一、序列化
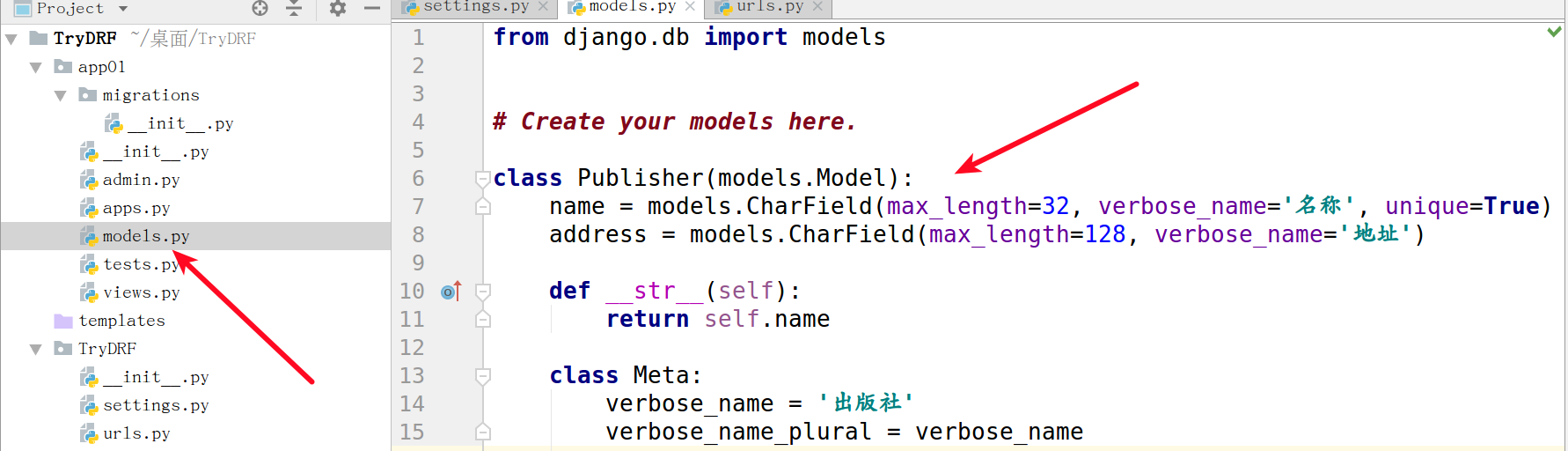
1. 创建表
class Publisher(models.Model):
name = models.CharField(max_length=32, verbose_name='名称', unique=True)
address = models.CharField(max_length=128, verbose_name='地址')
def __str__(self):
return self.name
class Meta:
verbose_name = '出版社'
verbose_name_plural = verbose_name
2. 生成迁移文件和执行迁移
python manage.py makemigrations
python manage.py migrate
3. 什么是序列化
维基百科资料关于序列化的介绍
3.1 关于序列化的解释:
在程序运行的过程中,所有的变量都是在内存中,比如,定义一个dict:
d = dict(name='Zhangsan', age=26, score=75)
可以随时修改变量,比如把name改成'LiSi',但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的'LiSi'存储到磁盘上,下次重新运行程序,变量又被初始化为'Zhangsan'。
<b style='color:red'>我们把变量从内存中变成可存储或传输的过程称之为序列化</b>,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,<b style='color:red'>把变量内容从序列化的对象重新读到内存里称之为反序列化</b>,即unpickling。
3.2 JSON
<b style='color:red'>如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式</b>,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
| JSON类型 |
Python类型 |
| {} |
dict |
| [] |
list |
| "string" |
str |
| 1234.56 |
int或float |
| true/false |
True/False |
| null |
None |
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换:
3.3 把Python对象变成一个JSON:
import json
d = dict(name='Zhangsan', age=26, score=75)
# dumps()方法返回一个str,内容就是标准的JSON
json_str= json.dumps(d)
3.4 要把JSON反序列化为Python对象,用loads()方法:
json_str = '{"age": 26, "score": 75, "name": "Zhangsan"}'
json.loads(json_str)
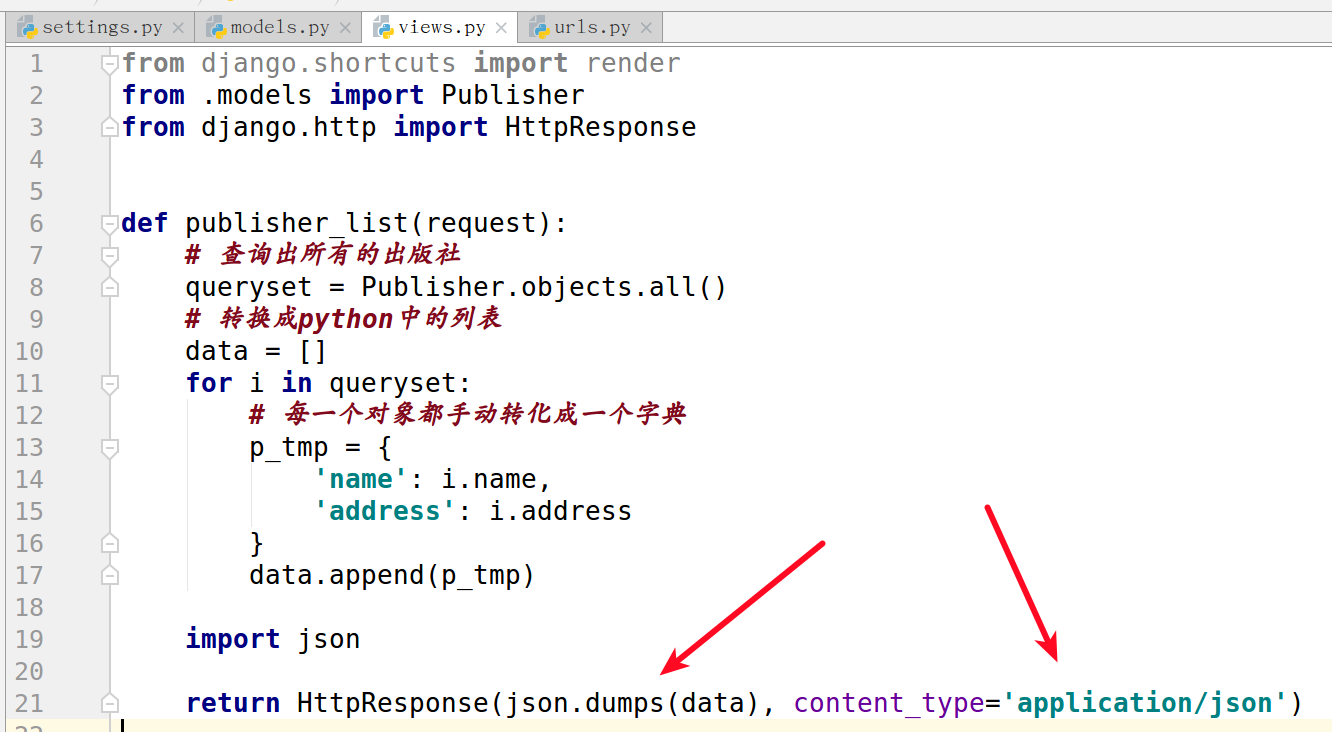
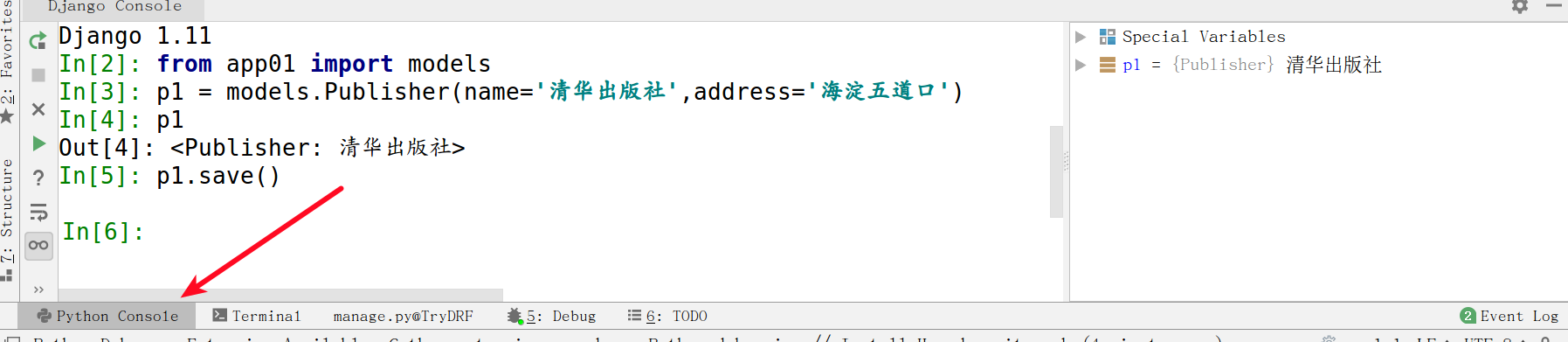
4. 通过以下方式可以实现API:
from .models import Publisher
from django.http import HttpResponse
def publisher_list(request):
# 查询出所有的出版社
queryset = Publisher.objects.all()
# 转换成python中的列表
data = []
for i in queryset:
# 每一个对象都手动转化成一个字典
p_tmp = {
'name': i.name,
'address': i.address
}
data.append(p_tmp)
import json
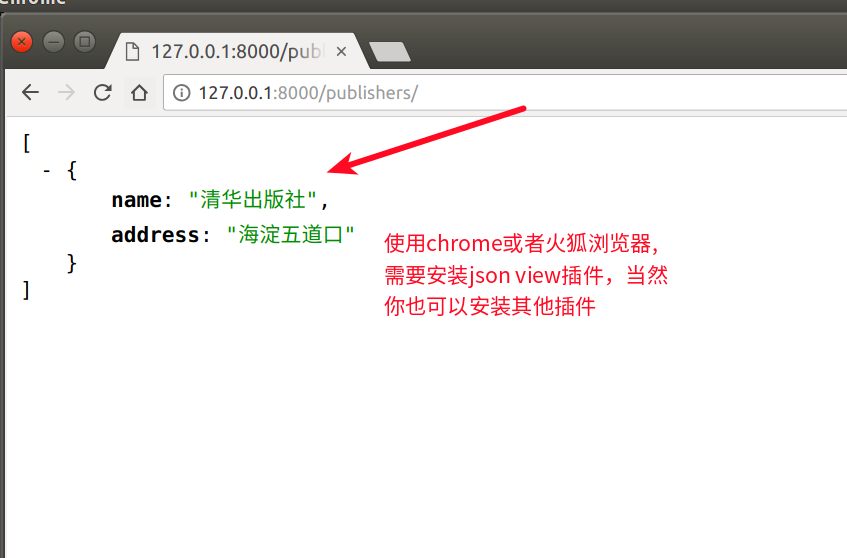
return HttpResponse(json.dumps(data), content_type='application/json')
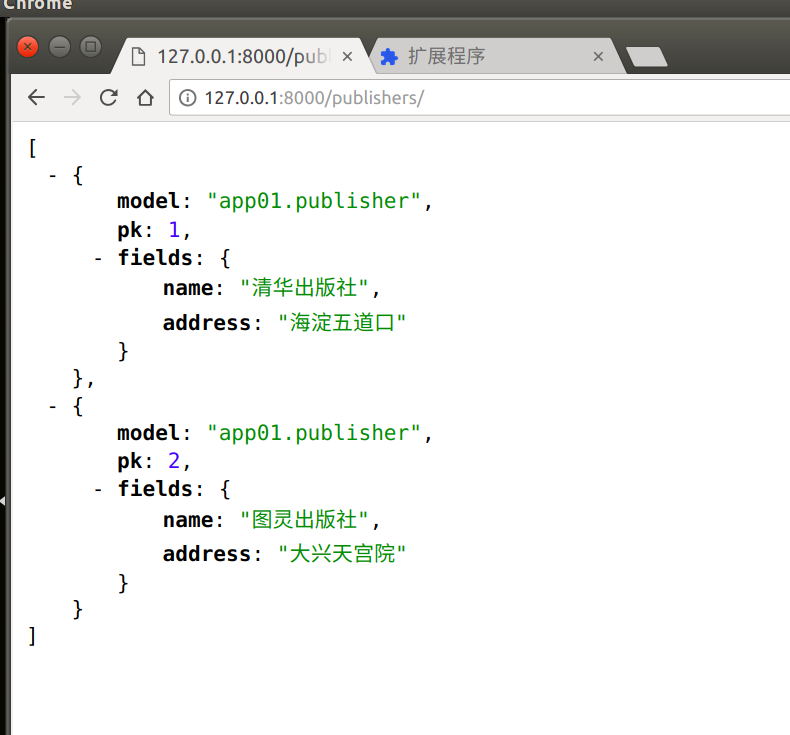
url(r'^publishers/', views.publisher_list)
python manage.py runserver
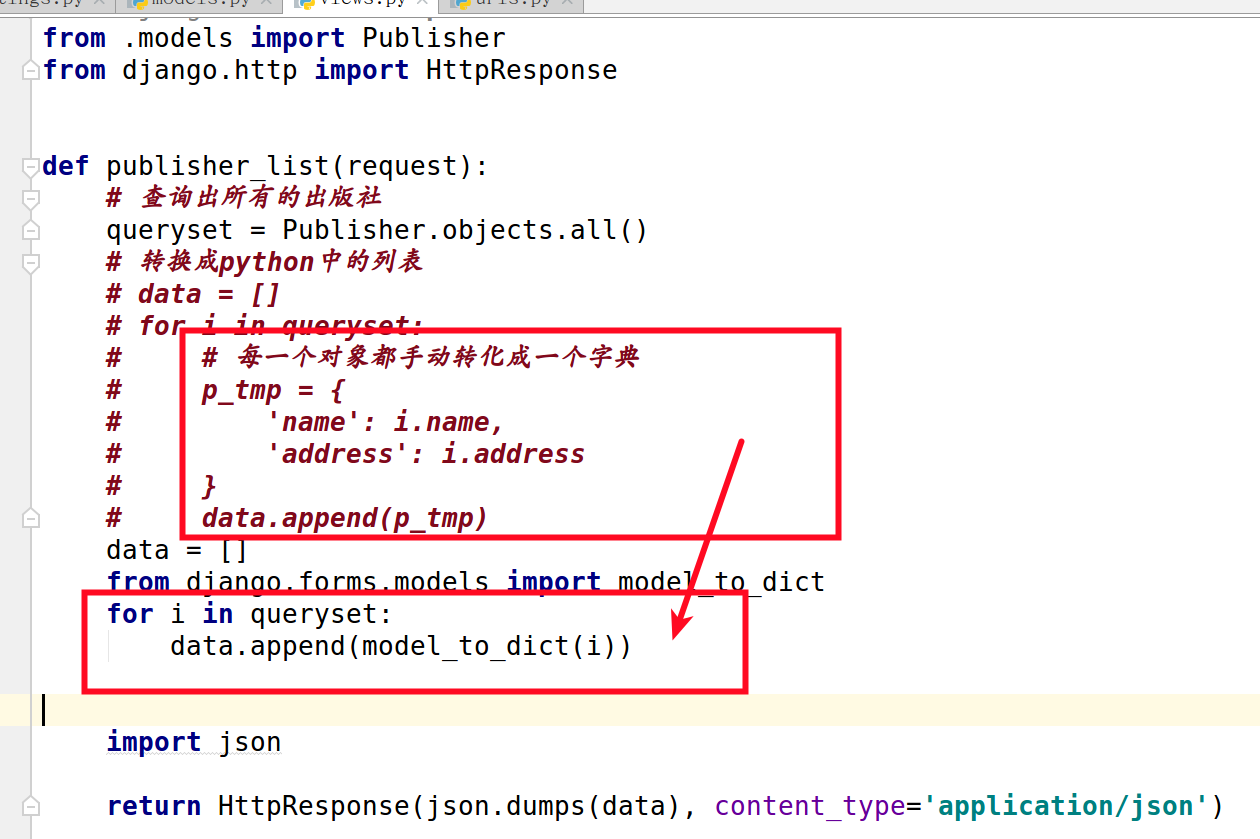
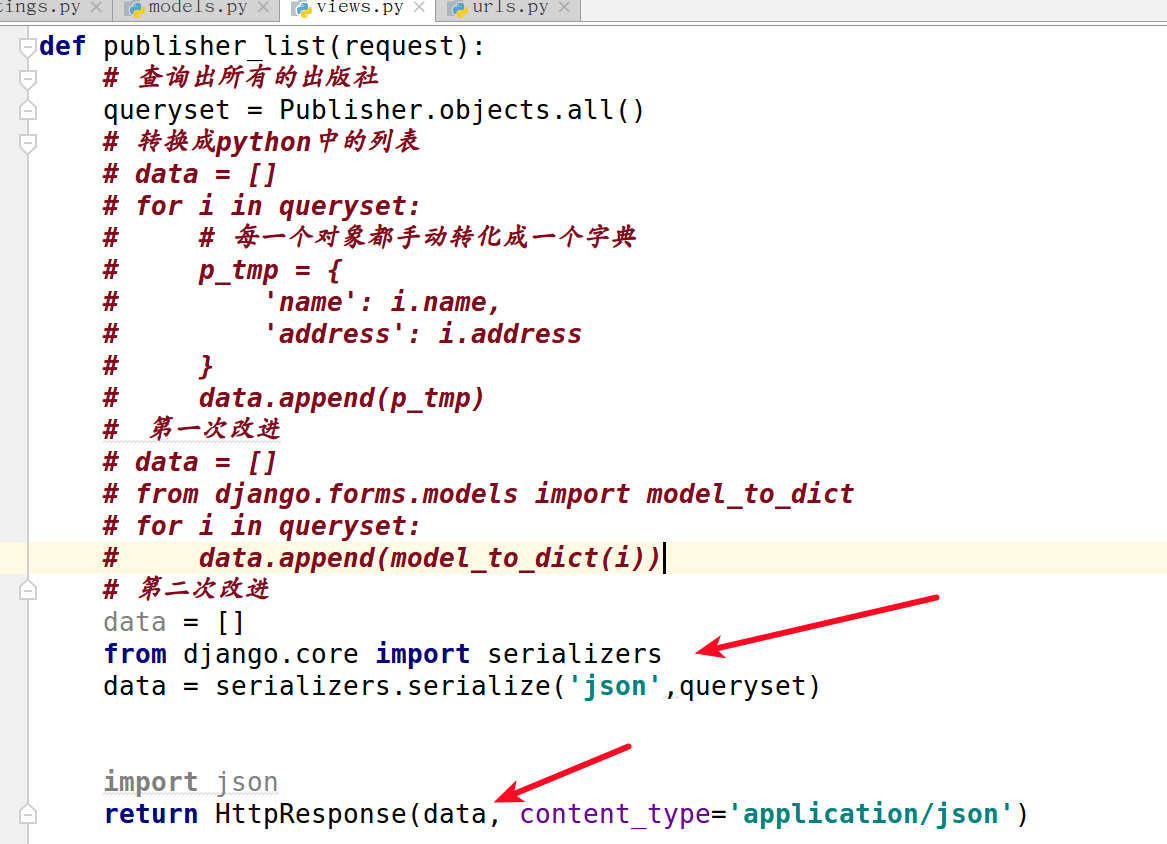
5. 对于以上的方案进行第一次改进:
data = []
from django.forms.models import model_to_dict
for i in queryset:
data.append(model_to_dict(i))
注意:这种方式有缺陷,很多字段无法转换成字典,比如图片
6. 对于以上的方案进行第二次改进(使用Django自带的serializers):
data = []
from django.core import serializers
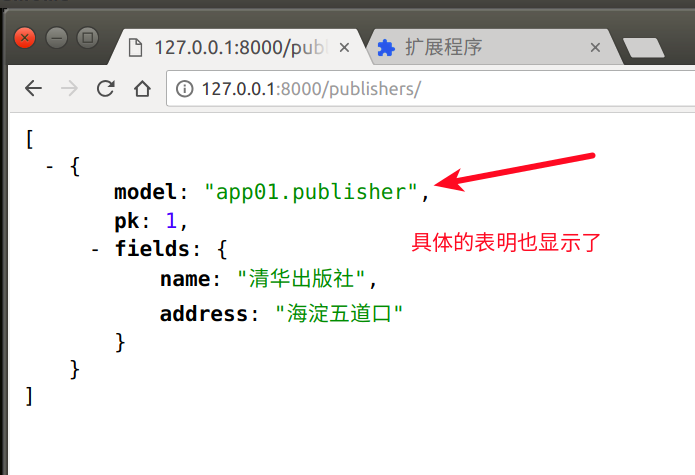
data = serializers.serialize('json', queryset)
import json
return HttpResponse(data, content_type='application/json')
注意:此时data已经是json类型
二、DRF提供的序列化
DRF提供的方案更加先进,更高级别的序列化方案,不仅仅可以实现从数据库里面读取数据,更可以存数据(增删改查)
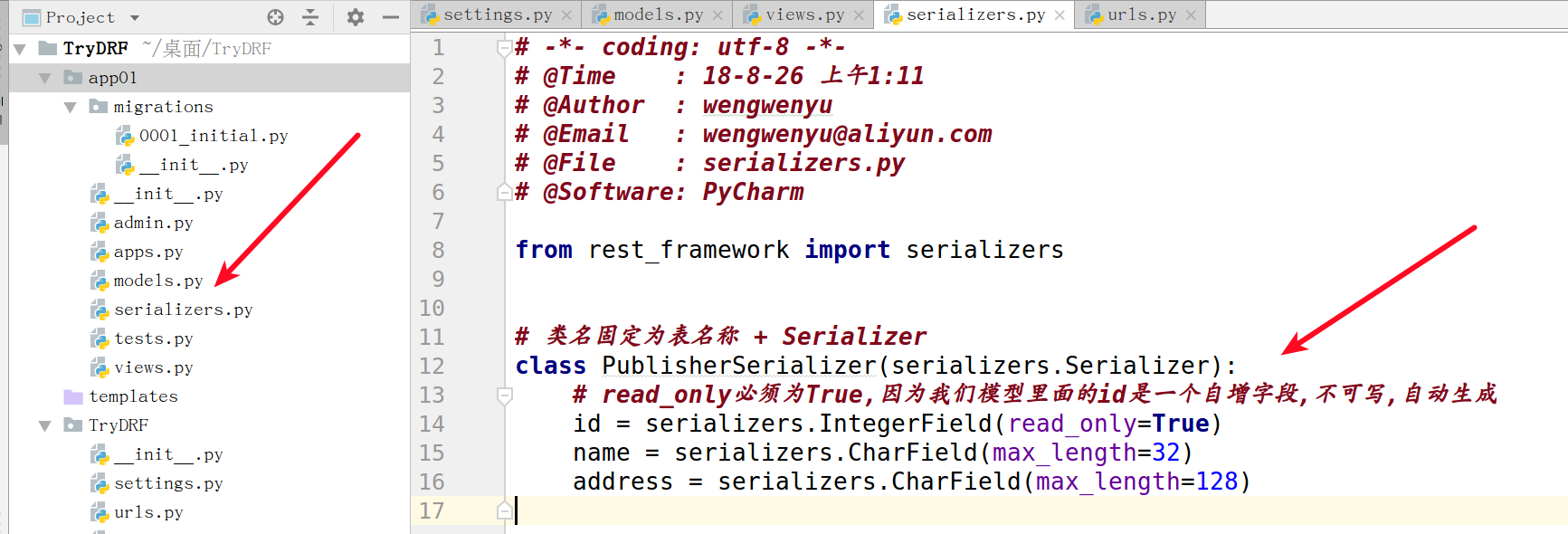
1. 在APP下创建一个序列化一个文件
from rest_framework import serializers
# 类名固定为表名称 + Serializer
class PublisherSerializer(serializers.Serializer):
# read_only必须为True,因为我们模型里面的id是一个自增字段,不可写,自动生成
id = serializers.IntegerField(read_only=True)
name = serializers.CharField(max_length=32)
address = serializers.CharField(max_length=128)
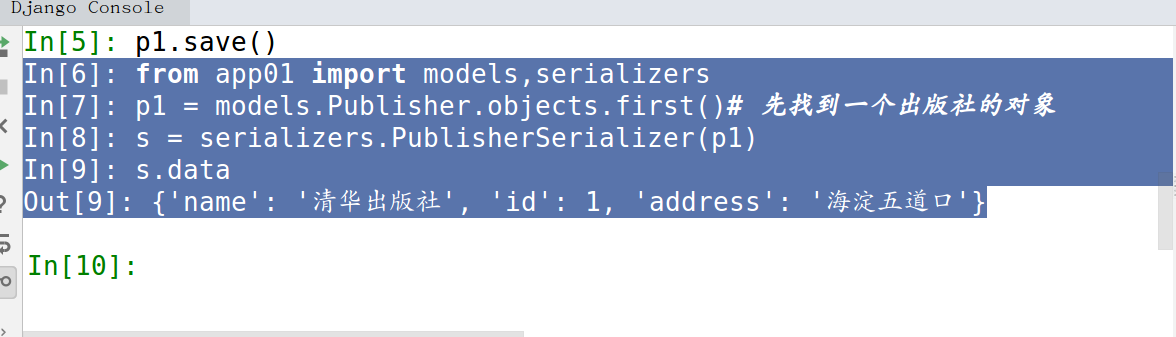
2. 使用自己定义的序列化
from app01 import models,serializers
p1 = models.Publisher.objects.first()# 先找到一个出版社的对象
s = serializers.PublisherSerializer(p1)
s.data
3. 给自定义的序列化增加一个'create'和'update'的功能
def create(self, validated_data):
# validated_data参数不需要特意去记,就是经过校验的数据
return models.Publisher.objects.create(**validated_data)
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.address = validated_data.get('address', instance.address)
instance.save()
return instance
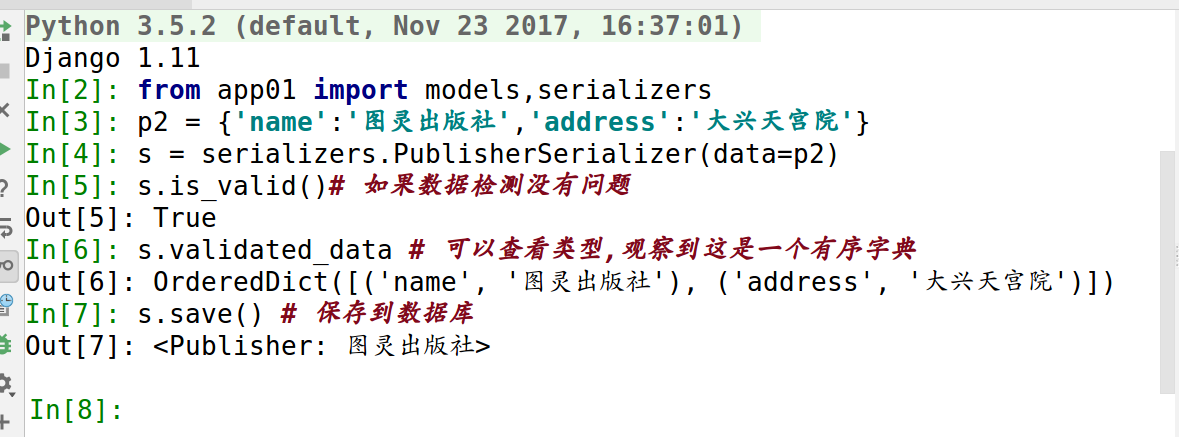
from app01 import models,serializers
p2 = {'name':'图灵出版社','address':'大兴天宫院'}
s = serializers.PublisherSerializer(data=p2)
s.is_valid()# 如果数据检测没有问题
Out[5]: True
s.validated_data # 可以查看类型,观察到这是一个有序字典
Out[6]: OrderedDict([('name', '图灵出版社'), ('address', '大兴天宫院')])
s.save() # 保存到数据库
Out[7]: <Publisher: 图灵出版社>
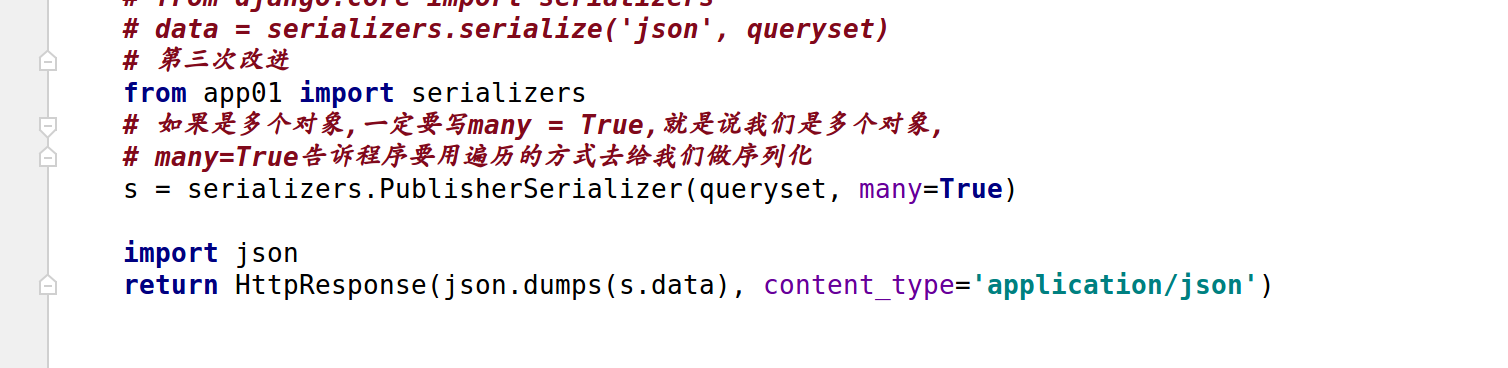
# 第三次改进
from app01 import serializers
# 如果是多个对象,一定要写many = True,就是说我们是多个对象,
# many=True告诉程序要用遍历的方式去给我们做序列化
s = serializers.PublisherSerializer(queryset, many=True)
import json
return HttpResponse(json.dumps(s.data), content_type='application/json')
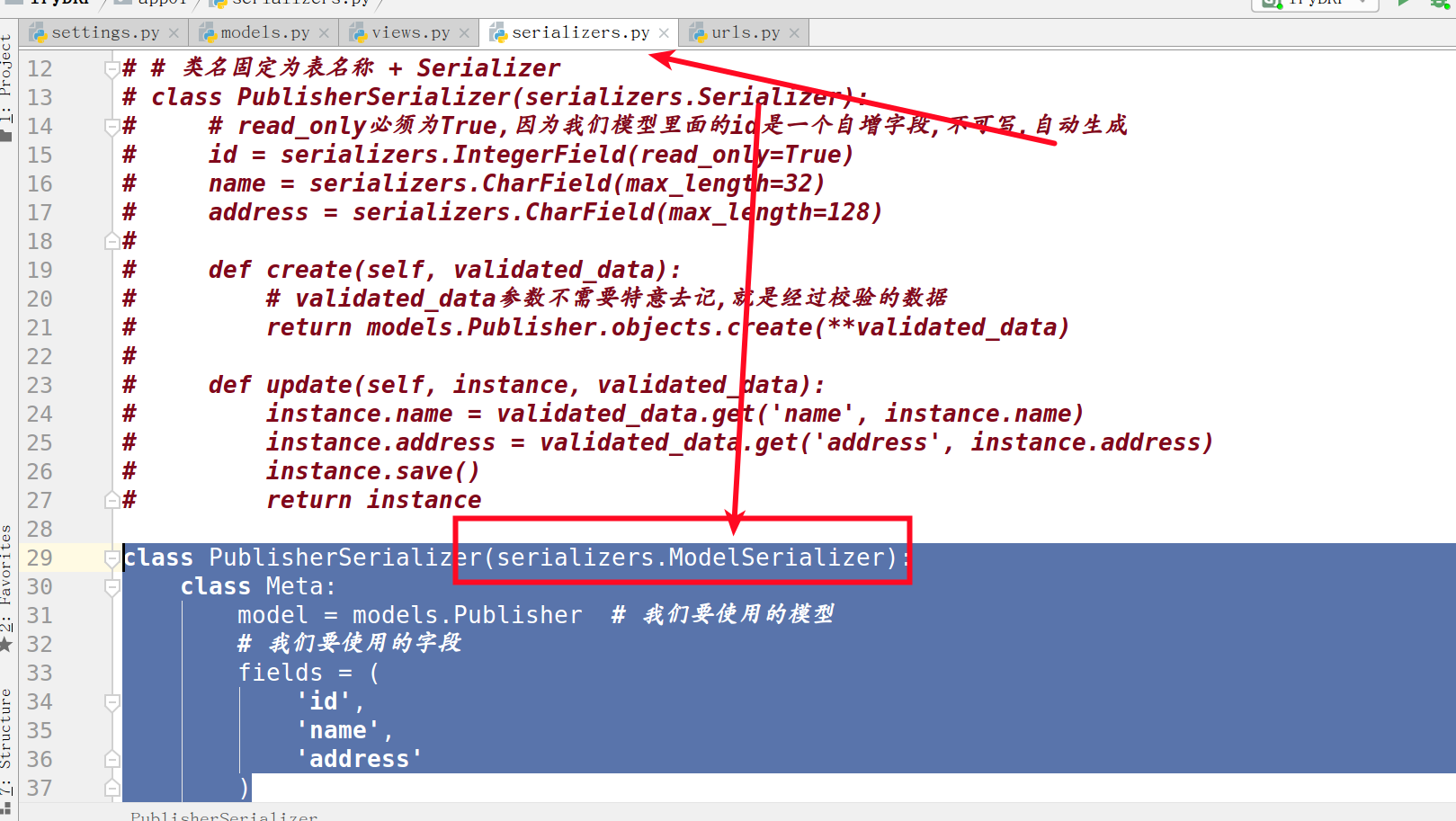
4. 改进自定义序列化模块
- 因为那些字段,我们已经在模型中创建,没有必要再创建一次,所以我们再进行一次改进
class PublisherSerializer(serializers.ModelSerializer):
class Meta:
model = models.Publisher # 我们要使用的模型
# 我们要使用的字段
fields = (
'id',
'name',
'address'
)
- 刷新浏览器,依旧可以正常运行,也就说是我们可以自己去写每一个字段,当然可以用ModelSerializer,直接使用我们的模型(相当于和我们数据库里面的表字段一一对应)