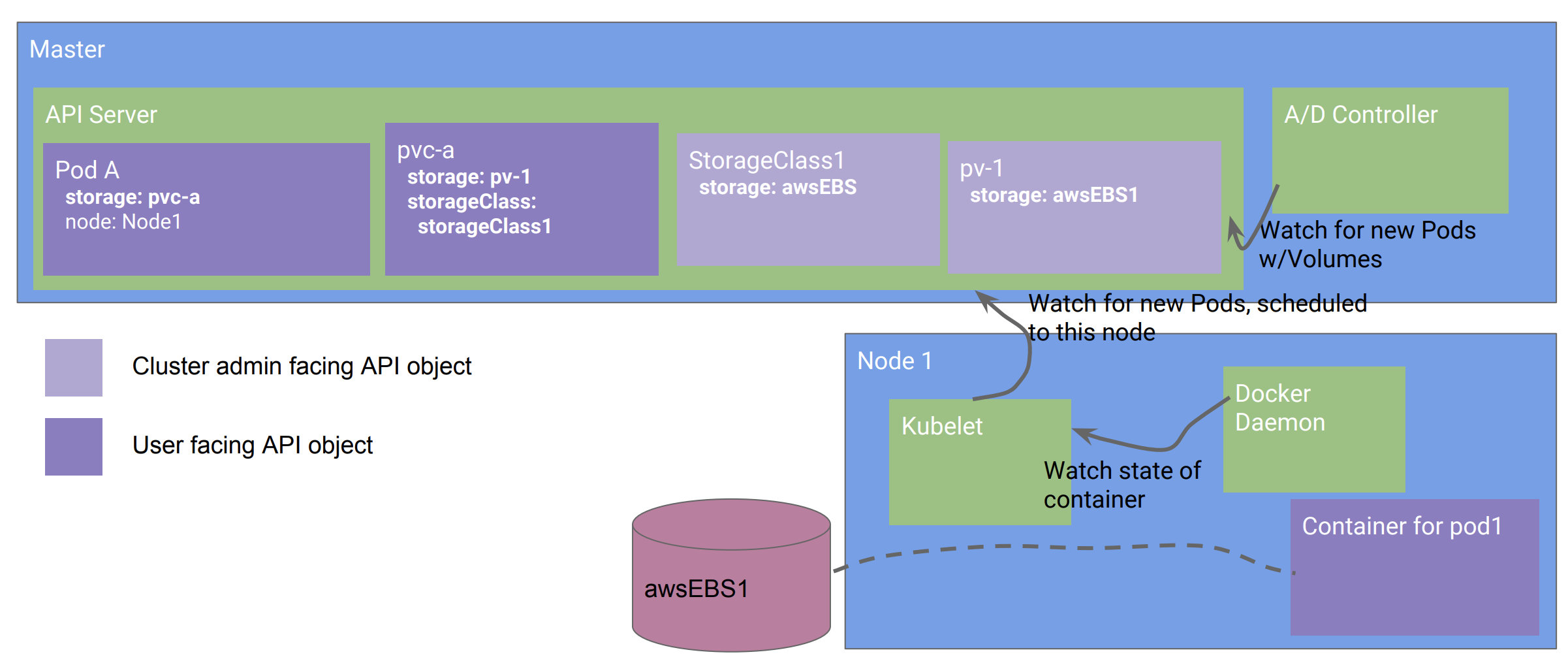
我们可以举一个例子,是关于远程存储的。
![]()
如上图所示,Pod可以直接引用一个远程的存储卷(GCE PD,AWS EBS,NFS等),kubernetes会自动使得该卷被用于Pod。但是这样做的话,有一个问题,如果你要迁移到一个新的基础架构上,那么它就不工作了。于是这就引入了kubernetes设计的第四个原则:
可移植的工作负载 ( Workload portability )
原则4. 可移植的工作负载
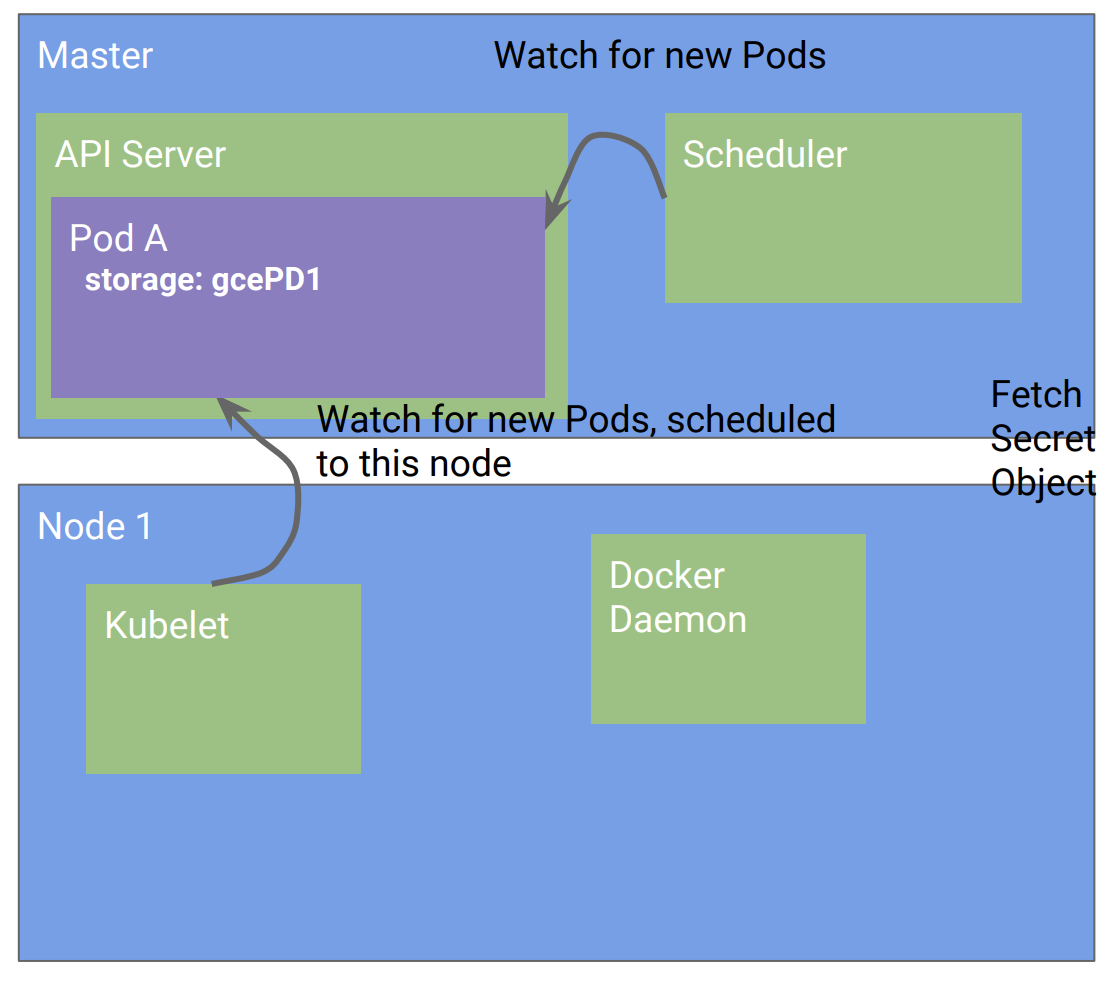
持久卷(PersistentVolumn,PV)和持久卷声明(PersistenVolumnClaim, PVC)就是这样一个例子。
![]()
![]()
如上图所示,通过PVC的抽象,用户Pod并不直接引用GCE PD或者EBS,这样就使得该Pod可以在不同的基础架构中互相迁移,做到可移植。就像操作系统一样,该设计使得系统应用和底层的硬件或者架构实现分离解耦。
总结
本文总结了Kubecon 2018的一场由谷歌高级软件工程师,kubernete开发人员Saad Ali分享的《Kubernetes设计原则》。其中的四个设计原则分别是:
- Kubernetes APIs 是声明性的而非命令性的
- Kubernetes控制平面是透明的,没有隐藏的内部API
- 满足用户的需求
- 可移植的工作负载
通过该分享,我们可以发现,K8s的背后设计原则的原因,其实它软件设计的一些一般性原则是一致的,虽然面向对象已经不在是什么流行的术语,但是本文中的设计原则和面向对象的设计原则高度一致。
- 对象要对自己负责。在设计对象的时候,对象应该尽可能的封装内部的状态,对自己负责,我们设计一辆可行驶的车。一种设计是两个对象,driver和car,然后diver.run(car)。而更好的设计是不需要driver,或者把dirver看成Car的一个属性,这样就是Car.run()。第二种设计更符合面向对象的设计原则。这正是声明式API背后的原则,组件对自己负责。
- Kube API类似对象的接口,对象对修改封闭,对扩展开放。通过开放的API,用户可以很容易的实现功能扩展,但是你无法修改已有的组件,你可以开发自定义的组件来替换已有的组件。
- 可移植性的设计类似面向对象的多态,定义抽象接口,隐藏具体的实现细节。
希望本文的分享能帮助你理解K8s背后的设计原则。如果你有什么好的顶级会议想要了解,欢迎联系我。
参考