一、简单使用
cd logstash_HOME
bin/logstash -e 'input { stdin { } } output { stdout {} }'
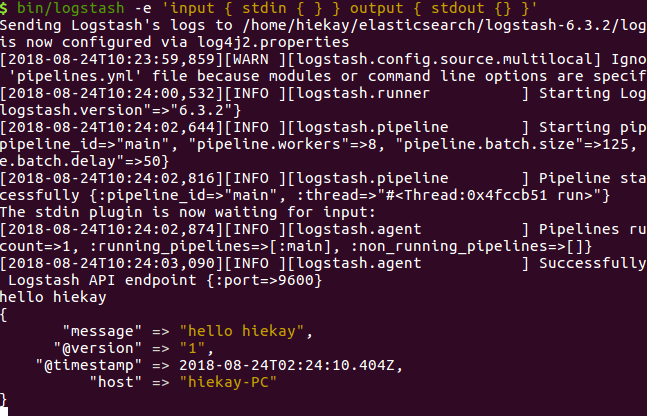
启动 Logstash 后,再键入 Hello hiekay,结果如下:
在生产环境中,Logstash 的管道要复杂很多,可能需要配置多个输入、过滤器和输出插件。
因此,需要一个配置文件管理输入、过滤器和输出相关的配置。配置文件内容格式如下:
# 输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}
二、配置使用 插件用法
在使用插件之前,我们先了解一个概念:事件。
Logstash 每读取一次数据的行为叫做事件。
在 Logstach_HOME 目录中创建一个配置文件,名为 logstash.conf(名字任意)。
- 1、 输入插件
输入插件允许一个特定的事件源可以读取到 Logstash 管道中,配置在 input {} 中,且可以设置多个。
修改配置文件:
input {
# 从文件读取日志信息
file {
path => "/var/log/syslog"
type => "system"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
stdout { codec => rubydebug }
}
其中,syslog 为系统日志。保存文件。
运行
bin/logstash -f logstash.conf
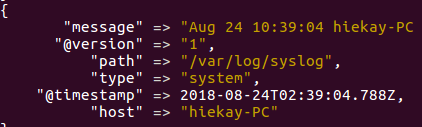
在控制台结果如下:
- 2、 输出插件
输出插件将事件数据发送到特定的目的地,配置在 output {} 中,且可以设置多个。
修改配置文件:
input {
# 从文件读取日志信息
file {
path => "/var/log/syslog"
type => "error"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 输出到 elasticsearch
elasticsearch {
hosts => ["127.0.0.1:9201"]
index => "syslog-%{+YYYY.MM.dd}"
}
}
配置文件中使用 elasticsearch 输出插件。输出的日志信息将被保存到 Elasticsearch 中,索引名称为 index 参数设置的格式。保存文件。
运行
bin/logstash -f logstash.conf
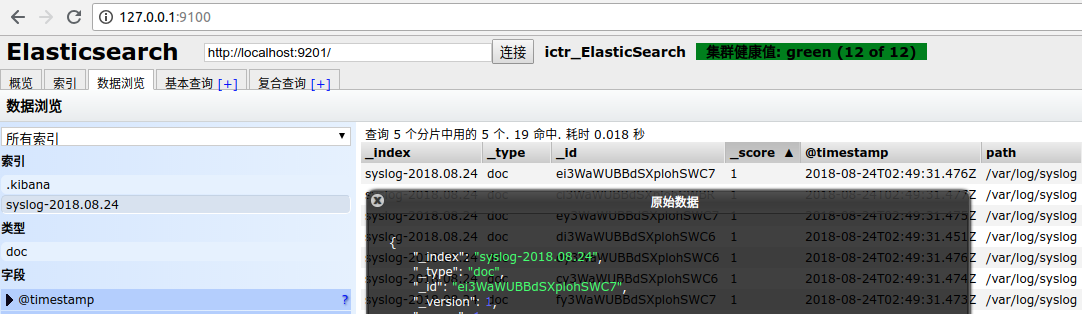
- 打开浏览器访问 http://127.0.0.1:9100 使用 head 插件查看 Elasticsearch 数据,结果如下图:
- 3、 编码解码插件
编码解码插件本质是一种流过滤器,配合输入插件或输出插件使用。
从上图中,我们发现一个问题:Java 异常日志被拆分成单行事件记录到 Elasticsearch 中,这不符合开发者或运维人员的查看习惯。因此,我们需要对日志信息进行编码将多行事件转成单行事件记录起来。
我们需要配置 Multiline codec 插件,这个插件可以将多行日志信息合并成一行,作为一个事件处理。
Logstash 默认没有安装该插件,需要开发者自行安装。
bin/logstash-plugin install logstash-codec-multiline
修改配置文件:
input {
# 从文件读取日志信息
file {
path => "/var/log/syslog"
type => "error"
start_position => "beginning"
# 使用 multiline 插件
codec => multiline {
# 通过正则表达式匹配,具体配置根据自身实际情况而定
pattern => "^\d"
negate => true
what => "previous"
}
}
}
# filter {
#
# }
output {
# 输出到 elasticsearch
elasticsearch {
hosts => ["127.0.0.1:9201"]
index => "syslog-%{+YYYY.MM.dd}"
}
}
保存文件。
bin/logstash -f logstash.conf
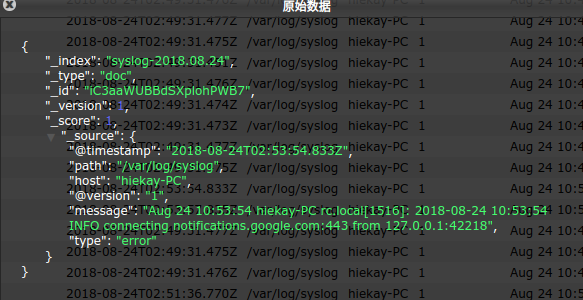
使用 head 插件查看 Elasticsearch 数据,结果如下图:
- 4 过滤器插件
过滤器插件位于 Logstash 管道的中间位置,对事件执行过滤处理,配置在 filter {},且可以配置多个。
本次测试使用 grok 插件演示,grok 插件用于过滤杂乱的内容,将其结构化,增加可读性。
安装:
bin/logstash-plugin install logstash-filter-grok
修改配置文件:
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER
:duration}" }
}
}
output {
stdout {
codec => "rubydebug"
}
}
保存文件。
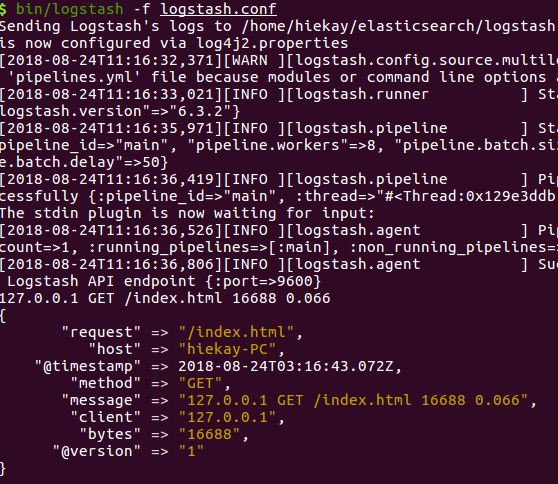
bin/logstash -f logstash.conf
启动成功后,我们输入:
127.0.0.1 GET /index.html 16688 0.066
控制台返回:
输入的内容被匹配到相应的名字中。