接着上一篇讲吧: https://yq.aliyun.com/articles/656644?spm=a2c4e.11155435.0.0.5b663312UP3TMa
1.用户短信模型
C(t) ~ Poisson(lambda_1) t < tau # 用户在第t天前每天收到的短信数量C服从参数为lambda_1的泊松分布。
~ Poisson(lambda_2) t >= tau # 用户在第t天前每天收到的短信数量C服从参数为lambda_2的泊松分布。
其中 lambda_1~Exp(1/alpha)
lambda_2~Exp(1/alpha), # lambda_1,lambda_2都服从参数为alpha 的指数分布。
alpha = E(data). # alpha是真实样本数据的平均值,也称为样本的数学期望。
那么我们希望从lambda的先验概率中产生大量的lambda,然后不断的
2.lambda的先验
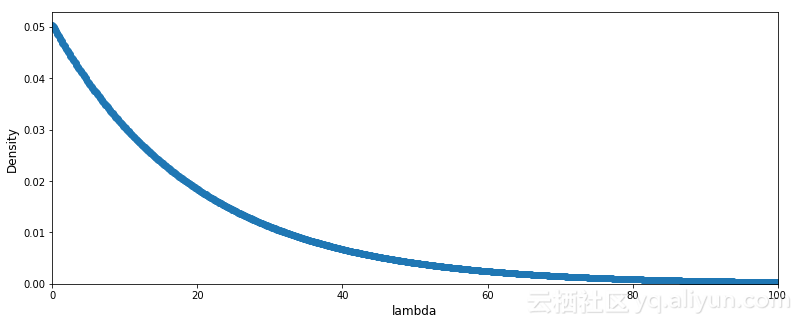
lambda服从参数为实际数据期望倒数的指数分布。lambda的先验概率:
![cf667a80eb069b8adff5449f158f19241ae868e9]()
import scipy.stats as st
from IPython.core.pylabtools import figsize
import numpy as np
from matplotlib import pyplot as plt
count_data = np.loadtxt("data.cvs")
count_data_len = len(count_data)
avg = sum(count_data) / count_data_len # 数据的平均值
alpha = 1 / avg
exp = st.expon(scale = avg) # 指数分布函数
x = np.linspace(0, 100, 1000)
lambda_ = exp.pdf(x) # lambda的概率密度
plt.plot(x, lambda_, '-o', label='$\lambda$ ={}'.format(lambda_))
plt.xlabel('lambda', fontsize=12)
plt.ylabel('Density', fontsize=12)
plt.xlim(0, 100)
plt.ylim(0)
plt.show()
对于概率密度函数, lambda取x1,x2范围内的概率是蓝线在x1,x2的积分。
3.lambda的后验
from IPython.core.pylabtools import figsize
import numpy as np
from matplotlib import pyplot as plt
import pymc as pm
# 加载真实数据
sms_data = np.loadtxt("data.cvs")
# alpha 为真实数据平均值
alpha = 1 / sms_data.mean()
# 确定参数模型
lambda_1 = pm.Exponential("lambda_1", alpha)
lambda_2 = pm.Exponential("lambda_2", alpha)
tau = pm.DiscreteUniform("tau", lower=0, upper=len(sms_data))
# 当动态参数确定时,得到一组lambda_
@pm.deterministic
def lambda_(tau=tau, lambda_1=lambda_1,lambda_2=lambda_2):
out = np.zeros_like(sms_data)
out[:tau] = lambda_1
out[tau:] = lambda_2
return out
# 使用poisson分布去模拟真实的数据,用于生成观测数据。
observation = pm.Poisson("obs", lambda_, value=sms_data, observed=True)
# 代入参数,生成Model
model = pm.Model([observation, lambda_1, lambda_2, tau])
# 使用mcmc算法
mcmc = pm.MCMC(model)
# 迭代计算,生成后验样本
mcmc.sample(40000, 10000)
lambda_1_samples = mcmc.trace('lambda_1')[:]
lambda_2_samples = mcmc.trace('lambda_2')[:]
tau_samples = mcmc.trace('tau')[:]
figsize(14.5, 15)
ax = plt.subplot(311)
ax.set_autoscale_on(False)
plt.hist(lambda_1_samples, histtype="stepfilled", bins=30, alpha=0.85,
label="posterior of $\lambda_1$", color="#A60628", normed=True)
plt.legend(loc="upper left")
plt.xlim(15,30)
plt.xlabel("$\lambda_1$ value")
plt.ylabel("Density")
ax = plt.subplot(312)
ax.set_autoscale_on(False)
plt.hist(lambda_2_samples, histtype="stepfilled", bins=30, alpha=0.85,
label="posterior of $\lambda_2$", color="#A60628", normed=True)
plt.legend(loc="upper left")
plt.xlim(15,30)
plt.xlabel("$\lambda_2$ value")
plt.ylabel("Density")
ax = plt.subplot(313)
ax.set_autoscale_on(False)
w = 1.0 /tau_samples.shape[0] * np.ones_like(tau_samples)
plt.hist(tau_samples, histtype="stepfilled", bins=len(sms_data), alpha=1,
label=r"posterior of $\tau$", color="#A60628", weights=w, rwidth=2.)
plt.xticks(np.arange(len(sms_data)))
plt.legend(loc="upper left")
plt.xlim(0, len(sms_data))
plt.xlabel(r"$\tau$ value")
plt.ylabel("Probability")
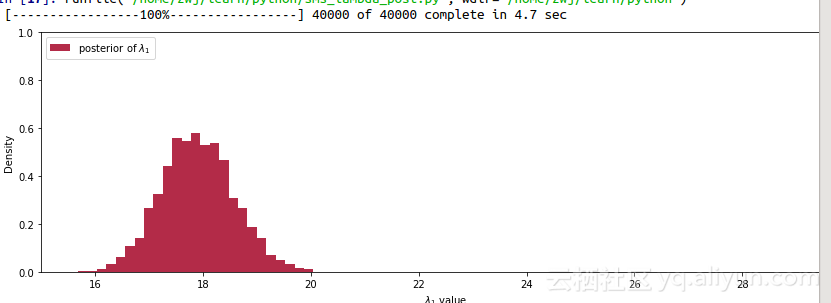
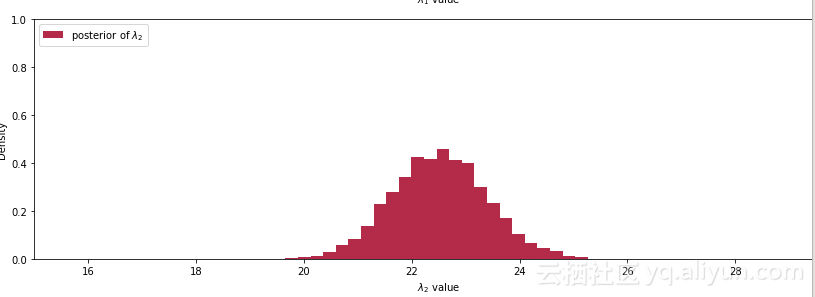
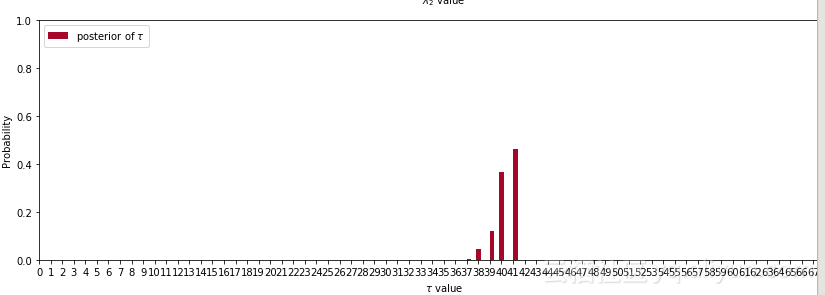
代码运行结果:
![b619dfe3be4b5fc28faddb4a5f816f39284edd1b]()
![64a13cdf5814e1b3bea246b04e52790840d8d16c]()
![d84e8ec9558a2d2693aee91b781b8b1caf2262a9]()
代码隐去了很多底层的实现和算法的细节,从这三个参数的后验图中,我们可以看出lambda_1集中在18,lambda_2集中在22.5.符合我们预期的两个lambda参数不一致,而第三幅图也显示发生行为改变在第38天到41天概率上升。
4.从先验到后验
这一段需要使用贝叶斯定理和mcmc算法来解释,尝试过了,还是理解不了。
5.后验样本的作用
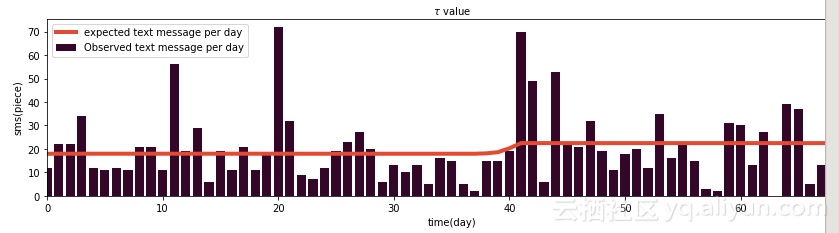
ax = plt.subplot(414)
N = tau_samples.shape[0]
expected = np.zeros(len(sms_data))
for day in range(0, len(sms_data)):
ix = day < tau_samples
# Each posterior sample corresponds to a value for tau
# for each day, that value of tau indicates whether we're "before" (in the lambda 1 "regime") or
# "after" (in the lambda 2 "regime") the switchpoint.
# by taking the posterior samples of lambda 1/2 accordingly.
expected[day] = (lambda_1_samples[ix].sum() + lambda_2_samples[~ix].sum()) / N
plt.bar(np.arange(len(sms_data)), sms_data,color ="#340628", label="Observed text message per day")
plt.plot(range(0, len(sms_data)), expected, lw = 4, color="#E24A33", label = "expected text message per day")
plt.xlabel('time(day)')
plt.ylabel('sms(piece)')
plt.legend(loc="upper left")
plt.xlim(0,len(sms_data))
![6371d4dca580bad819979646d8b268cdbab7e382]()
通过后验样本,可以看出收到短信的期望在用户改变行为后逐渐增加。
6. 数学太差,很尴尬。