背景
公司落地容器化及Kubernetes,既有的监控部署在虚拟机上,需要迁移到K8S集群中来缩减虚拟机的开销,我们基于Prometheus的监控系统搭建近一年,保存数据周期为180填,目前的数据量在800GB左右,下面讲述的是我们的迁移方案及迁移过程。
方案
1. Kubernetes集群内
- 创建好存储,PV,PVC
- 创建好StatefulSet,Service等
- 在K8S内拉起Prometheus+Grafana
- 测试验证,验证通过后kubectl delete删除相关的实例,保留好yaml
2. 旧Prometheus及Grafana实例上
- 将K8S集群内刚刚验证好的那块盘挂载到待迁移数据机器实例上
- 迁移数据
- 修改数据所属组及权限
- 卸载新盘
3. Kubernetes集群内
- 再次部署预定义好并经过测试的yaml
- 观察,测试
- 切换Grafana数据源,指向K8S中的Prometheus
实施过程
K8S集群内拉起新Prometheus
kubectl logs prometheus-ecs-0 -n monitoring
...
level=info ts=2019-07-08T04:14:50.715Z caller=main.go:714 msg="Notifier manager stopped"
level=info ts=2019-07-08T04:14:50.715Z caller=main.go:544 msg="Scrape manager stopped"
level=error ts=2019-07-08T04:14:50.715Z caller=main.go:723 err="opening storage failed: mkdir data/: permission denied"
权限问题报错了,增加securityContext相关描述,再试,此处参考Google-Groups或者Github Issue
kind: StatefulSet
metadata:
name: prometheus-ecs
namespace: monitoring
spec:
serviceName: "prometheus-ecs"
selector:
matchLabels:
app: prometheus-ecs
template:
metadata:
labels:
app: prometheus-ecs
spec:
...
securityContext:
runAsUser: 1000
fsGroup: 2000
runAsNonRoot: true
...
增加描述后重新拉起POD,数据能够正常生成了,看下面的data文件夹
/prometheus $ ls -l
total 5242908
drwxr-sr-x 3 1000 2000 4096 Jul 8 04:26 data
drwxrwsr-x 4 root 2000 4096 Jul 8 04:09 k8s-resource-monitoring
drwxrwS--- 2 root 2000 16384 Jul 8 02:37 lost+found
接下来我们kubectl delete删除刚刚创建的所有对象,把yaml准备好,然后把磁盘挂载到计划迁移的机器上,同步数据。
将磁盘挂载到旧Prometheus机器上
挂载创建的目标磁盘到旧Prometheus的虚拟机上,然后用rsync将数据追平,注意用--bwlimit控制速度,不然可能会导致磁盘打满影响线上性能,我们是SSD盘所以指定200M依然剩余100M的速度空间保证线上使用。
rsync -av --bwlimit=200M --delete --progress --log-file=/tmp/rsync.log /data/coohua/prometheus/data /data1/data
确认迁移过程中系统稳定,各项参数正常
# dstat -a
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
28 0 72 0 0 0| 652k 666k| 0 0 | 0 0 |1953 1401
37 4 54 5 0 0| 141M 237M| 344k 5408B| 0 0 |6918 5466
39 6 47 9 0 0| 205M 293M| 17k 3006B| 0 0 |7477 5874
48 6 38 8 0 0| 201M 306M| 959k 10k| 0 0 |8001 5705
50 5 45 0 0 0| 187M 12M| 83k 3531B| 0 0 |7589 5135
41 6 50 3 0 0| 204M 113M| 360k 11k| 0 0 |9505 8630
38 5 47 9 0 1| 177M 204M| 84k 1468B| 0 0 |8268 7147
71 5 20 4 0 0| 147M 308M| 131k 4766B| 0 0 |8334 5281
94 4 2 0 0 0| 132M 301M| 180k 4392B| 0 0 |9274 5789
46 5 48 0 0 0| 210M 42M| 393k 5334B| 0 0 |7928 6030
40 5 55 0 0 0| 190M 0 | 361k 16k| 0 0 |6994 5119
28 5 58 9 0 0| 156M 228M| 80k 3554B| 0 0 |5414 4121
# top
top - 14:21:03 up 186 days, 23:07, 2 users, load average: 6.36, 5.54, 5.07
Tasks: 144 total, 4 running, 140 sleeping, 0 stopped, 0 zombie
%Cpu0 : 85.0 us, 0.0 sy, 0.0 ni, 15.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 29.1 us, 1.0 sy, 0.0 ni, 61.6 id, 7.9 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu2 : 27.1 us, 3.3 sy, 0.0 ni, 69.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 66.3 us, 1.7 sy, 0.0 ni, 29.0 id, 3.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 37.3 us, 11.0 sy, 0.0 ni, 51.0 id, 0.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 31.8 us, 8.4 sy, 0.0 ni, 54.2 id, 5.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 61.8 us, 3.0 sy, 0.0 ni, 34.6 id, 0.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 31.5 us, 12.2 sy, 0.0 ni, 46.1 id, 10.2 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16267428 total, 160392 free, 7907888 used, 8199148 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7989000 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4903 coohua 20 0 0.682t 7.784g 817072 S 279.7 50.2 62469:47 prometheus
20712 root 20 0 129656 1180 332 R 62.1 0.0 2:10.42 rsync
20710 root 20 0 129696 2348 1232 R 56.1 0.0 1:53.88 rsync
61 root 20 0 0 0 0 S 6.6 0.0 110:21.78 kswapd0
# iostat -xdm 1
Linux 3.10.0-514.26.2.el7.x86_64 (monitor-storage001) 2019年07月08日 _x86_64_ (8 CPU)
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.64 0.06 1.33 0.00 0.01 17.52 0.01 7.71 23.99 6.95 0.86 0.12
vdb 0.01 0.36 4.11 1.88 0.67 0.64 446.97 0.04 7.46 10.11 1.67 1.35 0.81
vdc 0.00 0.00 0.00 0.08 0.00 0.04 959.25 0.01 179.72 32.19 179.79 1.54 0.01
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 2.00 359.00 2.00 160.00 0.02 907.79 3.16 8.33 8.37 1.00 1.34 48.50
vdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 1.00 0.00 470.00 8.00 208.55 3.44 908.30 4.50 9.82 9.48 30.00 1.31 62.40
vdc 0.00 8.00 0.00 409.00 0.00 190.92 955.99 68.50 154.77 0.00 154.77 1.47 60.30
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 4.00 0.00 2.00 0.00 0.02 24.00 0.00 0.50 0.00 0.50 0.50 0.10
vdb 0.00 0.00 457.00 0.00 202.09 0.00 905.65 4.32 9.48 9.48 0.00 1.33 61.00
vdc 0.00 0.00 0.00 640.00 0.00 300.49 961.58 127.32 194.03 0.00 194.03 1.56 100.10
坐等数据同步完毕
磁盘再次挂载到POD中使用迁移过来的数据
数据迁移完成了,查看迁移过程中磁盘的读写情况,由于我们限速为200MiB,所以情况如预期
![]()
注意修改数据权限,要不然到时候POD又起不来
# umount -l /data1
# chown -R 1000:2000 /data1/data
PV/PVC没删干净会出现下面的问题,PV处于Released状态不能再次使用
kubectl get pvc -n monitoring pv-metrics-ecs-promethues
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pv-metrics-ecs-promethues Pending
kubectl get pv -n monitoring pv-metrics-ecs-promethues
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-metrics-ecs-promethues 1Ti RWX Retain Released monitoring/pv-metrics-ecs-promethues disk 3h32m
简单粗暴的删除PV/PVC重建即可
然后在Kubernetes内启动原来准备好的StatefulSet即可,就会直接用迁移后的数据了,然后创建NodePort类型的Service,用来让还没迁移进K8S的Grafana连接
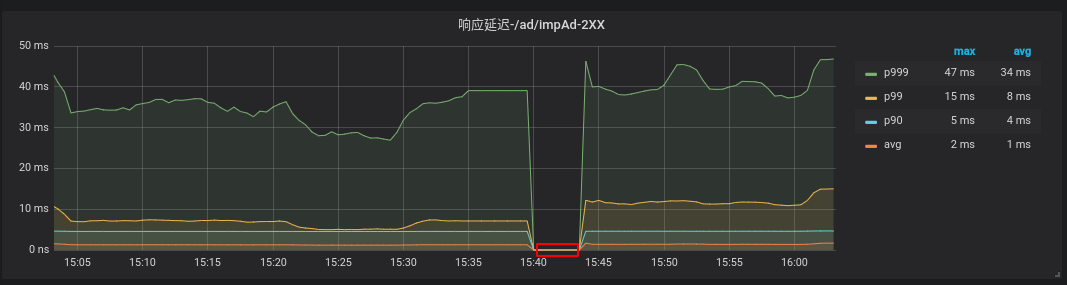
接下来修改Grafana的数据源,指向迁移后的Prometheus,大功告成,迁移过程中断服务丢失的数据<10分钟
![]()
总结 & 思考
不完美的方案,但是简单可行
数据同步完成后然后在K8S中拉起POD,POD初始化后Prometheus需要处理数据,然后开始拉新数据,这个过程中中断的时间可能要10至15分钟,也就是说最少要丢失10至15分钟的监控数据,这个我们从业务上衡量是可以接受的,找一个合适的时间操作即可。
有完美的方案吗?
官方社区Prometheus的Developer提到的方案是,起一个新的实例跑同样的配置,等到足够长的时间,旧的自然就退休了,这个可能是最完美的方案,但是在我们的场景,我们数据保存180天将近1T的数据,而且使用SSD作为存储,这个退休的时间内我们的硬件成本是双倍的,从经济上考虑,我们还是否定了这个方案。
慎用NFS为存储的PV
第一次尝试迁移使用了NFS,因为云提供商的特性,NFS较为经济,而且可以多处挂载,数据的管理也是十分的便利,但是迁移过来后测试发现,一个大的查询就差点把网卡跑满,load瞬间爆炸,赶紧下线。所以在重IO的场景,真的慎重考虑NFS,一定要做好性能评估。