语音识别技术经过三十几年的发展,识别率的提升使语言识别技术越来越贴近我们的生活。各大公司都在语音识别的产品和技术上大有投入。语音输入法成为IOS,Andriod,YunOS手机输入法是必不可少的按钮,智能助手如Siri,Google Now,Cortana,YunOS语音助手都把speech和NLP结合在一起作为智能助手的形式提供给大家。家庭娱乐如xbox,apple tv, 天猫魔盒语音的输入让人机交互更容易。
和其他机器学习一样,语音识别是一个science和engineer美妙结合的任务。Science推动语音识别基本技术的升级,engineer扩充语音识别的场景和语言。本节主要讨论在机器学习的engineering方面我们做了什么。
从语音识别内部的技术角度,大家已经逐渐的建立了以下的一些共识:
1. 真实场景的数据是王道。机器学习需要教科书,真实数据是最好的教科书。
2. 统计模型是state-of-the-art。
3. 先HMM训练再DNN模型是标准模式。
所以语音识别最标准的玩法就是下面这个循环:
![e71b2f356c540201cb12ef64bc5e57feca889ffa]()
咱们先人工建立初始的数据库来build第一个模型。当然有市场的地方就有生意,所以有很多公司会卖自己录好的数据库,这样你就可以直接买现成的数据库。然后你训练好模型,测试发现没有问题,你就把你的模型上线做服务,然后你的用户用的时候就会有真实场景的录音,你选择需要的数据来标注,然后你就回到模型训练的过程。这个圈就转转转,然后在转的过程中你的识别率就提升了。
语音识别的当前技术对于不同的业务场景你需要业务场景匹配的数据你才能够拿到最好的识别。不同的语言我们需要建立不同的模型。所以你要是做M个业务的N个语言,然后每个场景里更新K遍模型,那么这个量就很大了。
我们建立pipeline的目的是为了强大的中后台来支持我们的业务需求,pipeline能够
- 分布式:处理大规模数据需要分布式来加速,多业务模型需要分布式需要来支持。
- 自动化: 提供数据处理,模型训练,测试等等的自动化。
- 沉淀技术:固化我们在流程和算法上的提升。
- 易扩展:易于扩展到新的业务和新的语音。
基于上面的图,pipeline需要支持下面的几种主要的功能:
- 模型训练(AM:GMM+DNN, LM)
- 模型测试
- 自动化上线流程
- 数据的筛选和处理
我们最终要达到的目标:用户给定配置文件说这是训练数据,这是我需要的模型的大小,这是我的测试集,我要用100台机器训练。然后pipeline就完成模型的训练和测试,然后发邮件告诉你模型好啦,识别率是多少,然后你点我要上线,然后模型就会在线上系统部署,然后线上测试自己完成,通过用户就有新模型用了。
这个最终的目的是庞大的,但是我们可以拆分成多个子步骤逐步完成。一套代码框架下写,然后就可以组合子步骤。在最终的任务完成之前,子步骤可以被单独调用。我们现在已经有不少子模块达到了自动化的程度,后面会继续完成其他子模块。
分布式的问题
语音识别的分布式是比较特殊的问题,所以这里单独讨论下。文本的分布式相对成熟,因为现在的很多分布式系统都是为文本处理而生的。但是语音是二进制文件,而且语音模型训练比较复杂,DNN模型需要GPU队列,DNN模型需要CPU队列,之间数据还要交换,如何把这些放到现有的分布式系统的框架里面是比较大的挑战。
我们在发展变化的过程中,经历几个阶段:
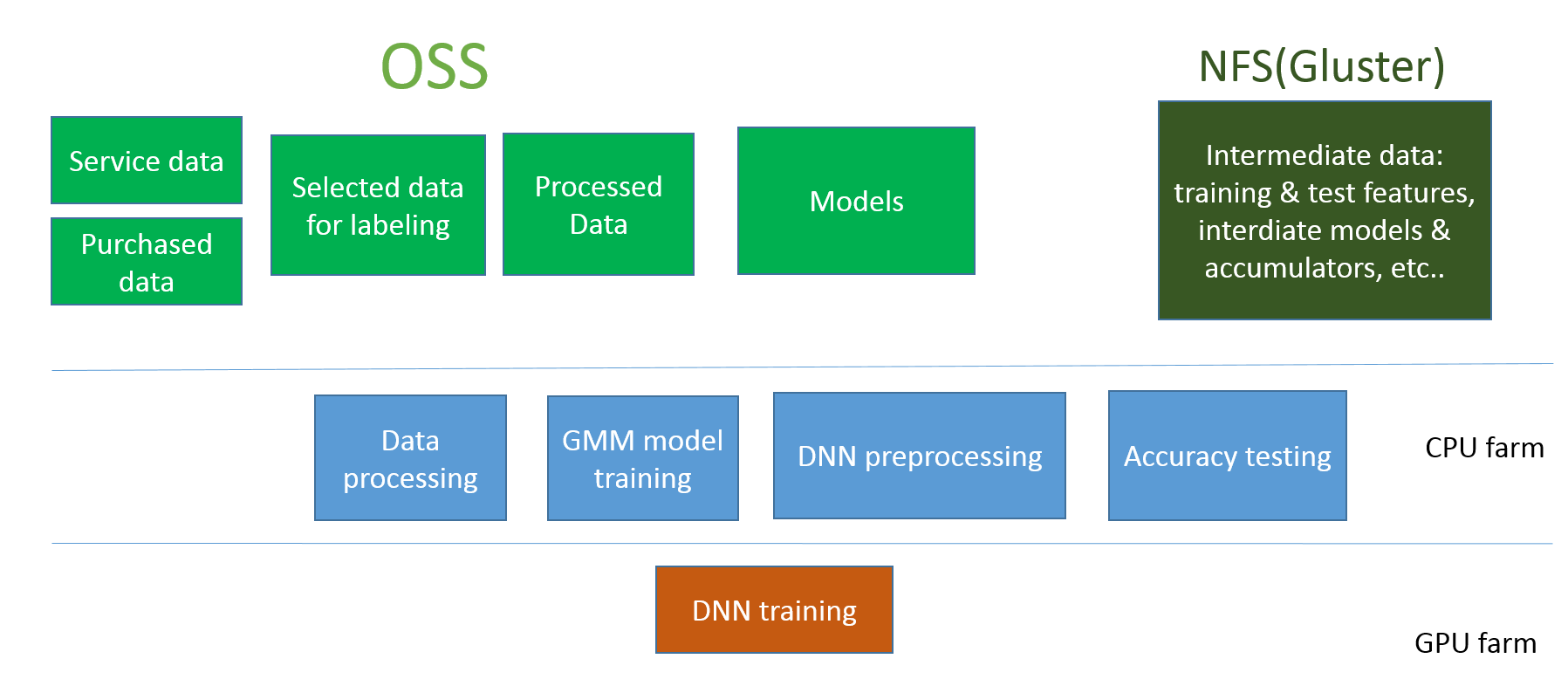
- 第一阶段:基于物理机+ Gluster+OSS+GPU的模式
- 第二阶段,基于MaxCompute集群+GPU集群的模式
- 第三阶段,GPU集群和MaxCompute集群的合并
第一阶段:基于物理机+ Gluster+OSS+GPU的模式
在这个模式下:
OSS用于存储数据和模型。
Gluster用于保存临时的计算数据,用于临时分布式计算交换使用。
CPU farm负责数据处理,GMM训练,DNN预处理,模型测试。
GPU farm用于DNN模型训练。
这个模式的好处是每块比较独立,开发成本小,在业务的早期可以满足我们的需要。但是问题是系统太杂,数据交换是问题,计算的可扩展性也是问题。
![1bb6848e02a1da1cc133c9b90854da2cfd5df831]()
第二阶段,基于MaxCompute集群+GPU集群的模式
MaxCompute集群是分布式计算平台,但是如何让语音跑在上面是比较大的困难。比如Kaldi就有40多万行的代码,如果完全按照MaxCompute的框架重写是不现实的。
我们和MaxCompute团队合作基于MaxCompute volume的语音计算平台,关键的技术点当语音的job到MaxCompute运行的时候, scheduler先mount MaxCompute volume成为一个虚拟盘,然后现有的基于盘操作的代码就都可以已少量的改动来运行在MaxCompute里面了,还可以利用分布式的优势。基于这样的改动,我们系统的可扩展性有了很大的提升。
第三阶段,GPU集群和MaxCompute集群的合并
这个是我们希望将来达到的阶段。现在GPU集群和CPU集群式分别的系统,数据交换很麻烦。我们希望将来和其他团队合作完成这一步。