
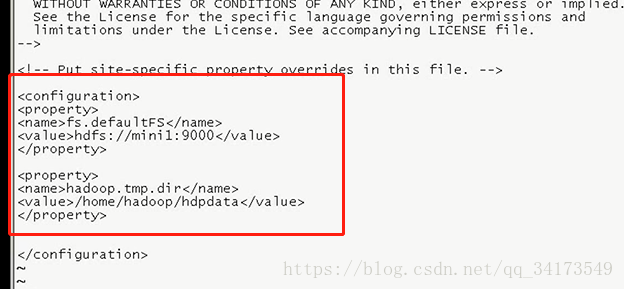
 默认3
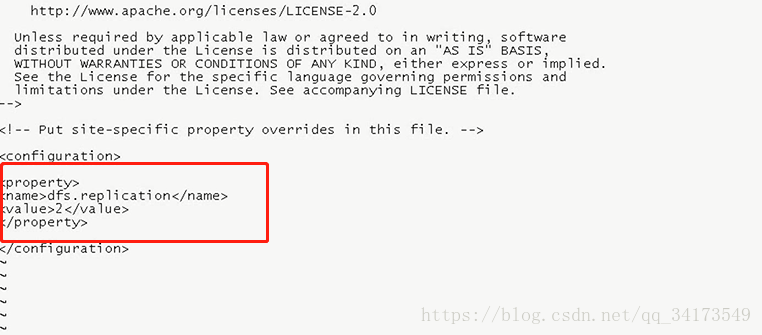
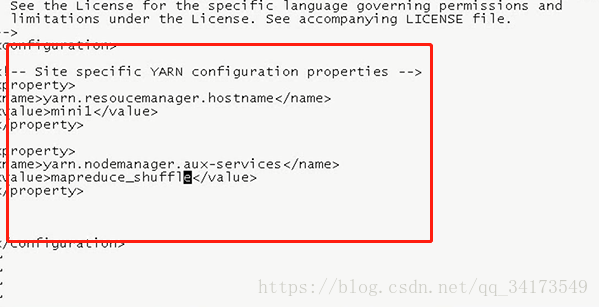
默认3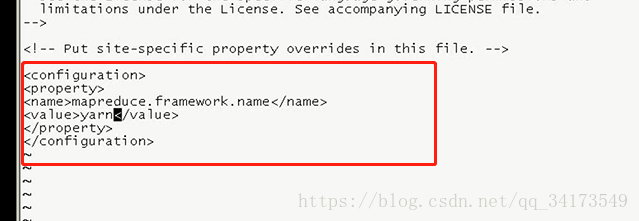



容器开启数据服务之旅系列(二):Kubernetes如何助力Spark大数据分析
容器开启数据服务之旅系列(二):Kubernetes如何助力Spark大数据分析 (二):Kubernetes如何助力Spark大数据分析 概述 本文为大家介绍一种容器化的数据服务Spark + OSS on ACK,允许Spark分布式计算节点对阿里云OSS对象存储的直接访问。借助阿里云Kubernetes容器服务与阿里云OSS存储资源的深度整合,允许Spark分布式内存计算,机器学习集群对云上的大数据直接进行分析和保存结果。 先决条件 你已经通过阿里云容器服务创建了一个Kubernetes集群,详细步骤参见创建Kubernetes集群 从容器服务控制台创建一个Spark OSS实例 使用三次点击来创建一个1 master + 3 worker 的Spark OSS的实例 1 登录 https://cs.console.aliyun.com/2