1、什么是爬虫?
不知道有多少人看过吴军博士的《数学之美》(第二版),如果没有看过,真心推荐你去看看。书中有很大一部分内容在讲搜索引擎和自然语言处理,那这和爬虫有什么关系呢?
其实还是有关系的,做个不恰当的比喻,其实搜索引擎也是一个大型的爬虫,只不过搜索引擎爬的是全网的“公开信息”,然后将网页的内容缓存并建立索引,以便用户进行搜索。
当然,这和大家理解的爬虫可能不一样。在大部分人看来,爬虫就是写一段程序来定向抓取某一类数据。我想说的也是这一类爬虫。
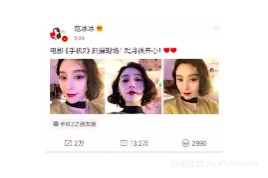
举一个例子,比如范冰冰的一条微博,大概有13.2w条评论,我们去翻看这些评论的时候,这13.2w条评论并不是一次性加载出来的,而是我们浏览的时候手指在手机屏幕向上滑,触发微博客户端向服务器发出请求,从而加载后续评论内容,正常情况下一次请求加载10条评论。
![b0be16acb257eab86126a874f665ecd8da3c8976]()
每次请求都有一个page字段或其他字段来唯一标识当前请求的这一页数据,如果用户通过手指滑动想要看完所有的评论,那会花费大量的时间。
而这时就可以用爬虫来帮忙抓取所有数据了,爬虫可以“模拟”用户发出大量的请求,从而快速获得全部数据。
大家常常谈起的爬虫,其实就是指定向抓取——通过模拟用户操作,发送请求,获取数据。
2、公开信息和后台信息
通常爬虫抓取的是公开信息,那什么叫公开信息,什么又叫后台信息呢?
公开信息有两层含义,一是面向大众的公开信息,一是面向个人的公开信息。
面向大众的公开信息是指那些你不需要登录就能浏览的信息,比如知乎、京东的产品、微博的部分页面、携程网的酒店页面等。
面向个人的公开信息是指你作为某些App的用户,需要登录自己的账号才能看到的信息,比如一些相亲网,需要你登录后才能查看别人的公开信息。
后台信息又是指什么呢?
后台信息指的是,App服务提供商才能看到的信息。拿知乎和微博为例,某些后台信息如用户的身份信息、姓名、身份证号、app的用户总量、日活跃数、某个页面的UV(浏览量)、PV(点击量)等。这类信息通常是程序的开发者或数据维护者才有权看到。
爬虫抓取的通常是公开信息,即用户有权看到的信息。如果在未经服务提供商允许的情况下获取了别人的后台信息,就是违法犯罪,这叫“脱裤”。
3、过度邪恶化
站在技术角度讲,爬虫很多时候是被大众误解了。很多人不由自主地就把爬虫和后台信息联系到了一起,更何况,现在还是一个信息安全得不到保障的时代。
所以,也可以理解,很多人觉得爬虫不是什么好东西,因为误解从一开始就产生了。
![f73dd7b7c809e7b7e009fb4e846b64fbe2168cb0]()
就像前些天闹得沸沸扬扬的程序员捅了“马蜂窝”事件。马蜂窝是一个类似于携程和去哪儿的旅游App。
几个程序员用爬虫抓取了它的一些UGC相关信息(大多是用户评论),然而发现它的部分评论是“山寨”的,或是从别处爬来的,或是自己生成的。
看网上的舆论呢,是程序员一边倒地支持扒出马蜂窝造假的那几个程序员,而其他民众基本是吃瓜,说啥的都有。
据说,马蜂窝还要告这几个程序员。不过告啥呢?如果是告他们抓取数据,可是自己的数据也是从别处抓过来的呀。如果是告诽谤,数据摆在那里,又是实锤。看来,这肚子气只能憋回去了。
其实要说数据造假,恐怕少有App敢站出来说自己没造过假,行业内都是你爬我的数据,我爬你的数据,大家也都心知肚明。
这次马蜂窝是吃了亏了,不过也怨自己,因为它宣扬的就是自己的用户量和数据真实性,这次被打脸了也没法还手。
4、互联网信息管制
并不是抓取公开信息就是合理合法和不受管制的,只是现在还没有明文规定去管这一块。如果真的哪天程序员写爬虫触及到了别人的利益,还是很有可能惹祸上身的。
之前也有过案例,“车来了”的五名程序员爬取实时公交数据,进行不正当竞争,被关进了监狱。
技术无罪,就看你如何使用,即使是公开信息也不见得能爬取。在文章开头,我们提到过搜索引擎也是一个大型的爬虫,如果一些网站不想被搜索引擎收录或者抓取,它就可以通过某种协议来告知搜索引擎,你不要来抓取我了。
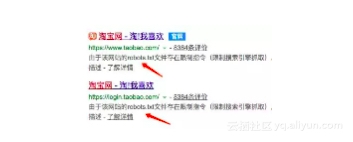
就如下图,通过百度搜索淘宝会发现淘宝网相关的网站底下写了这么句话:“由于该网站的robots.txt文件存在限制指令...”,这句话的意思就是,百度无权抓取淘宝网内部的数据,所以你很少在百度上直接搜索到淘宝上的商品。
![c3798ea17b1ccc57561225b752b00c9e85de891b]()
互联网上充斥着各种各样的协议,也正是因为有这些协议的存在,互联网才能这样有条不紊地运行。
robot.txt 文件你也可以理解为协议的一种形式,只要对方网站的robot.txt文件中标明了自己不愿被抓取,那么强行抓取,可能就会造成侵权。
5、学爬虫还有没有意义?
把爬虫说的那么可怕,是不是吓得你都不敢学了?学还是要学的,因为爬虫在以后还是很有用武之地的。
对公司来说,在数据时代,只要有市场,爬虫就一定有用。虽然明面上大家都说自己的数据多么多么真实,可实际谁知道呢?
还有一点就是,即使你不爬别人的数据,也阻止不了别人爬你的数据,所以每个以数据为生的公司都会安排一波人去做反爬虫,用各种策略应对竞争者或其他公司的抓取行为。
反爬虫一般都被做成中间件,以服务的形式给其他应用接入,所以反爬虫肯定是比爬虫要难很多。毕竟各种前端的加密都是暴露在外的,原则上没有爬不了的数据。
对个人来说,爬虫的用处也很大,不管你是经营一个实体店,还是一家淘宝店,你都需要获取并统计数据,数据分析思维是很有必要的。
一个很简单的例子,市面上很多淘宝开店秘籍讲的其实就是数据分析的事儿,只是换了个说法,不显得那么技术化而已。淘
宝直通车多数时候就是做A/B test,检索优化其实就是做SEO,刷排名其实就是在统计热点词汇等等,如果你懂了技术,这些事情都可以用技术解决。
如果一个人既有商业头脑又有技术,那么他应该会比别人获得更多的收益。当然,很多人只具有这两项技能中的一项,或者一项都没有。
总之今后,爬虫、数据分析、乃至机器学习,做商业的你都应该有所了解。
其实,对程序员而言,还有一点收益就是,你在学习爬虫的过程中可以锻炼技术,虽然这个收益“看起来”性价比非常低,因为你没有能让一项技术来“work for yourself”。
最后,再谈一点我个人对爬虫的看法。如果你将来想从事爬虫相关的工作,除了了解爬虫外,你更应该多了解反爬虫、架构以及机器学习的相关知识。因为如果仅仅是爬虫的话,并不是很难,很多人都能学会。
在规模稍大一些的企业中,爬数据肯定不是只写个Python脚本,一般都有自己的爬虫架构,并以在线服务的形式存在,供他人调用。所以,除了学习爬虫,你还要学习架构和服务开发。
和获取数据相比,企业会更在意自己的数据是否安全、是否能被别人抓取,所以在反爬方面,投入的人力也比较多。
反爬是一件比较难的事情,具有一定的滞后性,因为当你识别出一个IP有问题的时候,或许别人已经爬完了数据换了IP,它难就难在这里。未来或许可以加入一些机器学习的手段,做一些分类器,在爬虫刚开始抓取的时候就识别出它的异常行为并及时封禁,这才有可能做到真正意义上的反爬。
本文作者: 二胖并不胖
本文来自云栖社区合作伙伴“大数据前沿”,了解相关信息可以关注“大数据前沿”