1. 问题描述
我们需要将不同服务器(如Web Server)上的log4j日志传输到同一台ELK服务器,介于公司服务器资源紧张(^_^)
2. 我们需要用到filebeat
什么是filebeat?
filebeat被用来ship events,即把一台服务器上的文件日志通过socket的方式,传输到远程的ELK。
可以传输到logstash,也可以直接传输到elasticsearch。
3. 我们这里讲解如何传输到远程的logstash,然后再由elasticsearch讲数据传输到kibana展示
3-1) 首先你要在你的本地测试机器上安装filebeat
以下是下载路径:
https://www.elastic.co/downloads/beats/filebeat
3-2) 其次你应该配置你的filebeat.xml
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /Users/KG/Documents/logs/t-server/*.log
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["xx.xx.xx.xx:5000"]
3-3) 启动filebeat
需要先给配置文件加权限
chown root filebeat.yml
然后启动
sudo ./filebeat -e -c filebeat.yml &
3-4) 配置远程的logstash并启动
log4j_filebeat.conf
input{
beats {
port => 5000
}
}
output{
stdout{ codec => rubydebug }
elasticsearch {
hosts => "localhost:9200"
index => "t-server-%{+YYYY.MM.dd}"
document_type => "log4j_type"
user => your-username
password => your-password
}
}
启动:
./bin/logstash -f config/log4j_fliebeat.conf &
3-5) Java客户端日志配置和程序
log4j.properties
### 设置###
log4j.rootLogger = debug,stdout,D
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=/Users/bee/Documents/elk/log4j/debug.log###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = /Users/KG/Documents/logs/t-server/app.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
Java API
package org.genesis.arena.elk;
import org.apache.log4j.Logger;
/**
* Created by KG on 17/3/27.
*/
public class ElkLog4jTest {
private static final Logger logger = Logger.getLogger(ElkLog4jTest.class);
public static void main(String[] args) throws Exception {
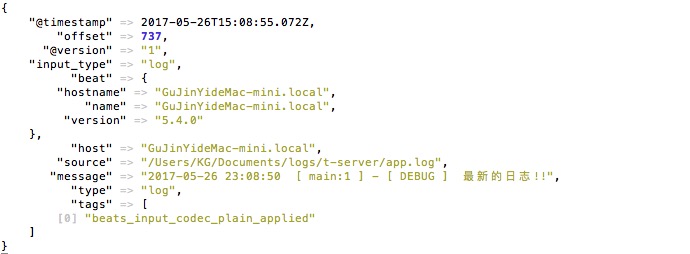
logger.debug("最新的日志!!");
}
}
在logstash看到结果如下:
![]()
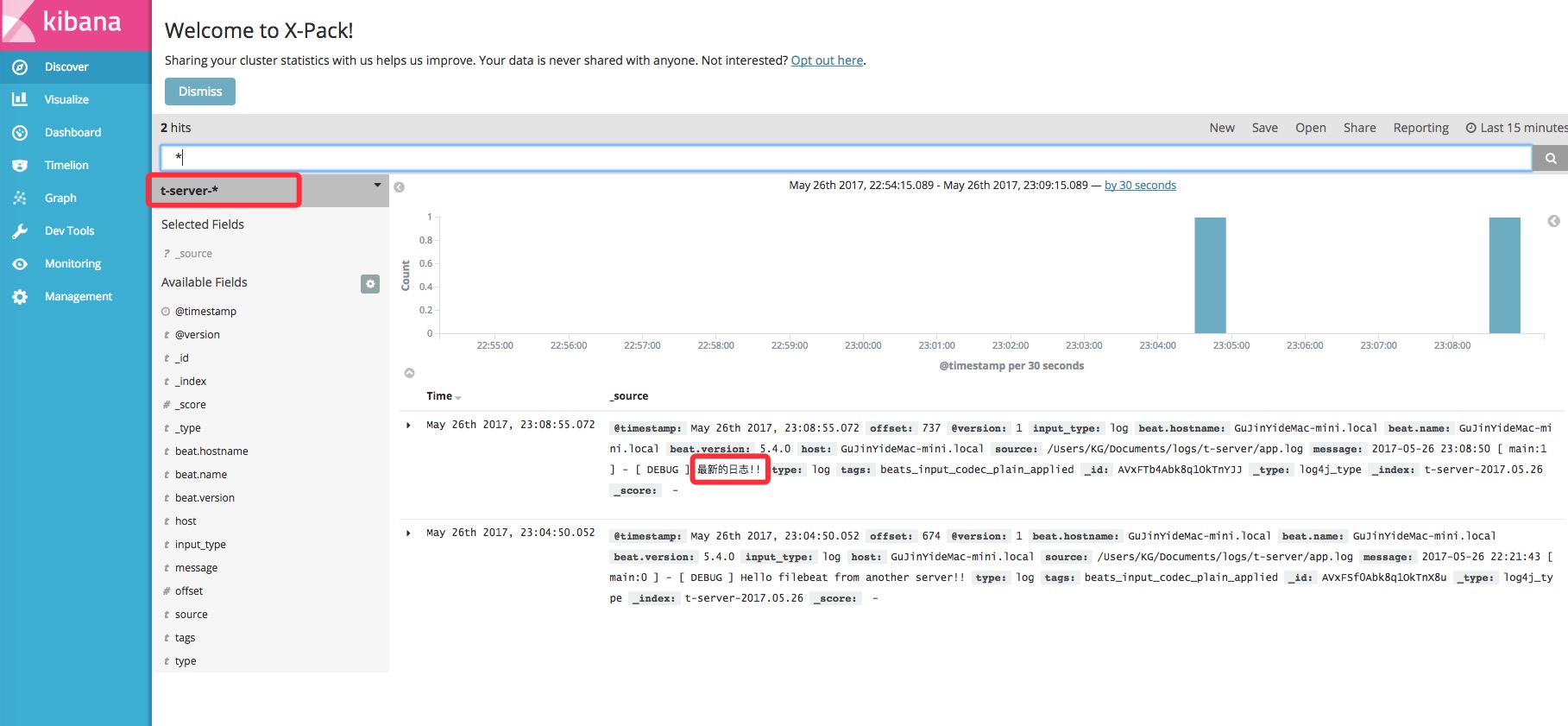
在kibana看到结果如下:
![]()
同理,我们使用另一个端口启动另外一个logstash后台进程
logstash配置文件如下:
log4j_fliebeat2.conf
input{
beats {
port => 5001
}
}
output{
stdout{ codec => rubydebug }
elasticsearch {
hosts => "localhost:9200"
index => "t-yxc-finance-%{+YYYY.MM.dd}"
document_type => "log4j_type"
user => your-username
password => your-password
}
}
启动:
./bin/logstash -f config/log4j_fliebeat2.conf &
filebeat.yml
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /Users/KG/Documents/logs/t-yxc-finance/*.log
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["xx.xx.xx.xx:5001"]
客户端配置文件和代码:
### 设置###
log4j.rootLogger = debug,stdout,D
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=/Users/bee/Documents/elk/log4j/debug.log###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = /Users/KG/Documents/logs/t-yxc-finance/app.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
package org.genesis.arena.elk;
import org.apache.log4j.Logger;
/**
* Created by KG on 17/3/27.
*/
public class ElkLog4jTest {
private static final Logger logger = Logger.getLogger(ElkLog4jTest.class);
public static void main(String[] args) throws Exception {
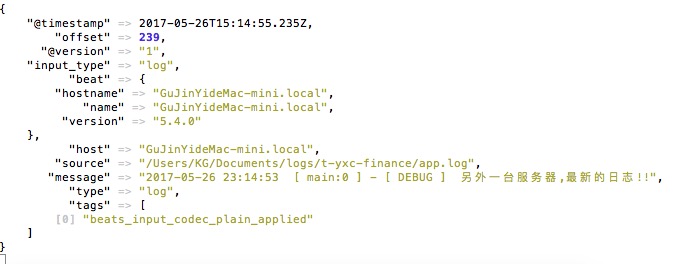
logger.debug("另外一台服务器,最新的日志!!");
}
}
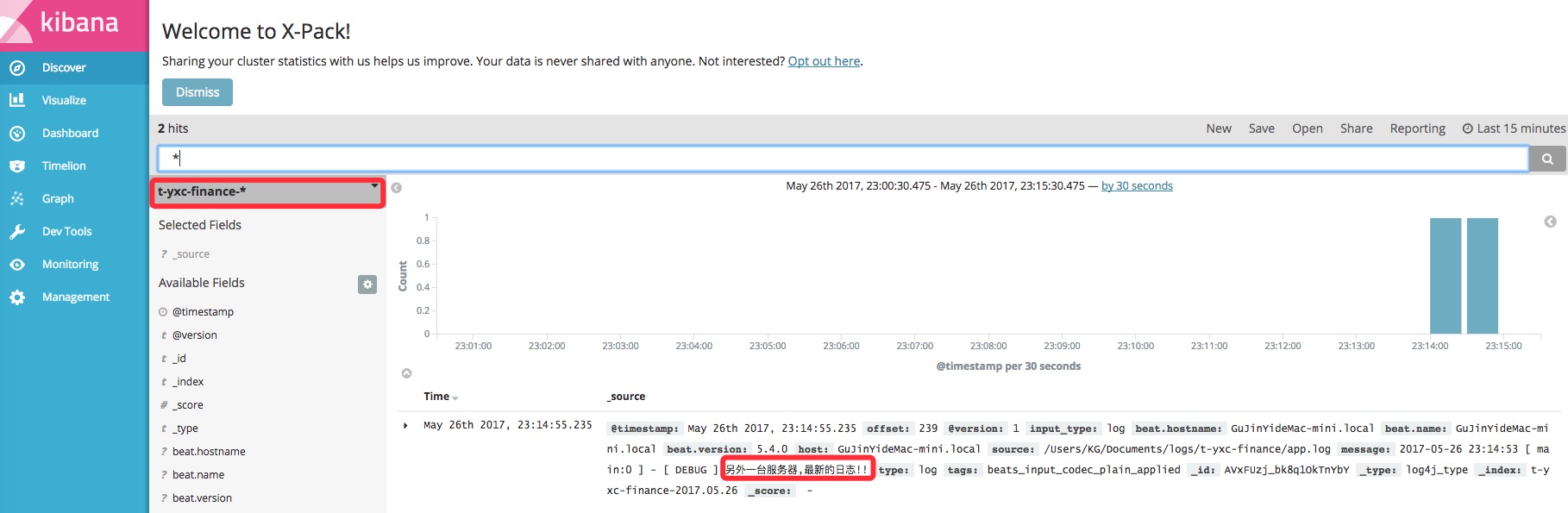
运行结果如下:
![]()
![]()