一、背景介绍
随着淘宝内容化的深入发展,实时选品的需求越来越强烈。对于某些实时性要求较高的产品(SPU)而言,运营小二希望自己圈定产品池可以当天实时生效,以供创作者写文章使用。该需求对选品的实时性要求较高,比较适合流式计算的特点。因此,本文采用Blink实时流计算技术来实现该功能,实际应用中取得较好效果。
二、解决方案
2.1 问题分析
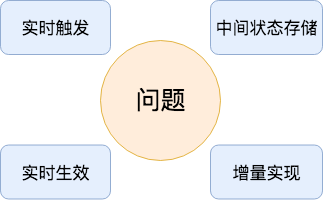
要实现实时选品的需求,需要解决如下几个问题:
-
实时触发问题:流计算必须要有触发数据源,用户提交的特征数据存储在idb中,idb如何与Blink计算流程建立关联?
-
中间状态存储问题:Blink计算过程中,依据业务场景需要记录上一次中间计算状态,如何存储这些中间状态,并在需要时实时读取?
-
实时生效问题:Blink计算结果需要最终在搜索引擎生效,Blink如何跟搜索引擎交互,使计算结果实时生效?
-
增量问题:如果没有增量过程,离线全量切换数据期间,会覆盖部分已更新的数据,入如何增量追数据?
针对上述问题,可采用TT+Blink+Hbase+Swift的方式解决。流程中引入TT可解决实时触发问题,引入Hbase解决中间存储问题,引入Swift解决实时生效和增量问题。TT、Hbase和Swift介绍如下:
-
TT日志:阿里日志采集系统,用户可以对日志进行订阅,TT与idb(数据库)、Blink有较好支持,是idb和Blink交互的重要媒介。
-
Hbase:开源的非关系型分布式数据库,与Blink有较好的接口交互,可用于存储和读取中间计算状态。
-
Swift:阿里搜索事业部自主研发的消息系统,目前主搜索实时都是基于该系统进行消息传输的,可基于该系统解决引擎实时生效和增量问题。
2.2 实现流程
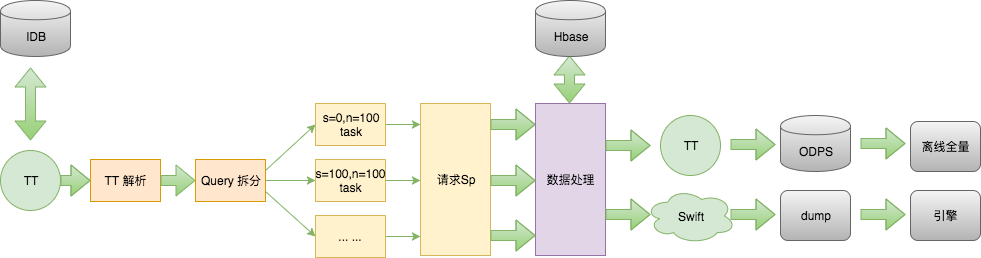
Blink流程被分为“日志解析节点”、“Query拆分节点”、“请求SP服务节点”、“数据处理节点”、“回写TT节点”、“Swift消息节点”6个节点,每次实时计算大致经历如下几部分:
-
用户提交选品特征数据,数据保存到idb(数据库)并同步到TT日志。
-
TT日志更新会触发Blink任务,日志解析节点会先解析TT日志,获取选品特征数据。
-
Query拆分节点先预估SPU数量,然后根据SPU数量确定并发请求数,并拼接Sp参数。
-
请求Sp服务节点并发请求Sp服务,获取SPU信息。
-
数据计算节点从Hbase中读取中间状态数据,根据业务逻辑进行计算。
-
计算结果回写Hbase数据库,用于下次计算使用。
-
回写TT节点和Swift消息节点同时回写TT和Swift。
-
dump接受Swift消息,将数据更新至引擎,实现数据实时生效。
-
TT记录计算结果,回写ODPS,用于离线全量计算。
2.3 实现细节
选品功能的实现主要在于Blink任务的开发,开发Blink任务前,需先了解UDF、UDTF、UDAF的概念。
Blink开发主要集中在UDF的实现上,首先根据流计算的过程,划分出多个计算节点(例如实现流程中的“Query拆分节点”和“请求Sp节点”都是独立的计算节点),然后针对每个节点的实现逻辑,确定UDF分类,实现UDF类。以“请求Sp节点”为例说明具体实现过程:
-
节点分析:“请求Sp节点”的业务场景是一个“一对多”的过程,因此采用UDTF类型实现。
-
封装UDTF类:该类需要继承TableFunction,其中T为自己定义的pojo,用于向下个运行节点传递。
-
节点输出:需要定义自己的Pojo类(上一步提到的T),这样节点的输出才能在下个节点中看到。
-
主函数流程串联:Blink开发流程需要一个主函数将各个计算节点关联起来,达到流计算的目的,建议主函数用Scala语言开发,代码更加通俗易懂。
2.4 参考代码
以下是“请求Sp节点”的UDTF实现代码,基本思路是将请求Sp的返回结果并发输出到下一级节点上。
public class SearchEngineUdtf extends TableFunction<EngineFields> {
private static final Logger logger = LoggerFactory.getLogger(SearchEngineUdtf.class);
/**
* 请求引擎获取召回字段
* @param params
*/
public void eval(String params) {
SpuSearchResult<String> spuSearchResult = SpuSearchEngineUtil.getFromSpuSearch(params);
if(spuSearchResult.getSuccess()){
//结果解析
JSONObject kxuanObj = SpuSearchEngineUtil.getSpResponseJson(spuSearchResult, "sp_kxuan");
if(null == kxuanObj || kxuanObj.isEmpty()){
logger.error("sp query: " + spuSearchResult.getSearchURL());
logger.error(String.format("[%s],%s", Constant.ERR_PAR_SP_RESULT,"get key:sp_kxuan data failed! "));
}else {
List<EngineFields> engineFieldsList = SpuSearchEngineUtil.getSpAuction(kxuanObj);
//并发输出到数据流
for(EngineFields engineFields : engineFieldsList){
collect(engineFields);
}
}
}else {
logger.error(String.format("[%s],%s",Constant.ERR_REQ_SP, "request SpuEngine failed!"));
}
}
}
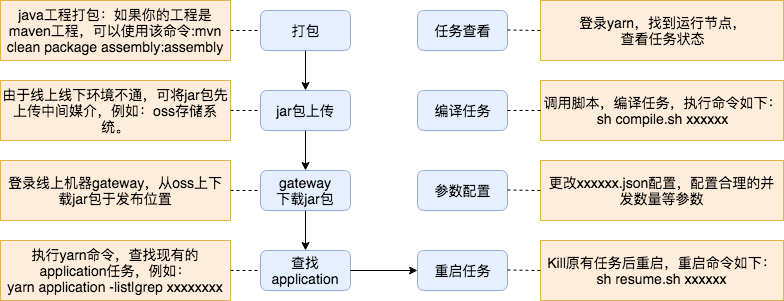
2.5 运维发布
目前,集群发布Blink任务并未完全实现自动化,Blink任务开发完成后,发布上线流程需要如上几步完成。任务发布完成后,可登录yarn上查看任务节点的运行情况。
三、成果总结
功能发布上线后,运营小二圈定的万级别的SPU选品池,可实现分钟级生效,对创作者选品效率有很大提升。
四、作者简介
作者:崔庆磊,花名:辰昕,阿里巴巴-搜索事业部-搜索系统服务平台-高级开发工程师。
15年加入阿里,主要从事内容化选品服务端开发相关工作,熟悉搜索引擎服务及流式计算等相关技术。
如果您有实时报表/实时数据大屏/实时金融风控/实时电商推荐等相关实时化数据处理需求,可以加入如下钉钉交流群!