Elastic Stack介绍
近几年,互联网生成数据的速度不断递增,为了便于用户能够更快更精准的找到想要的内容,站内搜索或应用内搜索成了不可缺少了的功能之一。同时,企业积累的数据也再不断递增,对海量数据分析处理、可视化的需求也越来越高。
在这个领域里,开源项目ElasticSearch赢得了市场的关注,比如,去年Elastic公司与阿里云达成合作伙伴关系提供阿里云 Elasticsearch 的云服务、今年10月Elastic公司上市,今年11月举行了Elastic 中国开发者大会、目前各大云厂商几乎都提供基于Elasticsearch的云搜索服务,等等这些事件,都反映了Elasticsearch在企业的应用越来越普遍和重要。
先来看看官网的介绍,ok,核心关键字:搜索、分析。
Elasticsearch is a distributed, RESTful search and analytics engine
capable of solving a growing number of use cases. As the heart of the
Elastic Stack, it centrally stores your data so you can discover the
expected and uncover the unexpected.
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic
Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
产品优势:速度快、可扩展性、弹性、灵活性。
在某些应用场景中,不仅会使用Elasticsearch,还会使用Elastic旗下的其他产品,比如Kibana、Logstash等,常见的ELK指的就是Elasticsearch、Logstash、Kibana这三款产品,Elastic Stack指的是Elastic旗下的所有开源产品。
应用场景:(图片截于Elastic官网)

场景实战
接下来,我们来实战一个应用场景。
场景:一个后端应用部署在一台云服务器中,后端应用会以文件形式记录日志。需求为:收集日志内容,对每行日志解析,得到结构化数据,便于搜索、处理与可视化。
方案:使用Filebeat转发日志到Logstash,后者解析或转换数据,然后转发到Elasticsearch储存,接着数据就任君处理了,这里我们把日志数据根据某些需求进行可视化,可视化的活就交给Kibana完成。(另种方案也可:通过Filebeat将日志数据直接转发到Elasticsearch,由Elasticsearch Ingest node负责数据的数据处理)
所需软件
本案例使用的产品版本如下:
系统:CentOS,这里分开部署了,也可以放在一起。
1、Kibana_v6.2.3 (IP: 192.168.0.26)
2、Elasticsearch_v6.2.3 (IP: 192.168.0.26)
3、Filebeat_v6.2.3 (IP: 192.168.0.25)
4、Logstash_v6.2.3 (IP: 192.168.0.25)
日志内容
假设一行日志内容如下:(日志文件放在/root/logs目录下)
其中一行日志内容如下:
2018-11-08 20:46:25,949|https-jsse-nio-10.44.97.19-8979-exec-11|INFO|CompatibleClusterServiceImpl.getClusterResizeStatus.resizeStatus=|com.huawei.hwclouds.rds.trove.api.service.impl.CompatibleClusterServiceImpl.getResizeStatus(CompatibleClusterServiceImpl.java:775)
一行日志中可得到5个字段,以“|”分割
2018-11-08 20:46:25,949| #时间
https-jsse-nio-10.44.97.19-8979-exec-11| # 线程名称
INFO| # 日志级别
CompatibleClusterServiceImpl.getClusterResizeStatus.resizeStatus=| # 日志内容
trove.api.service.impl.CompatibleClusterServiceImpl.getResizeStatus(CompatibleClusterServiceImpl.java:775) # 类名
文件目录如下:(Elasticsearch和Kibana在另一台服务器,且已启动)
![]()
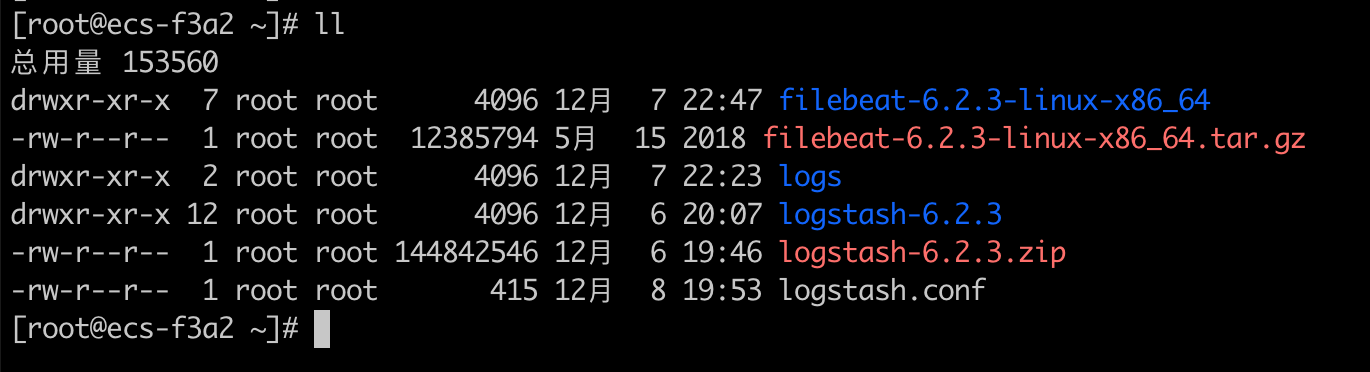
Logstash配置
logs目录存放需要收集的应用日志,logstash.conf 为Logstash准备的配置文件。
logstash.conf内容如下:
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{GREEDYDATA:Timestamp}\|%{GREEDYDATA:ThreadName}\|%{WORD:LogLevel}\|%{GREEDYDATA:TextInformation}\|%{GREEDYDATA:ClassName}" }
}
date {
match => [ "Timestamp", "yyyy-MM-dd HH:mm:ss,SSS" ]
}
}
output {
elasticsearch {
hosts => "192.168.0.26:9200"
manage_template => false
index => "java_log"
}
}
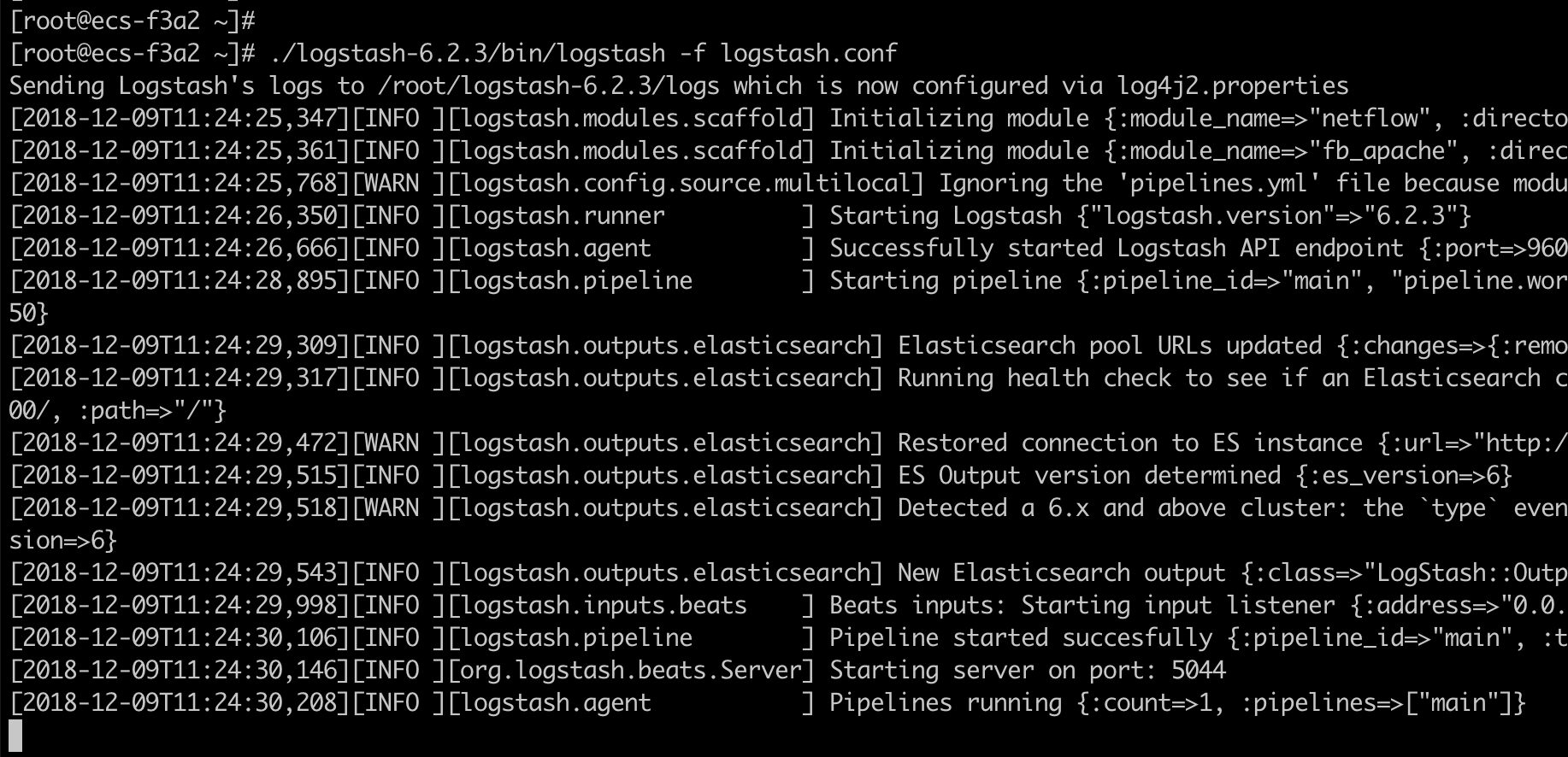
接下来启动Logstash(启动成功,监听5044端口,等待日志数据传入):
![]()
Filebeat配置
接下来看下Filebeat的配置文件:
filebeat.prospectors:
- type: log
enabled: true
# 配置日志目录的路径或者日志文件的路径
paths:
- /root/logs/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
setup.kibana:
host: "192.168.0.26:5601"
# 配置output为logstash
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
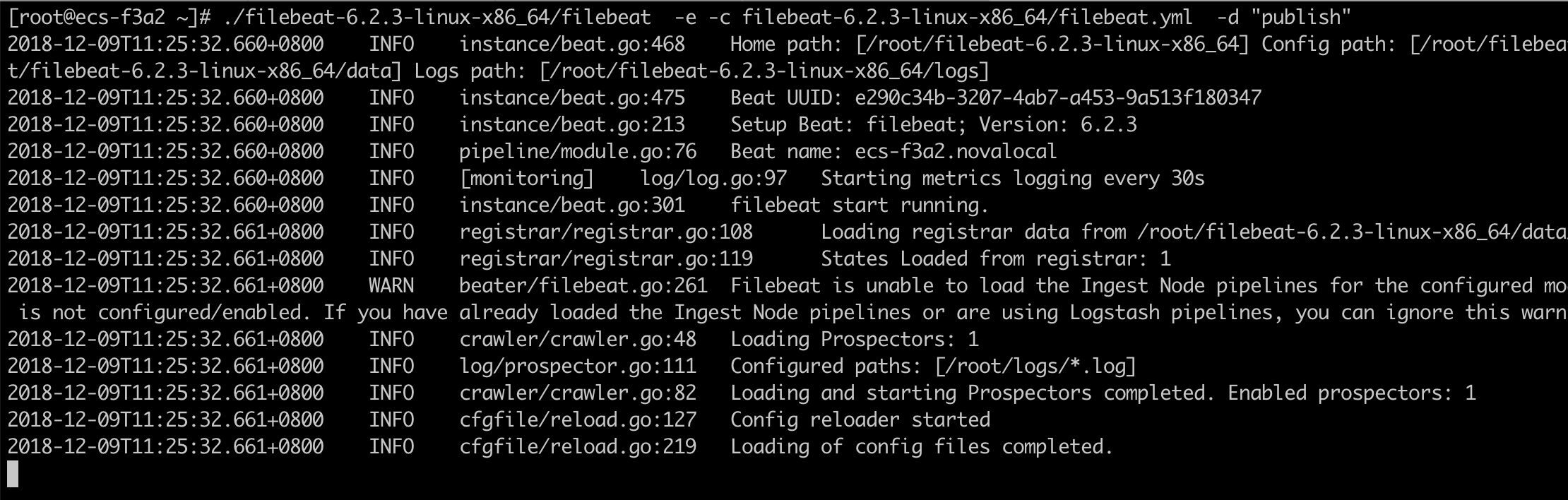
启动Filebeat:(当日志文件有更新时,会被Filebeat监听到,被转发出去。)
![]()
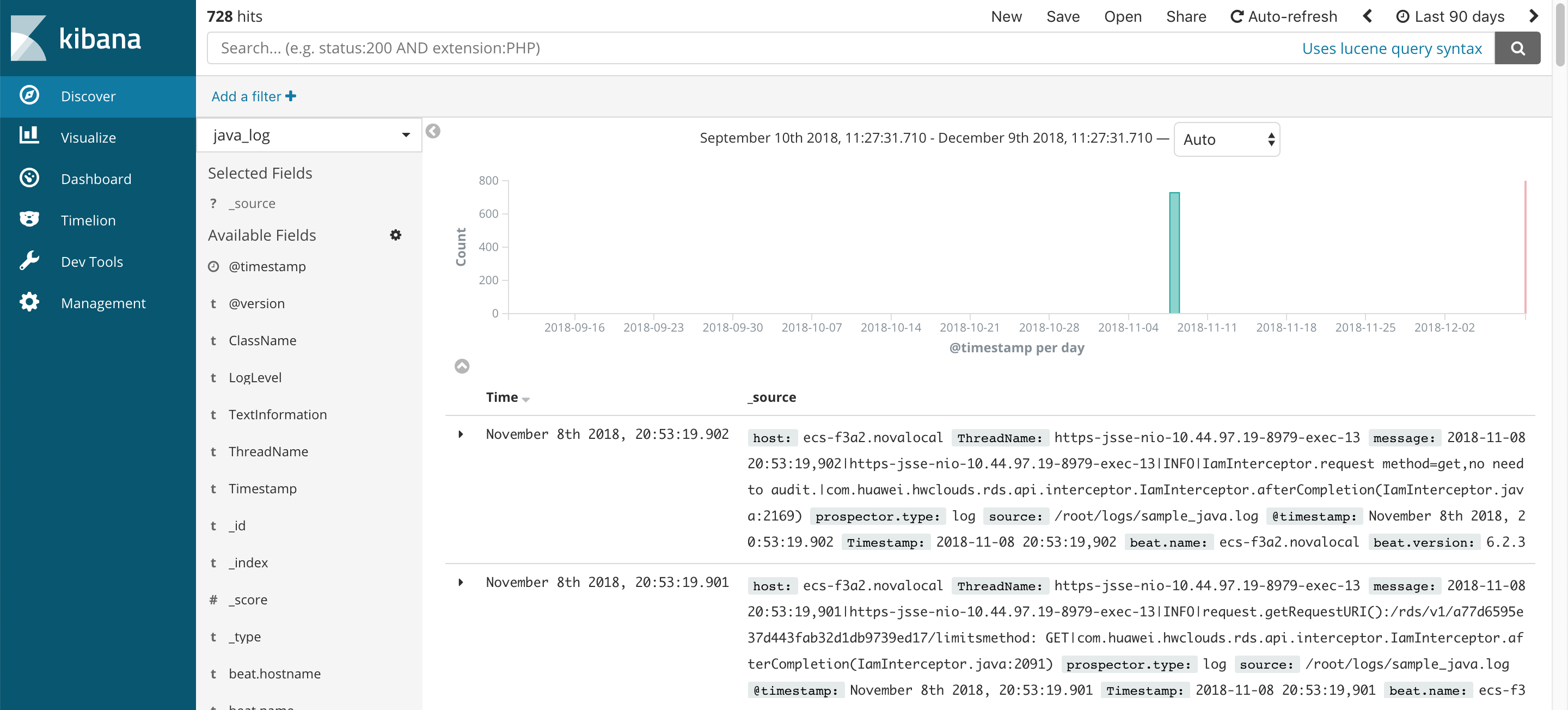
日志查询和可视化
最后来看看Kibana,进行日志的可视化。在Kibana创建好index pattern,这里命名为:java_log。在Discover页面中对日志数据进行查询。
![]()
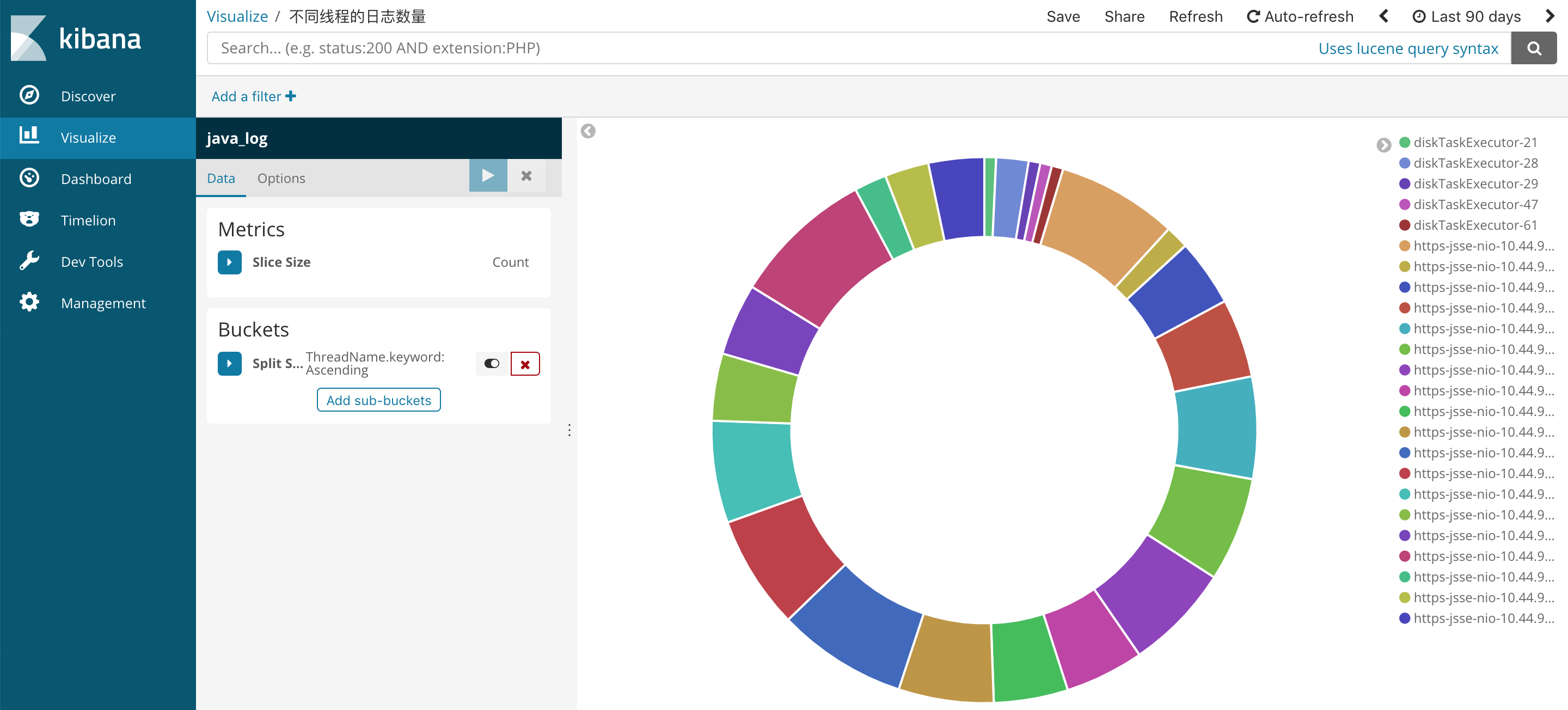
在Visualize中创建可视化图形。
![]()
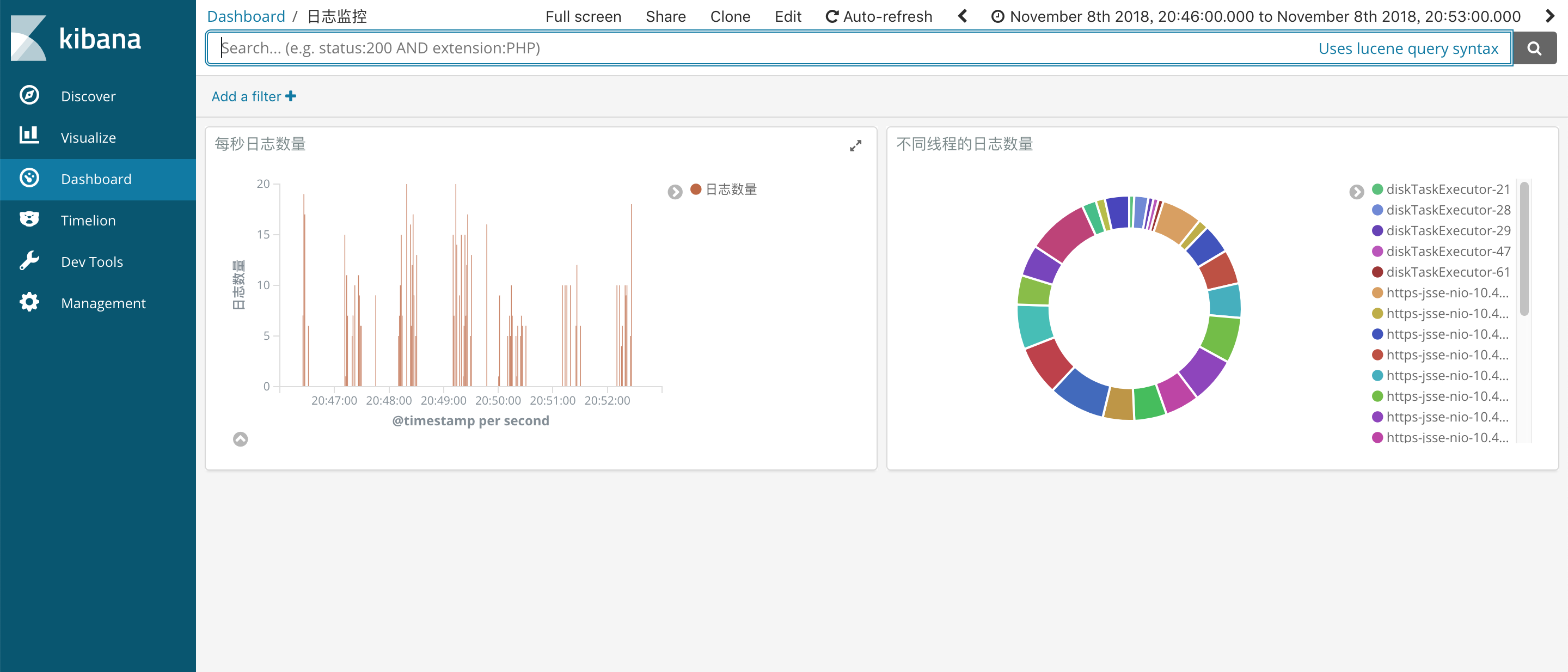
在Dashboard中组合我们的图形。
![]()
到此,就完成一个简单的日志数据的收集、分析、可视化。
Elastic Stack还有很多强大的功能,后面我们来一个应用内搜索案例。
参考资料
- https://www.elastic.co/cn/blog/alibaba-cloud-to-offer-elasticsearch-kibana-and-x-pack-in-china 阿里云与Elastic公司合作
- https://www.elastic.co/guide/en/beats/libbeat/6.2/getting-started.html beat入门
- https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html grok插件
公众号:码农阿呆 (欢迎关注和交流)