
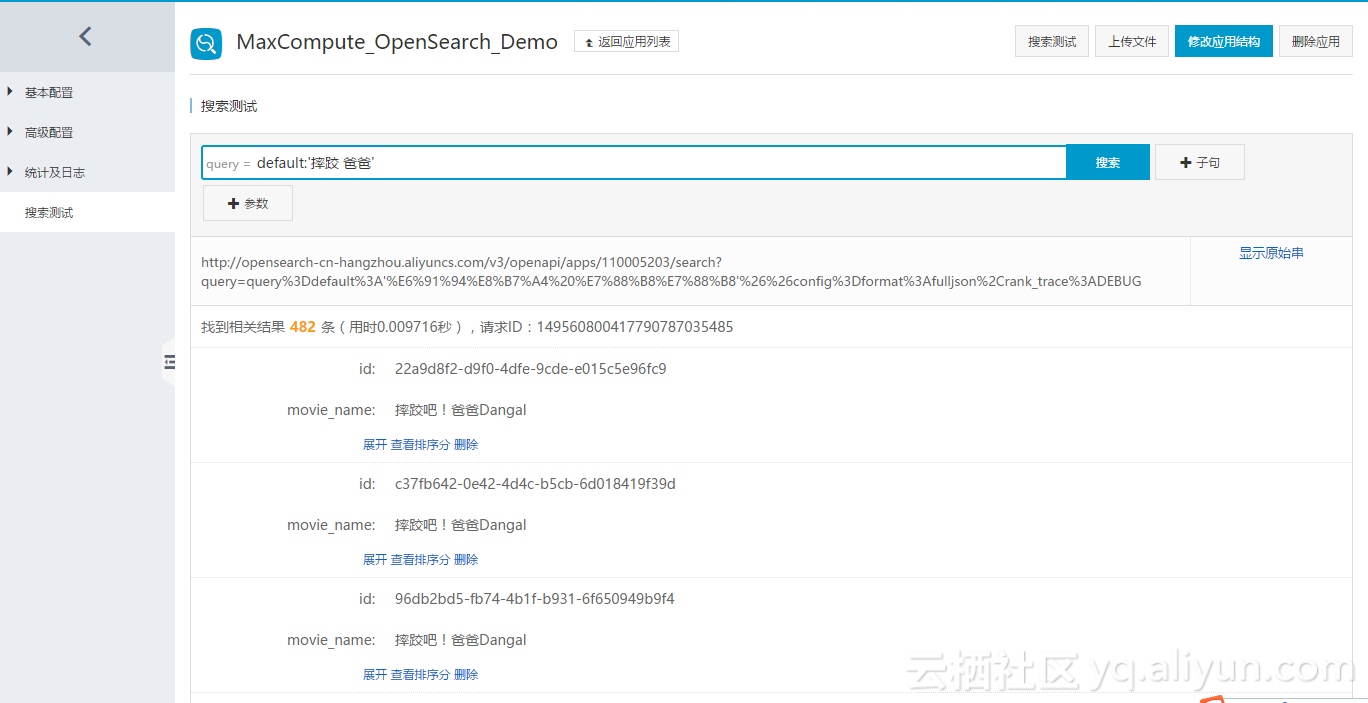
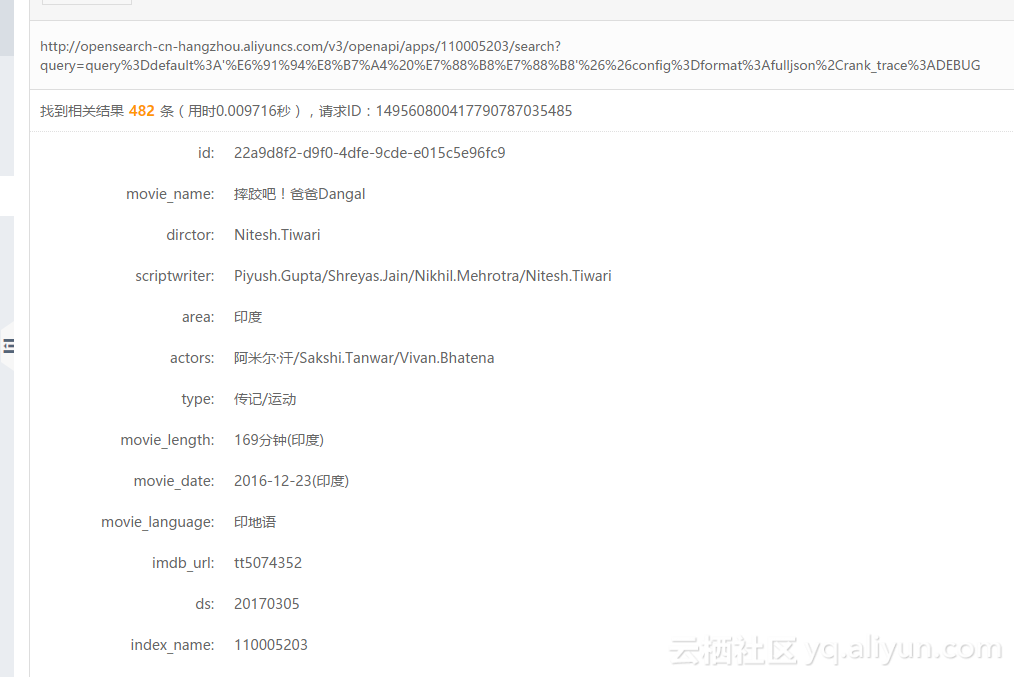
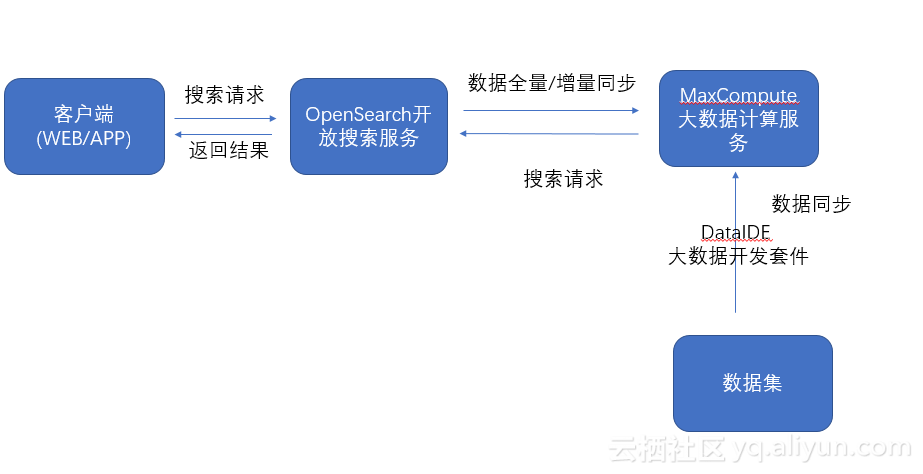

利用TFRecord和HDFS准备TensorFlow训练数据
本系列将利用阿里云容器服务的机器学习解决方案,帮助您了解和掌握TensorFlow,MXNet等深度学习库,开启您的深度学习之旅。 第一篇: 打造深度学习的云端实验室 第二篇: GPU资源的监控和报警,支撑高效深度学习的利器 第三篇: 利用TFRecord和HDFS准备TensorFlow训练数据 数据准备和预处理是一个深度学习训练过程中扮演着非常重要的角色,它影响着模型训练的速度和质量。 而TensorFlow对于HDFS的支持,将大数据与深度学习相集成,完善了从数据准备到模型训练的完整链条。在阿里云容器服务深度学习解决方案中, 为TensoFlow提供了OSS,NAS和HDFS三种分布式存储后端的支持。 本文将介绍如何将数据转化为TFRecord格式,并且将生成TFRecord文件保存到HDFS中, 这里我们直接使用的是阿里云EMR(E-