好了现在我们接着上一篇的随笔,继续来讲。上一篇我们讲到,我们如果要去更新所有微服务的配置,在不重启的情况下去更新配置,只能依靠spring cloud config了,但是,是我们要一个服务一个服务的发送post请求,
我们能受的了吗?这比之前的没配置中心好多了,那么我们如何继续避免挨个挨个的向服务发送Post请求来告知服务,你的配置信息改变了,需要及时修改内存中的配置信息。
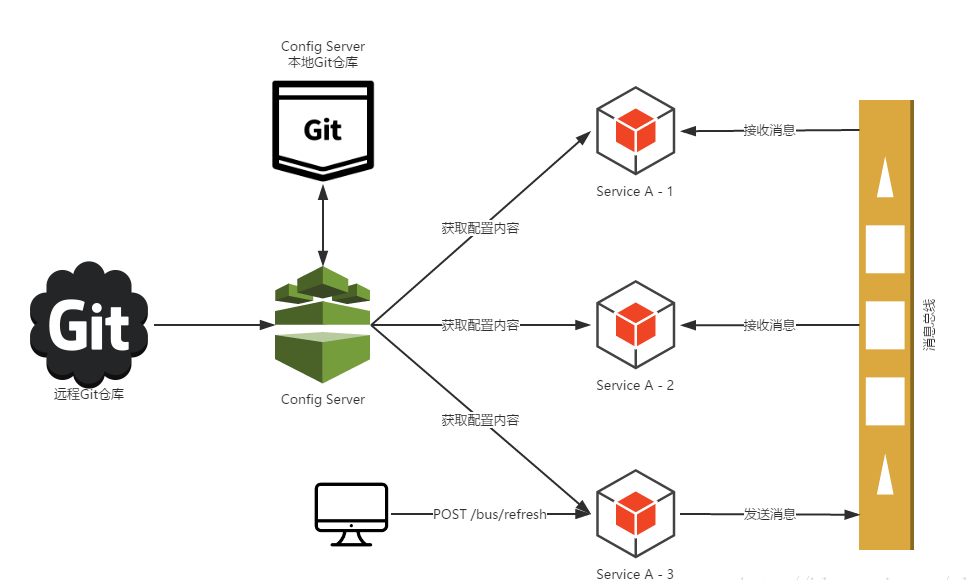
这时候我们就不要忘记消息队列的发布订阅模型。让所有为服务来订阅这个事件,当这个事件发生改变了,就可以通知所有微服务去更新它们的内存中的配置信息。这时Bus消息总线就能解决,你只需要在springcloud Config Server端发出refresh,就可以触发所有微服务更新了。
如下架构图所示:
![]()
Spring Cloud Bus除了支持RabbitMQ的自动化配置之外,还支持现在被广泛应用的Kafka。在本文中,我们将搭建一个Kafka的本地环境,并通过它来尝试使用Spring Cloud Bus对Kafka的支持,实现消息总线的功能。
Kafka使用Scala实现,被用作LinkedIn的活动流和运营数据处理的管道,现在也被诸多互联网企业广泛地用作为数据流管道和消息系统。
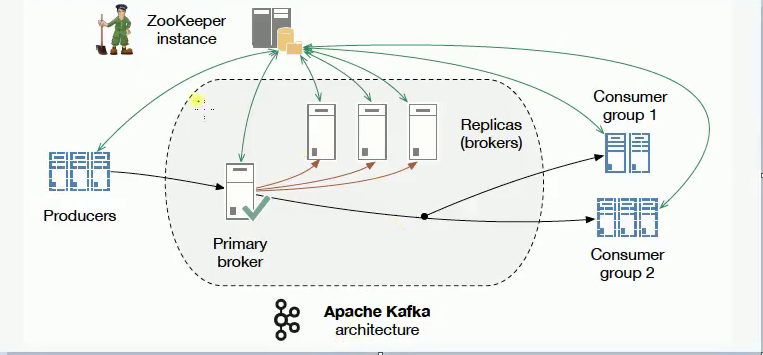
Kafak架构图如下:
![]()
Kafka是基于消息发布/订阅模式实现的消息系统,其主要设计目标如下:
1.消息持久化:以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
2.高吞吐:在廉价的商用机器上也能支持单机每秒100K条以上的吞吐量
3.分布式:支持消息分区以及分布式消费,并保证分区内的消息顺序
4.跨平台:支持不同技术平台的客户端(如:Java、PHP、Python等)
5.实时性:支持实时数据处理和离线数据处理
6.伸缩性:支持水平扩展
Kafka中涉及的一些基本概念:
1.Broker:Kafka集群包含一个或多个服务器,这些服务器被称为Broker。
2.Topic:逻辑上同Rabbit的Queue队列相似,每条发布到Kafka集群的消息都必须有一个Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个Broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
3.Partition:Partition是物理概念上的分区,为了提供系统吞吐率,在物理上每个Topic会分成一个或多个Partition,每个Partition对应一个文件夹(存储对应分区的消息内容和索引文件)。
4.Producer:消息生产者,负责生产消息并发送到Kafka Broker。
5.Consumer:消息消费者,向Kafka Broker读取消息并处理的客户端。
6.Consumer Group:每个Consumer属于一个特定的组(可为每个Consumer指定属于一个组,若不指定则属于默认组),组可以用来实现一条消息被组内多个成员消费等功能。
可以从kafka的架构图看到Kafka是需要Zookeeper支持的,你需要在你的Kafka配置里面指定Zookeeper在哪里,它是通过Zookeeper做一些可靠性的保证,做broker的主从,我们还要知道Kafka的消息是以topic形式作为组织的,Producers发送topic形式的消息,
Consumer是按照组来分的,所以,一组Consumers都会都要同样的topic形式的消息。在服务端,它还做了一些分片,那么一个Topic可能分布在不同的分片上面,方便我们拓展部署多个机器,Kafka是天生分布式的。
这里为了演示,我们只需要用它的默认配置,在windows上做个小Demo即可。
我们这里主要针对Spring Cloud Bus对Kafka的支持,实现消息总线的功能,具体的Kafka,RabbitMQ消息队列希望自己去找资料来学习一下。
有了一些概念的支持后,我们进行一些Demo。如下:
首先新建一个springCloud-config-client1模块,方便我们进行测试
所引入的依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
<version>1.4.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.3.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
接着要注意一下,client1的配置文件要改为bootstrap.yml,因为这种配置格式,是优先加载的,上一篇随笔有讲过,client1的配置如下:
server:
port: 7006
spring:
application:
name: cloud-config
cloud:
config:
#启动什么环境下的配置,dev 表示开发环境,这跟你仓库的文件的后缀有关,比如,仓库配置文件命名格式是cloud-config-dev.properties,所以profile 就要写dev
profile: dev
discovery:
enabled: true
#这个名字是Config Server端的服务名字,不能瞎写。
service-id: config-server
#注册中心
eureka:
client:
service-url:
defaultZone: http://localhost:8888/eureka/,http://localhost:8889/eureka/
#是否需要权限拉去,默认是true,如果不false就不允许你去拉取配置中心Server更新的内容
management:
security:
enabled: false
接着启动类如下:
@SpringBootApplication
@EnableDiscoveryClient
public class Client1Application {
public static void main(String[] args) {
SpringApplication.run(Client1Application.class, args);
}
}
接着将client中的TestController赋值一份到client1中,代码如下:
@RestController
//这里面的属性有可能会更新的,git中的配置中心变化的话就要刷新,没有这个注解内,配置就不能及时更新
@RefreshScope
public class TestController {
@Value("${name}")
private String name;
@Value("${age}")
private Integer age;
@RequestMapping("/test")
public String test(){
return this.name+this.age;
}
}
接着还要在先前的随笔中的模块中的Config Server加入如下配置:
#是否需要权限拉去,默认是true,如果不false就不允许你去拉取配置中心Server更新的内容
management:
security:
enabled: false
接着还要做一点就是,在config-client,config-client1,和config-Server都要引入kafka的依赖,如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
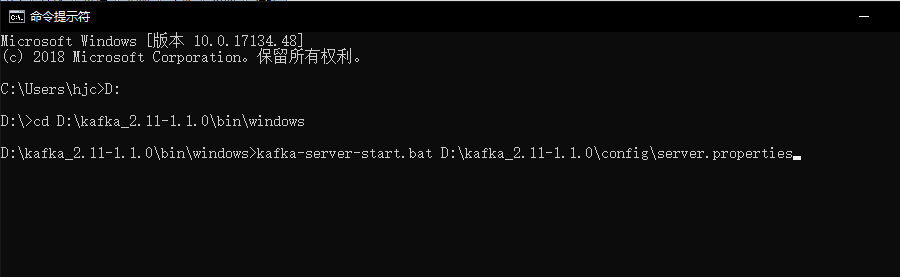
我们工程准备好了,暂时先放在这里,下面进行Kafka的安装下载,首先我们去Kafka官网kafka.apache.org/downloads 下来官网推荐的版本,
![]()
首先我们进到下载好的Kafka目录中kafka_2.11-1.1.0\bin\windows 下编辑kafka-run-class.bat如下:
找到这条配置 如下:
set COMMAND=%JAVA% %KAFKA_HEAP_OPTS% %KAFKA_JVM_PERFORMANCE_OPTS% %KAFKA_JMX_OPTS% %KAFKA_LOG4J_OPTS% -cp %CLASSPATH% %KAFKA_OPTS% %*
可以看到%CLASSPATH%没有双引号,
因此用双引号括起来,不然启动不起来的,报你JDK没安装好,修改后如下:
set COMMAND=%JAVA% %KAFKA_HEAP_OPTS% %KAFKA_JVM_PERFORMANCE_OPTS% %KAFKA_JMX_OPTS% %KAFKA_LOG4J_OPTS% -cp "%CLASSPATH%" %KAFKA_OPTS% %*
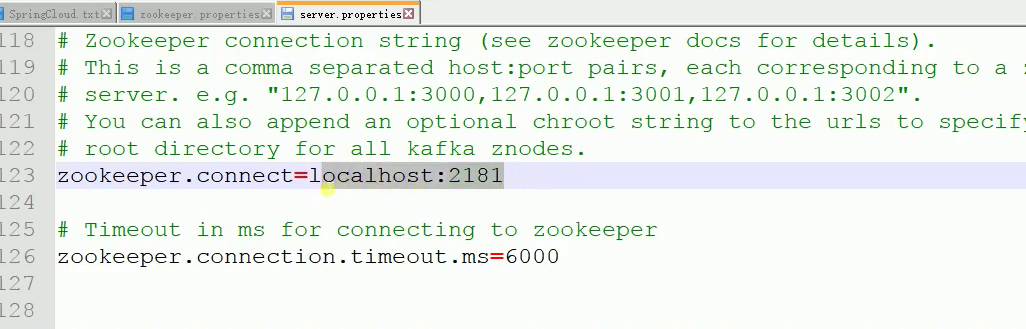
接着,打开config文件夹中的server.properties配置如下:
![]()
可以看到是连接到本地的zookeeper就行了。
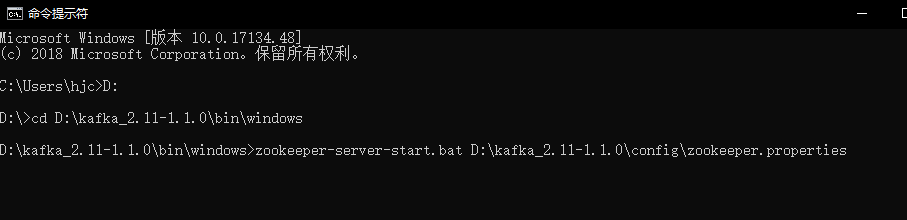
接着我们进行先启动zookeeper,再启动Kafka,如下:
![]()
![]()
![]()
当看到上面的信息证明启动Zookeeper启动成功。、
接下来再开一个CMD启动Kafka,如下:
![]()
![]()
看到这些信息说明Kafka启动成功了
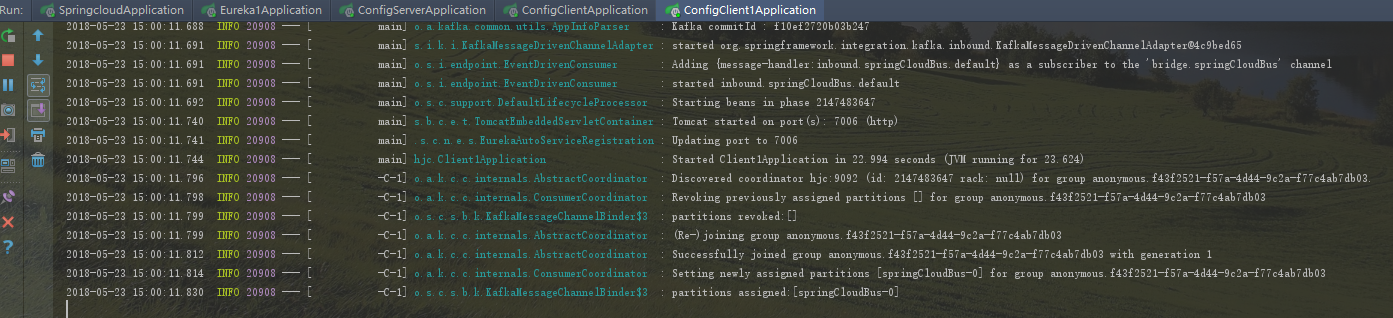
好了,接下来把前面的工程,两个注册中心,一个springcloud-config-server,两个springcloud-config-client,springcloud-config-client1启动起来,
![]()
![]()
可以看到springcloudBus是在0分片上,如果两个config-client启动都出现上面信息,证明启动成功了。
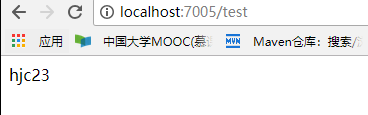
好了现在我们进行访问一下config-server端,如下:
![]()
再访问两个client,如下:
![]()
![]()
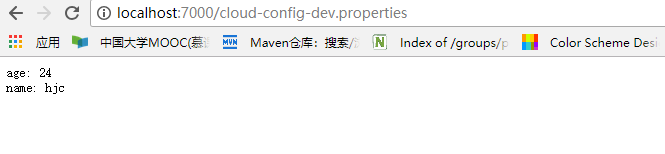
好了,好戏开始了,现在我们去git仓库上修改配置中心的文件,将年龄改为24,如下:
![]()
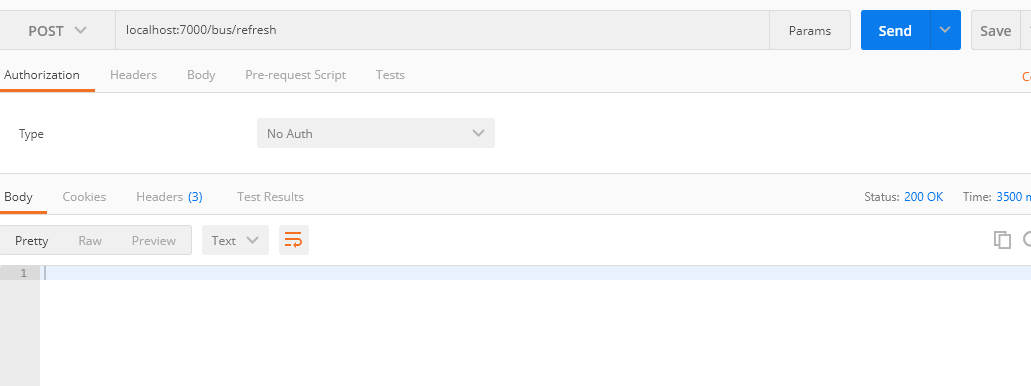
接下来,我们我们用refresh刷新配置服务端配置,通知两个client去更新内存中的配置信息。用postman发送localhost:7000/bus/refresh,如下:
![]()
可以看到没有返回什么信息,但是不要担心,这是成功的通知所有client去更新了内存中的信息了。
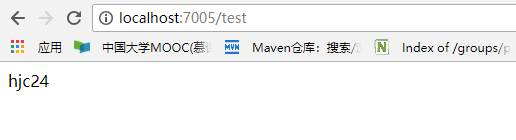
接着我们分别重新请求config-server,两个client,刷新页面,结果如下:
![]()
两个client如下:
![]()
![]()
可以看到所有client自动更新内存中的配置信息了。
到目前为止,上面都是刷新说有的配置的信息的,如果我们想刷新某个特定服务的配置信息也是可以的。我们可以指定刷新范围,如下:
指定刷新范围
上面的例子中,我们通过向服务实例请求Spring Cloud Bus的/bus/refresh接口,从而触发总线上其他服务实例的/refresh。但是有些特殊场景下(比如:灰度发布),我们希望可以刷新微服务中某个具体实例的配置。
Spring Cloud Bus对这种场景也有很好的支持:/bus/refresh接口还提供了destination参数,用来定位具体要刷新的应用程序。比如,我们可以请求/bus/refresh?destination=服务名字:9000,此时总线上的各应用实例会根据destination属性的值来判断是否为自己的实例名,
若符合才进行配置刷新,若不符合就忽略该消息。
destination参数除了可以定位具体的实例之外,还可以用来定位具体的服务。定位服务的原理是通过使用Spring的PathMatecher(路径匹配)来实现,比如:/bus/refresh?destination=customers:**,该请求会触发customers服务的所有实例进行刷新。