HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。
适合于存储大表数据(表的规模可以达到数十亿行以及数百万列),并且对大表数据的读、写访问可以达到实时级别;
利用Hadoop HDFS(Hadoop Distributed File System)作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统;
利用ZooKeeper作为协同服务。
与RMDB比较:
HBase
分布式存储,面向列。
动态扩展列。
普通商用硬件支持,扩容成本低。
RMDB
数据结构固定。
需要预先定义好数据结构。
需要大量IO,扩展成本大。
HBase适合具有如下需求的应用:
海量数据(TB、PB)
高吞吐量
需要在海量数据中实现高效的随机读取
需要很好的性能伸缩能力
能够同时处理结构化和非结构化的数据
不需要完全拥有传统关系型数据库所具备的ACID特性
数据结构介绍:
-
结构化数据
-
具有固定的结构,属性划分,以及类型等信息。我们通常所理解的关系型数据库中所存储的数据信息,大多是结构化数据, 如职工信息表,拥有ID、Name、Phone、Address等属性信息。
通常直接存放在数据库表中。数据记录的每一个属性对应数据表的一个字段。
-
非结构化数据
-
无法用统一的结构来表示,如文本文件、图像、视频、声音、网页等信息。
数据记录较小时(如KB级别),可考虑直接存放到数据库表中(整条记录映射到某一个列中),这样也有利于整条记录的快速检索。
数据较大时,通常考虑直接存放在文件系统中。数据库可用来存放相关数据的索引信息。
-
半结构化数据
-
具有一定的结构,但又有一定的灵活可变性。典型如XML、HTML等数据。其实也是非结构化数据的一种。
可以考虑直接转换成结构化数据进行存储。
根据数据记录的大小和特点,选择合适的存储方式。这一点与非结构化数据的存储类似。
-
行列存储:
-
按行存储:
-
数据按行存储在底层文件系统中。通常,每一行会被分配固定的空间。
优点:有利于增加/修改整行记录等操作;有利于整行数据的读取操作;
缺点:单列查询时,会读取一些不必要的数据。
-
按列存储:
-
数据以列为单位,存储在底层文件系统中。
优点:有利于面向单列数据的读取/统计等操作。
缺点:整行读取时,可能需要多次I/O操作。
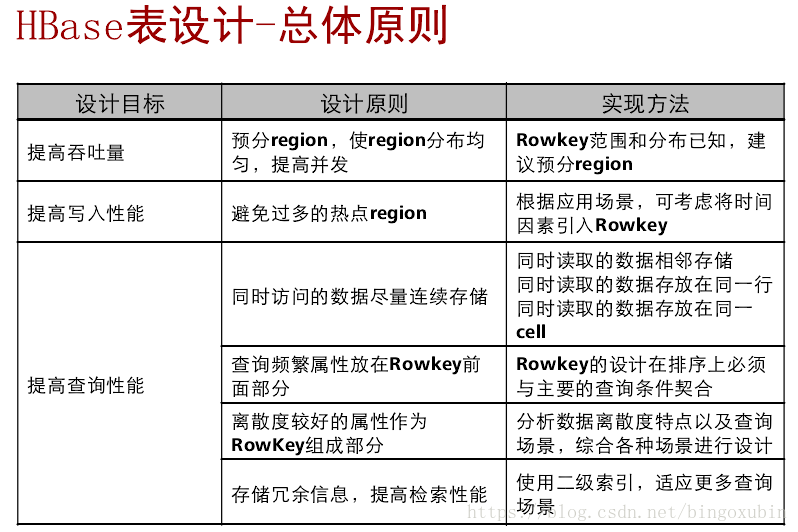
主键设置规则:
![这里写图片描述]()
Secondary Index
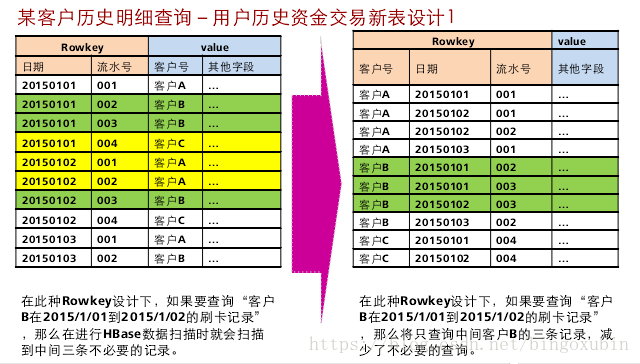
HBase是一个Key-Value类型的分布式存储数据库。每张表的数据,是按照RowKey的字典顺序排序的,因此,如果按照某个指定的RowKey去查询数据,或者指定某一个RowKey范围去扫描数据时,HBase可以快速定位到需要读取的数据位置,从而可以高效地获取到所需要的数据。
在实际应用中,很多场景是查询某一个列值为XXX的数据。HBase提供了Filter特性去支持这样的查询,它的原理是:按照RowKey的顺序,去遍历所有可能的数据,再依次去匹配那一列的值,直到获取到所需要的数据。可以看出,可能仅仅为了获取一行数据,它却扫描了很多不必要的数据。因此,如果对于这样的查询请求非常频繁并且对查询性能要求较高,使用Filter无法满足这个需求。
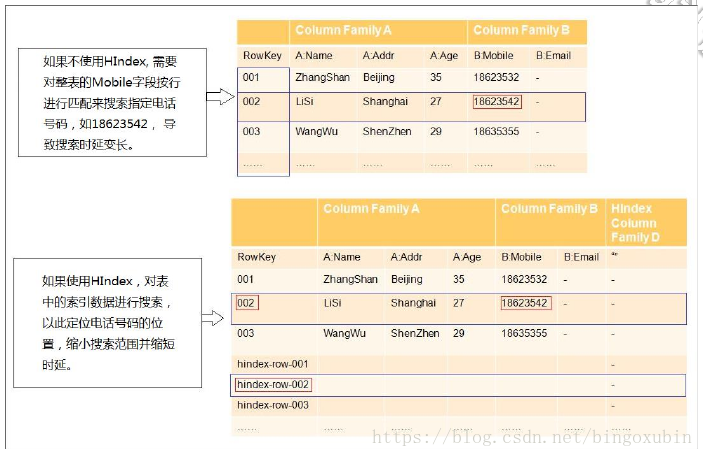
这就是HBase二级索引产生的背景。二级索引为HBase提供了按照某些列的值进行索引的能力。
![这里写图片描述]()
一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowKey中显然不太可能),或者全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题。
对于HBase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询。如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄。对于较大的表,全表扫瞄的代价是不可接受的。
但是,很多情况下,需要从多个角度查询数据。例如,在定位某个人的时候,可以通过姓名、身份证号、学籍号等不同的角度来查询,要想把这么多角度的数据都放到rowkey中几乎不可能(业务的灵活性不允许,对rowkey长度的要求也不允许)。
所以,需要secondary index来完成这件事。secondary index的原理很简单,但是如果自己维护的话则会麻烦一些。现在,Phoenix已经提供了对HBase secondary index的支持,下面将说明这样用Phoenix来在HBase中创建二级索引。
create index my_index on example (m.c0);
HBase FileStream
HBase文件存储模块(HBase FileStream,简称HFS)是HBase的独立模块,它作为对HBase与HDFS接口的封装,应用在FusionInsight HD的上层应用,为上层应用提供文件的存储、读取、删除等功能。
在Hadoop生态系统中,无论是HDFS,还是HBase,均在面对海量文件的存储的时候,在某些场景下,都会存在一些很难解决的问题:
如果把海量小文件直接保存在HDFS中,会给NameNode带来极大的压力。
由于HBase接口以及内部机制的原因,一些较大的文件也不适合直接保存到HBase中。
HFS的出现,就是为了解决需要在Hadoop中存储海量小文件,同时也要存储一些大文件的混合的
场景。简单来说,就是在HBase表中,需要存放大量的小文件(10MB以下),同时又需要存放一
些比较大的文件(10MB以上)。
HFS为以上场景提供了统一的操作接口,这些操作接口与HBase的函数接口类似。
注意事项
如果只有小文件,确定不会有大文件的场景下,建议使用HBase的原始接口进行操作。
HFS接口需要同时对HBase和HDFS进行操作,所以客户端用户需要同时拥有这两个组件的操作权限。
直接存放在HDFS中的大文件,HFS在存储时会加入一些元数据信息,所以存储的文件不是直接等于原文件的。不能直接从HDFS中移动出来使用,而需要用HFS的接口进行读取。
使用HFS接口存储在HDFS中的数据,暂不支持备份与容灾。
![这里写图片描述]()
HBASE+Solr全文检索
背景
某电信项目中采用HBase来存储用户终端明细数据,供前台页面即时查询。HBase无可置疑拥有其优势,但其本身只对rowkey支持毫秒级的快速检索,对于多字段的组合查询却无能为力。针对HBase的多条件查询也有多种方案,但是这些方案要么太复杂,要么效率太低,本文只对基于Solr的HBase多条件查询方案进行测试和验证。
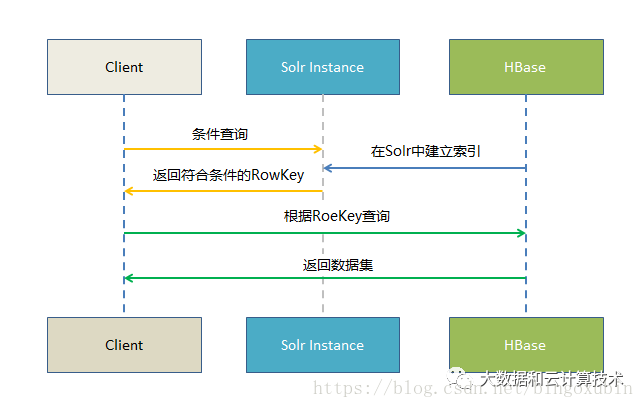
原理
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
![这里写图片描述]()
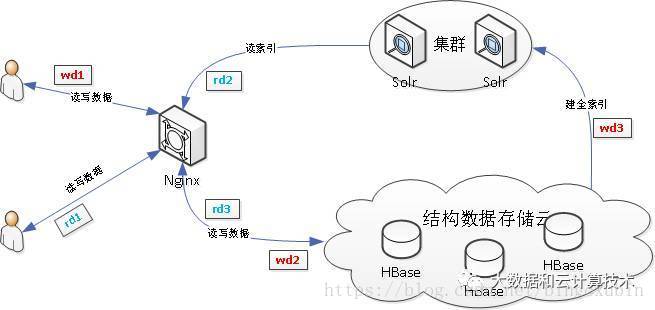
HBase与Solr系统架构设计
使用HBase搭建结构数据存储云,用来存储海量数据;使用SolrCloud集群用来搭建搜索引擎,将要查找的结构化数据的ID查找出来,只配置它存储ID。
![这里写图片描述]()
wd代表用户write data写数据,从用户提交写数据请求wd1开始,经历wd2,写入MySQL数据库,或写入结构数据存储云中,wd3,提交到Solr集群中,从而依据业务需求创建索引。
rd代表用户read data读数据,从用户提交读数据请求rd1开始,经历rd2,直接读取MySQL中数据,或向Solr集群请求搜索服务,rd3,向Solr集群请求得到的搜索结果为ID,再向结构数据存储云中通过ID取出数据,最后返回给用户结果。
实现方法有两种
手工编码,直接用HBASE的API,可以参考下文
http://www.cnblogs.com/chenz/articles/3229997.html
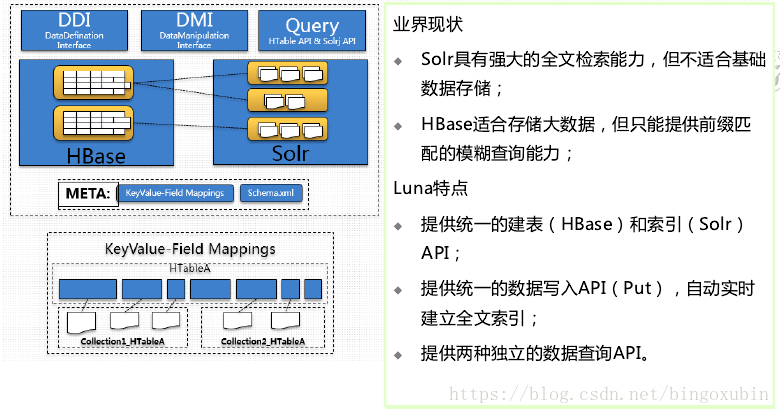
可以使用HBASE/Solr的LUNA接口,就不用自己管理两者。
![这里写图片描述]()