YARN HA实战v1.0
当前环境:hadoop+zookeeper(namenode,resourcemanager HA)
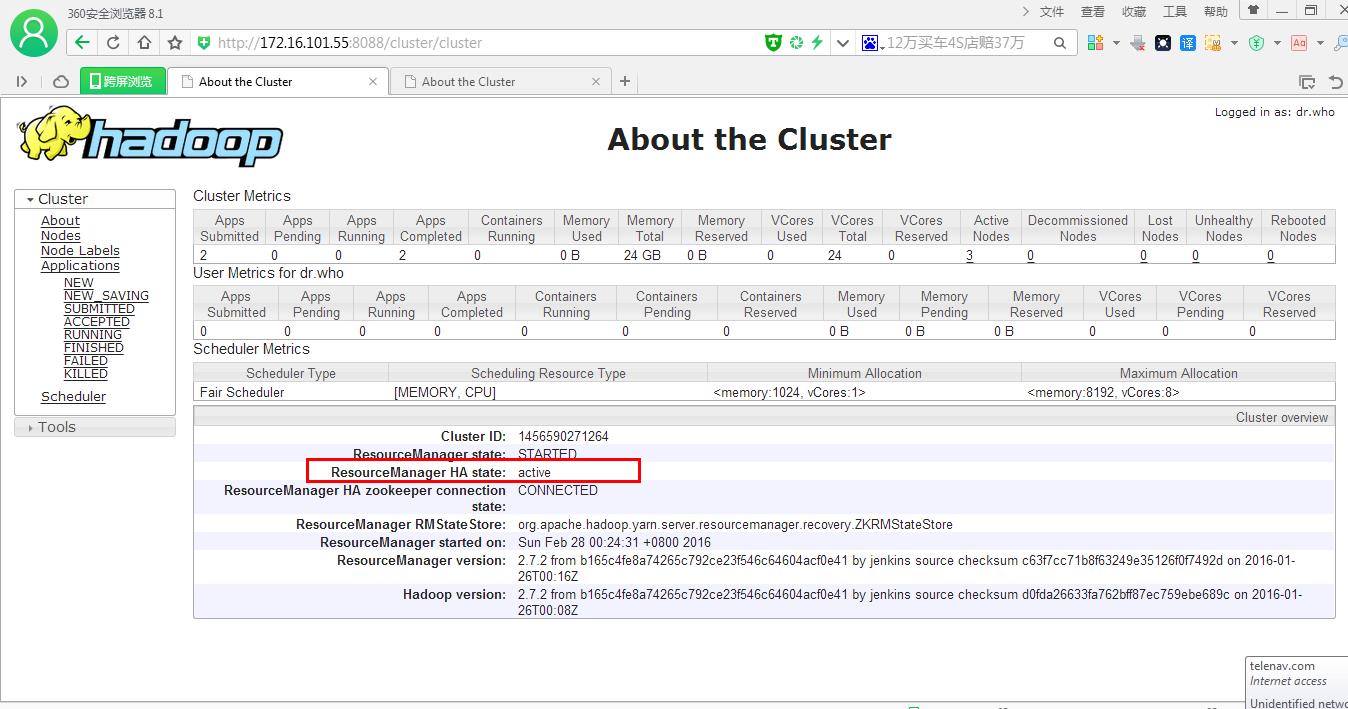
resourcemanager |
serviceId |
init status |
sht-sgmhadoopnn-01 |
rm1 |
active |
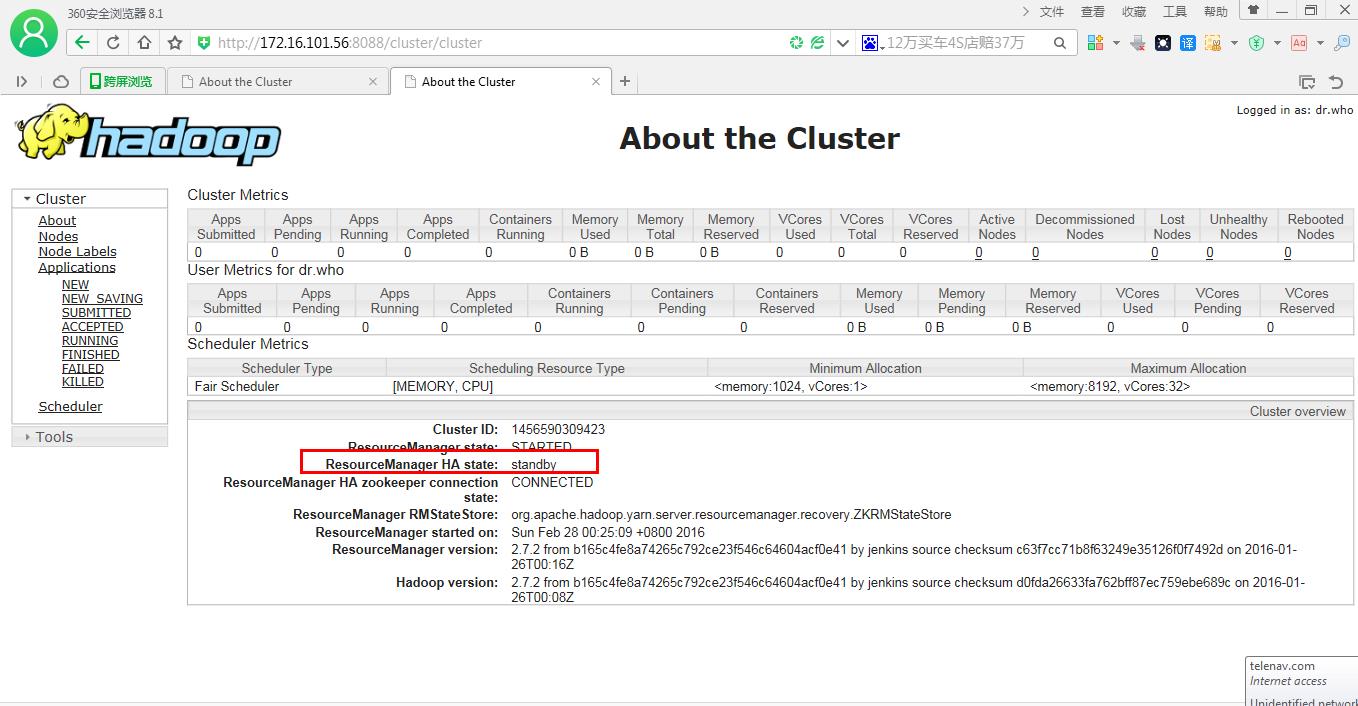
sht-sgmhadoopnn-02 |
rm2 |
standby |
参考:
http://blog.csdn.net/u011414200/article/details/50336735
http://blog.csdn.net/u011414200/article/details/50276257
一.查看resourcemanager是active还是standby
1.打开网页
http://172.16.101.55:8088/cluster/cluster
http://172.16.101.56:8088/cluster/cluster
![]()
![]()
2.查看resourcemanager日志
- [root@sht-sgmhadoopnn-01 logs]# more yarn-root-resourcemanager-sht-sgmhadoopnn-01.telenav.cn.log
- …………………..
- 2016-03-03 18:10:01,289 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioned to active state
- [root@sht-sgmhadoopnn-02 logs]# more yarn-root-resourcemanager-sht-sgmhadoopnn-02.telenav.cn.log
- …………………..
- 2016-03-03 18:10:34,250 INFO org.apache.hadoop.yarn.server.resourcemanager.metrics.SystemMetricsPublisher: YARN system metrics publishing service is not enabled
- 2016-03-03 18:10:34,250 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioning to standby state
3. yarn rmadmin –getServiceState
![]()
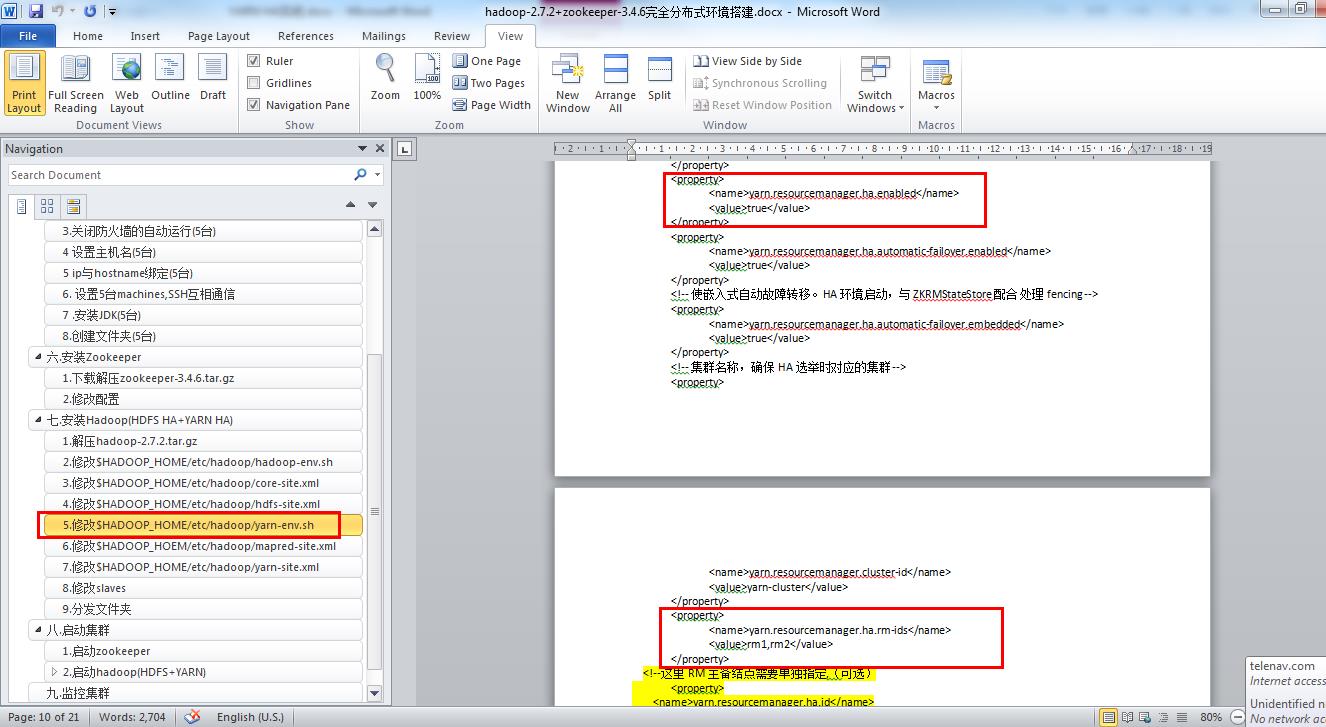
- ###$HADOOP_HOME/etc/hadoop/yarn-site.xml
- <property>
- <name>yarn.resourcemanager.ha.rm-ids</name>
- <value>rm1,rm2</value>
- </property>
-
-
- [root@sht-sgmhadoopnn-02 logs]# yarn rmadmin -getServiceState rm1
- active
- [root@sht-sgmhadoopnn-02 logs]# yarn rmadmin -getServiceState rm2
- standby
二
.
命令
- [root@sht-sgmhadoopnn-01 bin]# yarn --help
- Usage: yarn [--config confdir] [COMMAND | CLASSNAME]
- CLASSNAME run the class named CLASSNAME
- or
- where COMMAND is one of:
- resourcemanager -format-state-store deletes the RMStateStore
- resourcemanager run the ResourceManager
- nodemanager run a nodemanager on each slave
- timelineserver run the timeline server
- rmadmin admin tools
- sharedcachemanager run the SharedCacheManager daemon
- scmadmin SharedCacheManager admin tools
- version print the version
- jar <jar> run a jar file
- application prints application(s)
- report/kill application
- applicationattempt prints applicationattempt(s)
- report
- container prints container(s) report
- node prints node report(s)
- queue prints queue information
- logs dump container logs
- classpath prints the class path needed to
- get the Hadoop jar and the
- required libraries
- cluster prints cluster information
- daemonlog get/set the log level for each
- daemon
-
- ###########################################################################
- [root@sht-sgmhadoopnn-01 bin]# yarn rmadmin --help
- -help: Unknown command
- Usage: yarn rmadmin
- -refreshQueues
- -refreshNodes
- -refreshSuperUserGroupsConfiguration
- -refreshUserToGroupsMappings
- -refreshAdminAcls
- -refreshServiceAcl
- -getGroups [username]
- -addToClusterNodeLabels [label1,label2,label3] (label splitted by ",")
- -removeFromClusterNodeLabels [label1,label2,label3] (label splitted by ",")
- -replaceLabelsOnNode [node1[:port]=label1,label2 node2[:port]=label1,label2]
- -directlyAccessNodeLabelStore
- -transitionToActive [--forceactive] <serviceId>
- -transitionToStandby <serviceId>
- -failover [--forcefence] [--forceactive] <serviceId> <serviceId>
- -getServiceState <serviceId>
- -checkHealth <serviceId>
- -help [cmd]
transitionToActive
和
transitionToStandby
是用于在不同状态之间切换的。
failover 初始化一个故障恢复。该命令会从一个失效的resourcemanager切换到另一个上面(不支持在自动切换的环境操作)。
getServiceState 获取当前resourcemanager的状态。
checkHealth 检查resourcemanager的状态。正常就返回0,否则返回非0值。
三.实验
1.测试YARN的手工切换功能(失败)
- [root@sht-sgmhadoopnn-01 ~]# yarn rmadmin -failover --forceactive rm1 rm2
- forcefence and forceactive flags not supported with auto-failover enabled.
#yarn-site.xml 中设置yarn.resourcemanager.ha.automatic-failover.enabled为 true,故提示不能手动切换
2.测试YARN的自动切换功能(成功)
a.在active resoucemanager机器上通过jps命令查找到resoucemanager的进程号,然后通过kill -9的方式杀掉进程,观察另一个resoucemanager节点是否会从状态standby变成active状态
- [root@sht-sgmhadoopnn-01 ~]# yarn rmadmin -getServiceState rm1
- active
- [root@sht-sgmhadoopnn-01 ~]# yarn rmadmin -getServiceState rm2
- standby
-
- [root@sht-sgmhadoopnn-01 bin]# jps
- 2583 Jps
- 10162 DFSZKFailoverController
- 28432 ResourceManager
- 21679 NameNode
-
- [root@sht-sgmhadoopnn-01 ~]# kill -9 28432
-
- [root@sht-sgmhadoopnn-02 bin]# jps
- 19147 ResourceManager
- 17837 NameNode
- 17970 DFSZKFailoverController
- 27330 Jps
-
-
- [root@sht-sgmhadoopnn-01 bin]# yarn rmadmin -getServiceState rm1
- 16/03/03 19:23:39 INFO ipc.Client: Retrying connect to server: sht-sgmhadoopnn-01/172.16.101.55:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
- Operation failed: Call From sht-sgmhadoopnn-01.telenav.cn/172.16.101.55 to sht-sgmhadoopnn-01:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
-
-
-
- [root@sht-sgmhadoopnn-01 bin]# yarn rmadmin -getServiceState rm2
- active
- [root@sht-sgmhadoopnn-01 bin]#
#### sht-sgmhadoopnn-01 机器上resourcemanager进程已经起来,且状态为standby
c. 再次切换
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -transitionToStandby rm2
- Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@11f69937
- Refusing to manually manage HA state, since it may cause
- a split-brain scenario or other incorrect state.
- If you are very sure you know what you are doing, please
- specify the --forcemanual flag.
-
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -transitionToStandby --forcemanual rm2
- You have specified the --forcemanual flag. This flag is dangerous, as it can induce a split-brain scenario that WILL CORRUPT your HDFS namespace, possibly irrecoverably.
-
- It is recommended not to use this flag, but instead to shut down the cluster and disable automatic failover if you prefer to manually manage your HA state.
-
- You may abort safely by answering 'n' or hitting ^C now.
-
- Are you sure you want to continue? (Y or N) Y
- 16/03/03 19:29:36 WARN ha.HAAdmin: Proceeding with manual HA state management even though
- automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@4e33967b
-
-
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -getServiceState rm1
- standby
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -getServiceState rm2
- standby
-
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -transitionToActive rm1
- Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@54c4f317
- Refusing to manually manage HA state, since it may cause
- a split-brain scenario or other incorrect state.
- If you are very sure you know what you are doing, please
- specify the --forcemanual flag.
-
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -transitionToActive --forcemanual rm1
- You have specified the --forcemanual flag. This flag is dangerous, as it can induce a split-brain scenario that WILL CORRUPT your HDFS namespace, possibly irrecoverably.
-
- It is recommended not to use this flag, but instead to shut down the cluster and disable automatic failover if you prefer to manually manage your HA state.
-
- You may abort safely by answering 'n' or hitting ^C now.
-
- Are you sure you want to continue? (Y or N) Y
- 16/03/03 19:32:46 WARN ha.HAAdmin: Proceeding with manual HA state management even though
- automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@54c4f317
-
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -getServiceState rm1
- 16/03/03 19:32:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- active
- [root@sht-sgmhadoopnn-01 sbin]# yarn rmadmin -getServiceState rm2
- 16/03/03 19:33:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- standby
- [root@sht-sgmhadoopnn-01 sbin]#
#和HDFS HA切换实验不一样, -transitionToStandby,会自动将standby—>active,active-->standby;
而YARN HA就不一样,需要还有手动再执行一下-transitionToActive.