HDFS存储系统
一、基本概念
1、NameNode
HDFS采用Master/Slave架构。namenode就是HDFS的Master架构。主要负责HDFS文件系统的管理工作,具体包括:名称空间(namespace)管理(如打开、关闭、重命名文件和目录、映射关系)、文件block管理。NameNode提供的是始终被动接收服务的server。一个文件被分成一个或多个Bolck,这些Block存储在DataNode集合里,NameNode就负责管理文件Block的所有元数据信息。
Secondary NameNode主要是定时对NameNode的数据snapshots进行备份,这样可尽量降低NameNode崩溃之后导致数据丢失的风险。具体就是从namenode中获得fsimage和edits后把两者重新合并发给NameNode,这样,既能减轻NameNode的负担又能安全得备份,一旦HDFS的Master架构失效,就可以借助Secondary NameNode进行数据恢复。
namenode管理着所有所有文件系统的元数据。这些元数据包括名称空间、访问控制信息、文件和Block的映射信息,以及当前Block的位置信息。还管理着系统范围内的活动。
2、DataNode
用于存储并管理元数据。DataNode上存储了数据块ID和数据块内容,以及他们的映射关系。
3、客户端
访问HDFS的程序或HDFS shell命令都可以称为HDFS的客户端,在HDFS的客户端中至少需要指定HDFS集群配置中的NameNode地址以及端口号信息,或者通过配置HDFS的core-site.xml配置文件来指定。
二、HDFS的组成和架构
2.1 hdfs架构设计
HDFS最重要的两个组件为:作为Master的NameNode和作为Slave的DataNode。NameNode负责管理文件系统的命名空间和客户端对文件的访问;DataNode是数据存储节点,所有的这些机器通常都是普通的运行linux的机器,运行着用户级别的服务进程。
![]()
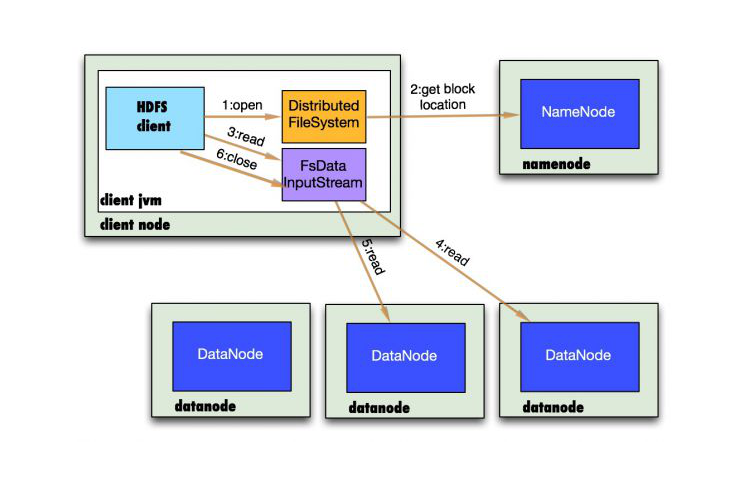
图展示了HDFS的NameNode、DataNode以及客户端的存取访问关系。NameNode负责保存和管理所有的HDFS元数据,因而用户数据不需要通过namenode,也就是说文件数据的读写是直接在datanode上进行的。HDFS存储的文件被分割成固定大小的Block,在创建Block的时候,namenode服务器会给每个block分配一个唯一不变的block标识。datanode服务器把block以linux文件的形成保存在本地磁盘上,并且根据指定的block标识和字节范围来读写块数据。处于可靠性的考虑,每个块都会复制到多个datanode上。默认使用三个冗余备份。
HDFS客户端代码以库的形式被链接到客户程序中。客户端和namenode交互只获取元数据,所有的数据操作都是由客户端直接和datanode进行交互。
2.2 HDFS读文件数据流
![]()
图为HDFS读文件数据流的过程,具体的执行过程为:
1、调用FileSystem的open()打开文件,见序号1:open
2、DistributedFileSystem使用RPC调用NameNode,得到文件的数据块元数据信息,并返回FSDataInputStream给客户端,见序号2:get block locations
3、HDFS客户端调用stream的read()函数开始读取数据,见序号3:read
4、调用FSDATAInputStream直接从DataNode获取文件数据块,见序号4、5:read
5、读完文件时,调用FSDATAInputStream的close函数,见序号6:close
2.3 HDFS写文件数据流
读文件时在多个数据块文件中选择一个就可以了,但是写数据文件时需要同时写道多个数据块文件中。
![]()
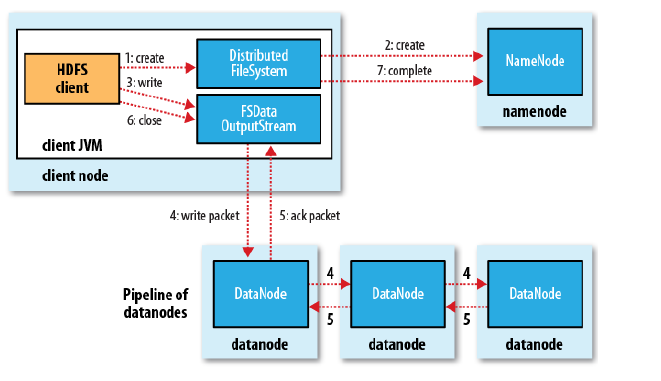
图为HDFS写文件数据流的过程,首先客户端调用create()来创建文件,然后DistributedFileSystem同样使用RPC调用namenode首先确定文件是否不存在,以及客户端有创建文件的权限,然后创建文件。DistributedFileSystem返回DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。data queue由data streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在pipeline里。data streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点,第二个数据节点将数据发送给第三个数据节点。DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
三、HDFS文件结构
1、namenode的存储目录中包含三个文件:
edits、fsimage、fstime。都是二进制文件,可以通过Hadoop Writable对象就行序列化。
2、编辑日志(edit log)和文件系统映像(filesystem image)
当客户端执行写操作时,首先namenode会在编辑日志中写下记录,并在内存中保存一个文件系统元数据,并且不断更新。
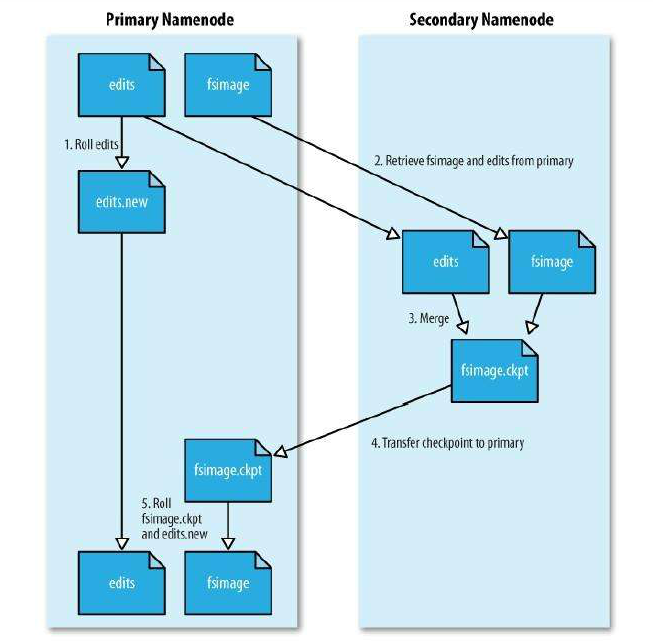
fsimage文件是文件系统元数据的持久性检查点,和编辑日志不同,它不会再每个文件系统的写操作后进行更新。但是文件系统会出现编辑日志的不断增长情况。为了解决这个问题,引入了secondary namenode。它的任务就是为原namenode内存中的文件系统元数据产生检查点,是一个辅助namenode处理fsimage和编辑日志的节点,它从namenode中拷贝fsimage和编辑日志到临时目录并定期合并成一个新的fsimage,随后上传至namenode。具体的检查点的处理过程如下:
![]()
1、secondary namenode首先请求原namenode进行edits的滚动,这样新的编辑操作就能进入一个新的文件中。
2、secondary namenode通过http方式读取原namenode中的fsimage及edits。
3、secondary namenode读取fsimage到内存中,然后执行edits中的每个操作,并创建一个新的统一的fsimage文件。
4、secondary namenode将新的fsimage发送到原namenode。
5、原namenode用新的fsimage替换旧的,旧的edits文件用步骤1中的edits进行替换,同时系统会更新fsimage文件到文件的记录检查点时间。
四、HDFS核心设计
1、block的大小
block的大小是HDFS关键的设计参数之一,默认大小为64MB,选择较大的Block的优点:
1、减少了客户端和NameNode通信的需求。
2、客户端能够对一个块进行多次操作,这样就可以通过block服务器较长时间的TCP连接来减少网络负载。
3、减少namenode节点需要保存的元数据的数量,从而很容易把所有元数据放在内存中。
当然选择较大的block也有一定的缺点,当文件过小时,数百个客户端并发请求访问会导致系统局部过载,解决这个问题可以通过自定义更大的HDFS的复制因子来解决。
2、数据复制
HDFS中,每个文件存储成block序列,除了最后一个block,所有的block都是同样大小,文件的所有block为了容错都会被冗余复制存储。HDFS中的文件是writer-one,严格要求任何时候只能是一个writer。文件的复制会全权交给namenode进行管理,namenode周期性的从集群中的每个datanode接收心跳包和一个blockreport。心跳包表示该datanode节点正常工作,而blockreport包括了该datanode上所有的block组成的列表。
3、数据副本存放策略
副本的存放是HDFS可靠性和高性能的关键。HDFS采用一种机架感知的策略来改进数据的可靠性、可用性和网络带宽的利用率。一个简单的没有优化的策略就是将副本存放在不同的机架上。这样可以有效防止当整个机架失效时数据的丢失,并且允许读取数据的时候充分利用多个机架的带宽。
HDFS的默认副本系数为3,副本存放策略是将第一个副本存放在本地机架的节点上,将第二个副本放在同一个机架的另一个节点上,将第三个副本放在不同的机架的节点上。因为是放在两个机架上,所以减少了读取数据时需要的网络传输总带宽。这样的策略减少了机架之间的数据传输,提高了写操作的效率,机架的错误远比节点的错误要少的多,所以不会影响数据的可靠性和可用性。
4、安全模式
当系统处于安全模式时,不会接受任何对名称空间的修改,同时也不会对数据块进行复制或删除。namenode启动之后,自动进入安全模式,namenode从所有的datanode接收心跳信号和块状态报告。块状态报告包括了某个datanode所有的数据块列表,每个数据块都有一个指定的最小副本数。当namenode检测确认某个数据块的副本数目达到这个最小值,该数据块就认为是副本安全的。在一定百分比的数据块被namenode检测确认是安全的之后(加上30s等待时间),namenode将退出安全模式。
1 bin/hadoop dfsadmin -safemode enter //进入安全模式
2 bin/hadoop dfsadmin -safemode leave //退出安全模式
3 bin/hadoop dfsadmin -safemode get //返回安全模式是否开启的信息
4 bin/hadoop dfsadmin -safemode wait //等待一直等到安全模式结束
5、负载均衡
HDFS很容易出现不平衡状况的问题,同时也会引发其他问题,比如说MapReduce程序无法很好的利用本地计算机的优势,机器之间无法到达更好的网络带宽使用率、机器磁盘无法利用等。HDFS提供了一个工具,用于分析数据块分布和重新均衡DataNode上的数据分布。
$HADOOP_HOME/bin/start-balancer.sh -t 10%
这个命令,-t参数后面的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间的使用率偏差小于10%,那么我们认为HDFS集群就达到了平衡状态。
![]()
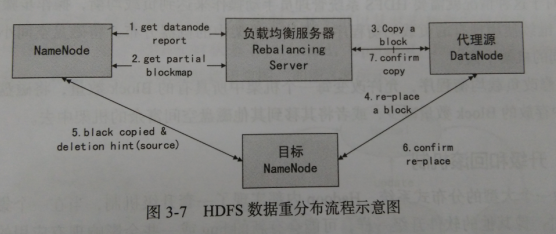
负载均衡程序作为一个独立的进程与namenode进行分开执行,HDFS均衡负载处理工程如下:
1、负载均衡服务Rebalancing Server从namenode中获取datanode的情况,具体包括每一个datanode磁盘使用情况,见序号1:get datanode report
2、Rebalancing Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据,以及从datanode中获取需要移动数据的分布情况,见序号2:get partial blockmap
3、Rebalancing Server计算出来哪一台机器的block移动到另一台机器中去,见序号3:copy a block
4、需要移动block的机器将数据移动到目标机器上,同时删除自己机器上的block数据,见序号4、5、6
5、Rebalancing Server获取本次数据移动的执行结果,并继续执行这个过程,一直到没有数据可以移动或HDFS集群已经达到平衡的标准为止,见序号7
6、升级和回滚机制
和升级软件一样,可以再集群上升级hadoop,可能升级成功,也可能失败,如果失败了,就用rollback进行回滚;如果过了一段时间,系统运行正常,就可以finalize正式提交这次升级。相关升级和回滚命令如下:
1 bin/hadoop namenode -update //升级
2 bin/hadoop namenode -rollback //回滚
3 bin/hadoop namenode -finalize //提交
4 bin/hadoop namenode -importCheckpoint //从Checkpoint恢复.用于namenode故障
升级过程:
1、通过dfsadmin -upgradeProgress status检查是否已经存在一个备份,如果存在,则删除。
2、停止集群并部署Hadoop的新版本
3、使用-upgrade选项运行新的版本(bin/start-dfs.sh -upgrade)
如果想退回老版本:
1、停止集群并部署hadoop的老版本。
2、用回滚选项启动集群,命令如下:bin/start-dfs.sh -rollback
7、HDFS的缺点
1、访问时延:HDFS的设计主要是用于大吞吐量的数据,是以一定的时延为代价的。
2、对大量小文件的处理
大量小文件处理时难免产生大量线程时延。解决办法:利用SequenceFile、MapFile、Har等方式归档小文件。就是把小文件归档管理,HBase就是这种原理。横向扩展。多Master设计。
3、多用户写,任意文件修改
四、HDFS常用命令
1、archive
用于创建一个hadoop归档文件,hadoop archive是特殊的档案格式。一个hadoop archive对应一个文件系统目录。拓展名是.har。
1)创建一个archive:使用方法如下:
1 hadoop archive -archiveName NAME -p <parenet path> <src>* <dest>
2
3 archiveName:指定要创建的档案的名字
4 p:是否创建路径中的各级服目录
5 src:需要归档的源目录,可以含正则表达式
6 dest:保存档案文件的目标目录
例如:需要将目录/usr/work/dir1和/usr/work/dir2归档为work.har,并保存在目标目录/data/search下,命令如下:
bin/hadoop archive -archiveName work.har /usr/work/dir1 /usr/work/dir2 /data/search
2)查看archive文件
1 查看前面创建的archive的归档文件work.har,需要获得创建的archive中的文件列表,即
2 hadoop dfs -lsr har:///data/search/work.har
3 查看archive中的file1文件的命令如下:
4 hadoop dfs -cat har:///data/search/work.har/dir1/file1
2、distcp
用于hadoop集群之间复制数据。
1 例如:将集群NN1的数据目录/data/logs复制到NN2的/data/logs目录,假设端口均为9000,则在NN1上执行以下命令:(也可以将多个源目录复制到一个目录中)
2 hadoop distcp hdfs://NN1:9000/data/logs hdfs://NN2:9000/data/logs
3、fsck
fsck是HDFS文件系统的检查工具。当用户发现HDFS上的文件可能受损时,可以使用这个命令进行检查,方法如下:
1 hadoop fsck <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | locations | -racks]]]
2
3 <path>:检查的起始目录
4 -move:移动受损文件到/lost+found
5 -delete:删除受损文件
6 -openforwrite:打印出写打开的文件
7 -files:打印出整被检查的文件
8 -blocks:打印出快信息报告
9 -locations:打印出每个块的位置信息
五、HDFS Java API的使用方法
见hadoop-1.x运行实例
当神已无能为力,那便是魔渡众生