本文主要分析 SpringBoot 的启动过程。
SpringBoot的版本为:2.1.0 release,最新版本。
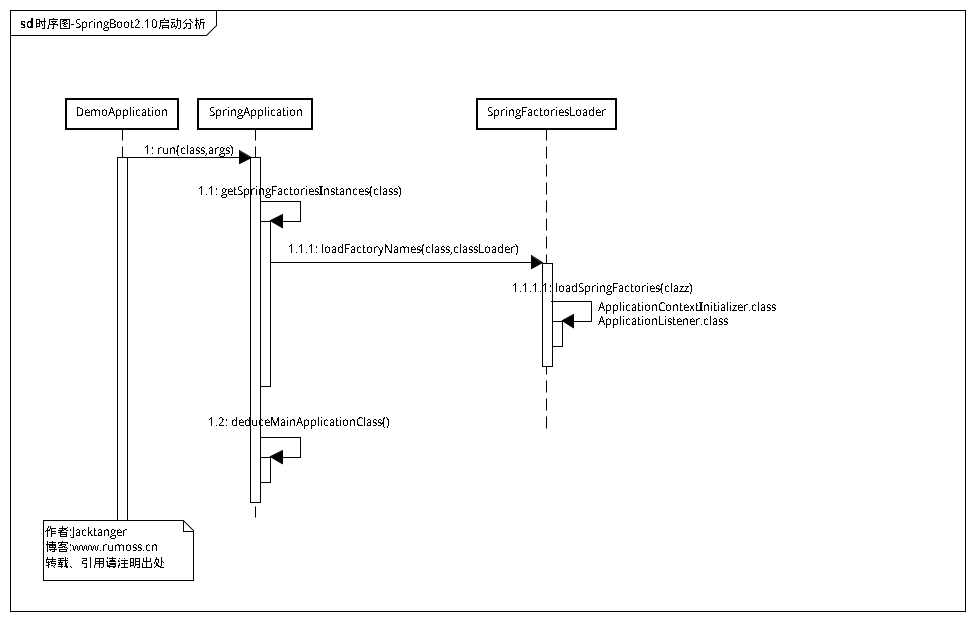
一.时序图
还是老套路,先把分析过程的时序图摆出来:时序图-SpringBoot2.10启动分析
![]()
二.源码分析
首先从我们的一个SpringBoot Demo开始,这里使用 SPRING INITIALIZR 网站生成的starter开始的:
@SpringBootApplication
public class SpringBootDemoApplication {
public static void main(String[] args) {
// 分析的入口,从 run 方法开始
SpringApplication.run(SpringBootDemoApplication.class, args);
}
}
经过SpringApplication多个重载的构造方法,最后到达:
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
// 从 run() 传入的 resourceLoader 此处为 null
this.resourceLoader = resourceLoader;
// 使用断言判断 resourceLoader 不为空
Assert.notNull(primarySources, "PrimarySources must not be null");
// 把 primarySources 数组转为List,最后放入 primarySources 的一个LinkedHashSet中
this.primarySources = new LinkedHashSet<>(Arrays.asList(primarySources));
// 判断应用的类型:REACTIVE NONE SERVLET
this.webApplicationType = WebApplicationType.deduceFromClasspath();
// 实现 SpringBoot 自动装配的基础,此处Spring自己实现的SPI(从META-INF/spring.factories加载class)
// 加载并实例化以 ApplicationContextInitializer 为key的类
setInitializers((Collection) getSpringFactoriesInstances(
ApplicationContextInitializer.class));
// 加载并实例化以 ApplicationListener 为key的类
setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));
// 获取程序当前运行堆栈,看是运行的是哪个类的 main 方法,保存到上下文中
this.mainApplicationClass = deduceMainApplicationClass();
}
看一眼,WebApplicationType#deduceFromClasspath ,deduce意为推断,即根据classpath下的内容推断出应用的类型。实现是通过ClassUtils#isPresent来尝试加载代表不同应用类型特征的Class文件:
static WebApplicationType deduceFromClasspath() {// 判断应用的类型
if (ClassUtils.isPresent(WEBFLUX_INDICATOR_CLASS, null)// 加载到DispatcherHandler
&& !ClassUtils.isPresent(WEBMVC_INDICATOR_CLASS, null)// mvc的DispatcherServlet
&& !ClassUtils.isPresent(JERSEY_INDICATOR_CLASS, null)) {// jersey的ServletContainer
return WebApplicationType.REACTIVE;
}
for (String className : SERVLET_INDICATOR_CLASSES) {// 遍历数组:Servlet和ConfigurableWebApplicationContext
if (!ClassUtils.isPresent(className, null)) {// 没有加载到Servlet相关的class
return WebApplicationType.NONE;
}
}
return WebApplicationType.SERVLET;
}
SpringApplication#getSpringFactoriesInstances,从类路径下 META-INF/spring.factories 下加载 SpringFactory 实例,类似的操作在 Dubbo SPI中也有:
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type,
Class<?>[] parameterTypes, Object... args) {
// 获取类加载器
ClassLoader classLoader = getClassLoader();
// 此处调用了SpringFactoriesLoader的loadFactoryNames()
Set<String> names = new LinkedHashSet<>(
SpringFactoriesLoader.loadFactoryNames(type, classLoader));
// Use names and ensure unique to protect against duplicates
// 实例化获取到的类
List<T> instances = createSpringFactoriesInstances(type, parameterTypes,
classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);// 排序
return instances;// 返回实例化好的对象
}
SpringFactoriesLoader#loadFactoryNames,加载工厂名字:
public static List<String> loadFactoryNames(Class<?> factoryClass, @Nullable ClassLoader classLoader) {
String factoryClassName = factoryClass.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryClassName, Collections.emptyList());
}
继续捉迷藏,到了 SpringFactoriesLoader#loadSpringFactories:下面的内容就是找到所有classpath下的 spring.factories 文件,读取里面的内容,放到缓存中,此处和Dubbo SPI中ExtensionLoader#loadDirectory几乎是一模一样,可以参考我写过的 Dubbo源码 里面的注释。
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
// 从缓存中获取Map,key为classLoader
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
// 加载资源的urls,被加载的资源为 "META-INF/spring.factories"
//先从Resources中加载,没有加载到再从SystemResources中加载
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {// 遍历加载到的 spring.factories 文件
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
// 读取文件到内存为Properties对象
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
// Entry的key作为工程Class的名字
String factoryClassName = ((String) entry.getKey()).trim();
for (String factoryName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
// 如果有多个value,都放在Map中,注意此处为 MultiValueMap ,不是普通的Map,其实现内容的value对应一个LinkedList
result.add(factoryClassName, factoryName.trim());
}
}
}
// 最后把读取配置的结果都放入缓存中,cache对象为一个ConcurrentReferenceHashMap
cache.put(classLoader, result);
return result;
}
catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}
我们也来看一下上面读取的文件 spring.factories 的内容,大概长这个样子:
# Initializers
org.springframework.context.ApplicationContextInitializer=\
org.springframework.boot.autoconfigure.SharedMetadataReaderFactoryContextInitializer,\
org.springframework.boot.autoconfigure.logging.ConditionEvaluationReportLoggingListener
# Application Listeners
org.springframework.context.ApplicationListener=\
org.springframework.boot.autoconfigure.BackgroundPreinitializer
# Auto Configuration Import Listeners
org.springframework.boot.autoconfigure.AutoConfigurationImportListener=\
org.springframework.boot.autoconfigure.condition.ConditionEvaluationReportAutoConfigurationImportListener
......
是时候跳出来了,回到主线,返回实例化对象后,到了 SpringApplication#deduceMainApplicationClass,获取程序当前运行堆栈,看现在运行的是哪个类的 main 方法,然后保存到上下文:
private Class<?> deduceMainApplicationClass() {
try {
// 拿到运行时的堆栈信息
StackTraceElement[] stackTrace = new RuntimeException().getStackTrace();
for (StackTraceElement stackTraceElement : stackTrace) {
// 如果发现哪个堆栈元素里面有运行了main方法,则返回该类
if ("main".equals(stackTraceElement.getMethodName())) {
return Class.forName(stackTraceElement.getClassName());
}
}
}
catch (ClassNotFoundException ex) {
// Swallow and continue
}
return null;
}
至此,SpringApplication的构造函数的分析完成,后面我们继续分析SpringApplication的run()方法中做了哪些操作。