1. 前言
我在Java8 Stream API 详细使用指南 中讲述了 Java 8 Stream API 中 map 操作和 flatMap 操作的区别。然后有小伙伴告诉我 peek 操作 也能实现元素的处理。但是你知道 map 和 peek 的区别吗? map 我们在开头文章已经讲过了,你可以去详细了解一下它,本文将重点讲解一下 peek 操作。
2. peek
peek 操作接收的是一个 Consumer<T> 函数。顾名思义 peek 操作会按照 Consumer<T> 函数提供的逻辑去消费流中的每一个元素,同时有可能改变元素内部的一些属性。 这里我们要提一下这个 Consumer<T> 以理解 什么时消费。
2.1 什么是消费 (Consumer)
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
// 嵌套accept , 顺序为先执行 accept 后执行参数里的 after.accpet
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
Consumer<T> 是一个函数接口。一个抽象方法 void accept(T t) 意为接受一个 T 类型的参数并将其消费掉。其实消费给我的感觉就是 “用掉” ,自然返回的就是 void 。 通常“用掉” T 的方式为两种:
- T 本身的 void 方法 比较典型的就是
setter 。
- 把 T 交给其它接口(类)的 void 方法进行处理 比如我们经常用的打印一个对象
System.out.println(T)
2.2 peek 操作演示
Stream<String> stream = Stream.of("hello", "felord.cn");
stream.peek(System.out::println);
如果你测试了上面给出的代码你会发现,压根不会按照逻辑跑。这是为啥子呢? 这是因为流的生命周期有三个阶段:
- 起始生成阶段。
- 中间操作会逐一获取元素并进行处理。 可有可无。所有中间操作都是惰性的,因此,流在管道中流动之前,任何操作都不会产生任何影响。
- 终端操作。通常分为 最终的消费 (
foreach 之类的)和 归纳 (collect)两类。还有重要的一点就是终端操作启动了流在管道中的流动。
所以应该改成下面:
Stream<String> stream = Stream.of("hello", "felord.cn");
List<String> strs= stream.peek(System.out::println).collect(Collectors.toLIst());
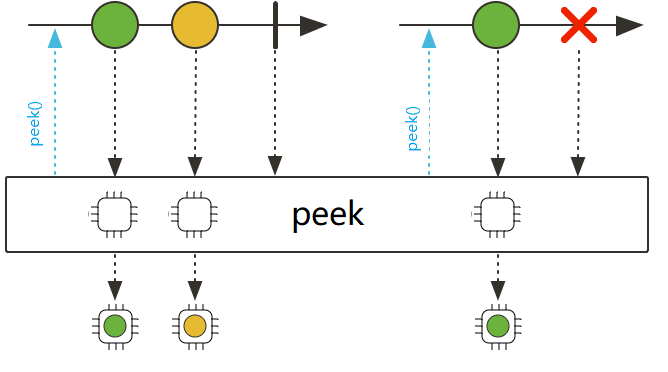
比如下图,我们给圆球加了一个框:
![]()
3. peek VS map
peek 操作 一般用于不想改变流中元素本身的类型或者只想元素的内部状态时;而 map 则用于改变流中元素本身类型,即从元素中派生出另一种类型的操作。这是他们之间的最大区别。 那么 peek 实际中我们会用于哪些场景呢?比如对 Stream<T> 中的 T 的某些属性进行批处理的时候用 peek 操作就比较合适。 如果我们要从 Stream<T> 中获取 T 的某个属性的集合时用 map 也就最好不过了。
4. 总结
我们今天了解 Stream 的 peek 操作,同时也回顾了 Stream 的生命周期。也顺带对 Consumer<T> 函数进行了讲解。而且 和 map 相互做了比较,对各自的使用场景又做了说明。相信看过本文后你对它们会有更深的理解。
关注公众号:Felordcn获取更多资讯
个人博客:https://felord.cn