说明
Dremio-3.3.1支持Hive-2.1.1版本
1.Hive批量导入数据
a).创建表
## 创建文本数据导入表
CREATE TABLE IF NOT EXISTS database.table_name(
agent_id int,
accept_time string,
signature string,
method_type string,
success boolean,
bad_app boolean,
elapse_time bigint,
start_time string,
end_time string,
jsp_weight_time bigint,
ejb_weight_time bigint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
## 创建Json数据导入表
CREATE TABLE IF NOT EXISTS database.table_name(
agent_id int,
accept_time string,
signature string,
method_type string,
success boolean,
bad_app boolean,
elapse_time bigint,
start_time string,
end_time string,
jsp_weight_time bigint,
ejb_weight_time bigint
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
注意:
创建Json数据导入表时,会报错;需首先执行
ADD JAR /home/hive/hcatalog/share/hcatalog/hive-hcatalog-core-2.1.1.jar
## 报错信息
query returned non-zero code: 1, cause: create does not exist
b).导入数据
## 导入本地数据
LOAD DATA LOCAL INPATH './hive/entry_index.txt' INTO TABLE database.table_name;
## 导入HDFS数据
LOAD DATA INPATH '/home/hive/entry_index.txt' INTO TABLE database.table_name;
c).数据验证
![]()
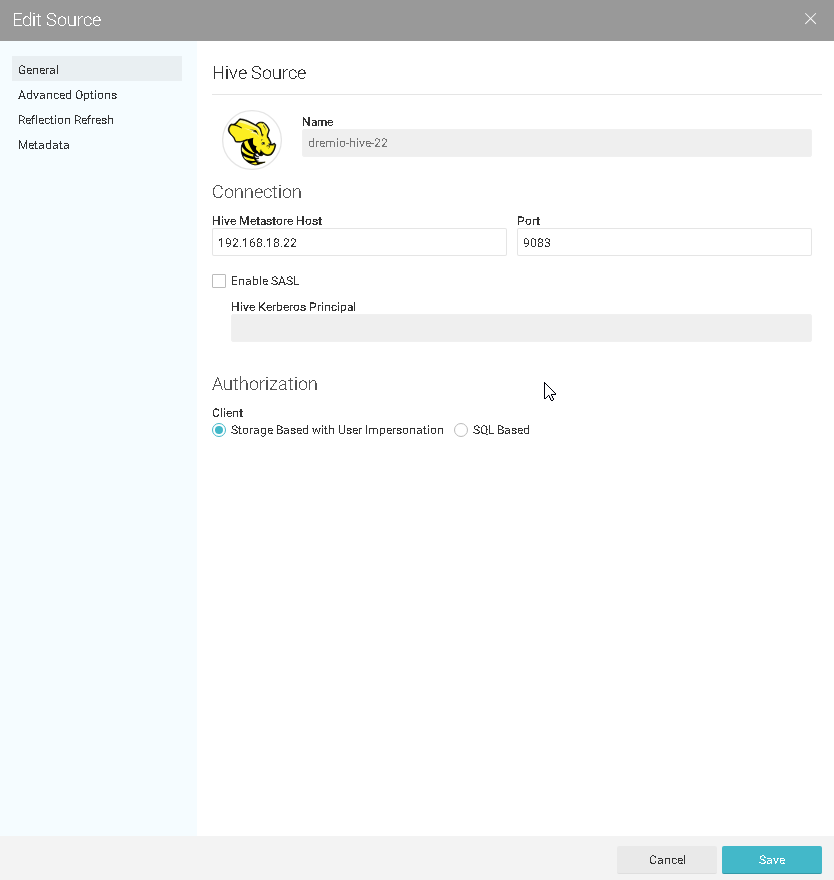
2.配置Hive数据源
![]()
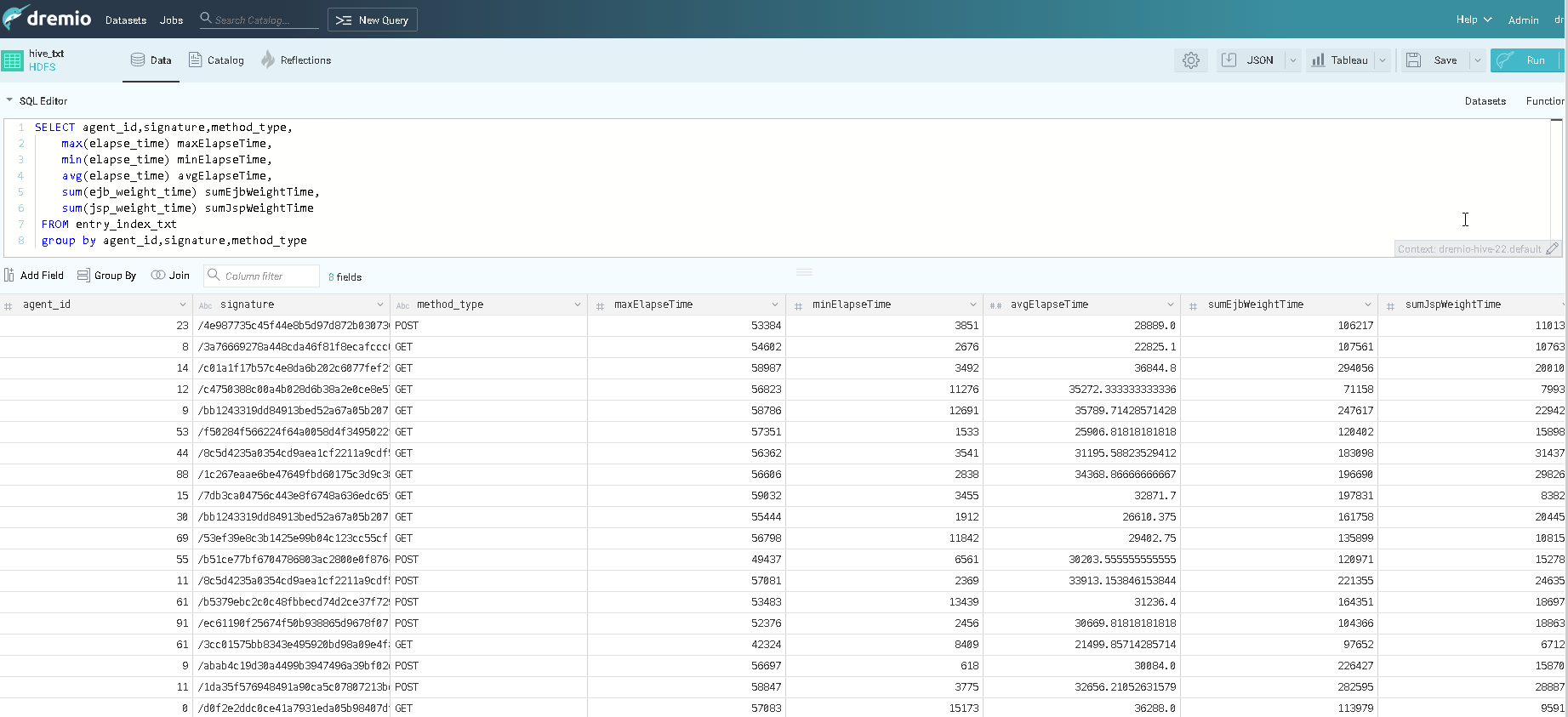
3.查询数据
SELECT agent_id,signature,method_type,
max(elapse_time) maxElapseTime,
min(elapse_time) minElapseTime,
avg(elapse_time) avgElapseTime,
sum(CASE WHEN success IS TRUE THEN 1 ELSE 0 END) succCount,
sum(CASE WHEN bad_app IS TRUE THEN 1 ELSE 0 END) badAppCount,
sum(ejb_weight_time) sumEjbWeightTime,
sum(jsp_weight_time) sumJspWeightTime
FROM entry_indx_txt
GROUP BY agent_id,signature,method_type
![]()
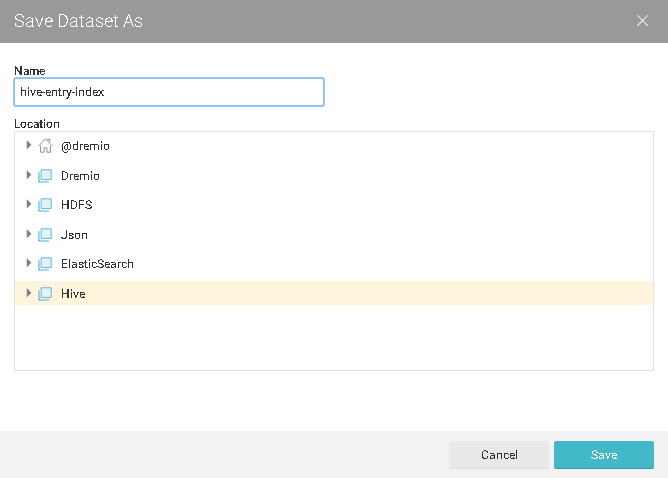
4.保存查询结果
![]()
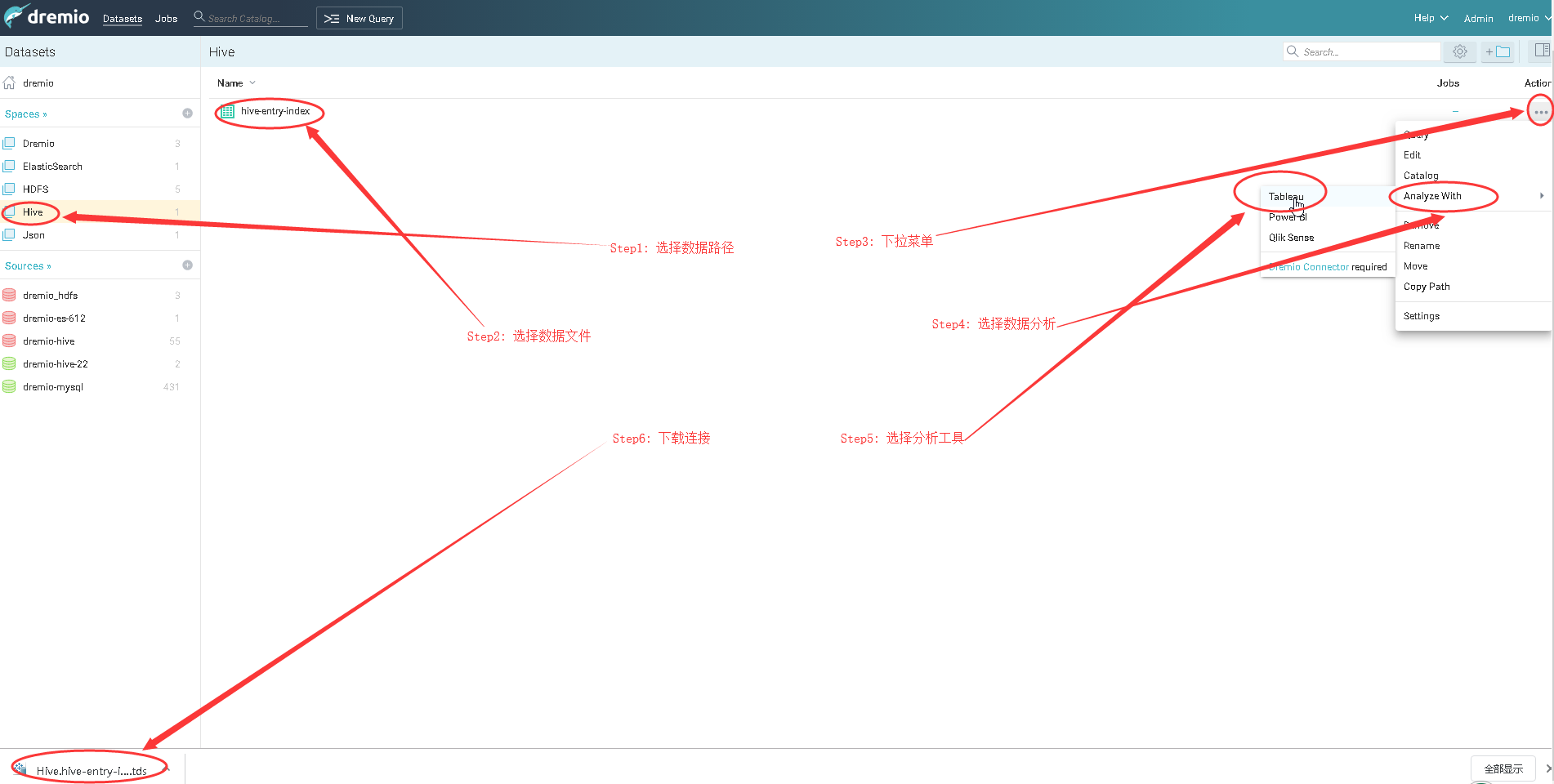
5.数据分析
a).下载文件
![]()
b).选择文件
![]()
c).连接数据源
![]()
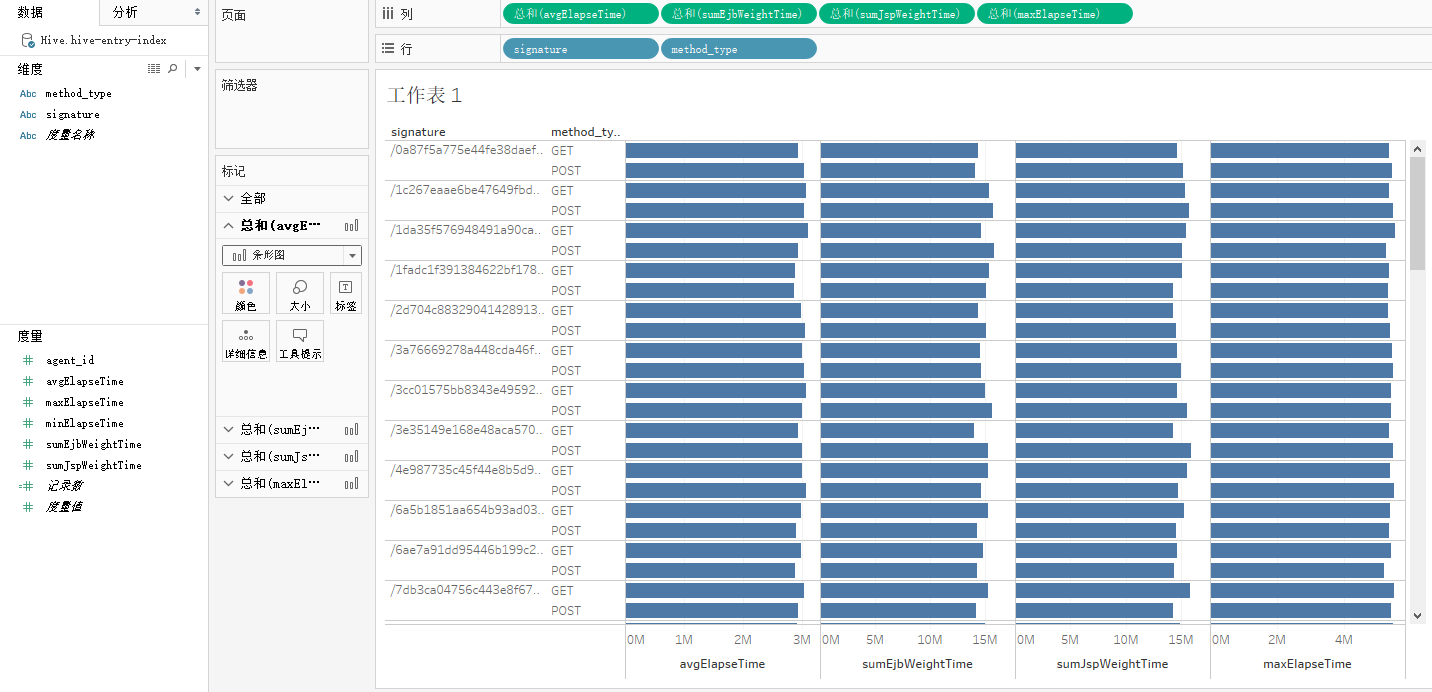
d).结果展示
![]()