版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/44458825
使用hadoop版本为2.2.0
倒排索引简单的可以理解为全文检索某个词
例如:在a.txt 和b.txt两篇文章分别中查找统计hello这个单词出现的次数,出现次数越多,和关键词的吻合度就越高
现有a.txt内容如下:
hello tom
hello jerry
hello kitty
hello world
hello tom
b.txt内容如下:
hello jerry
hello tom
hello world
在hadoop平台上编写mr代码分析统计各个单词在两个文本中出现的次数
其实也只是WordCount程序的改版而已~
将两个文本上传到hdfs根目录的ii文件夹下(mr直接读取ii文件夹,会读取所有没有以_(下划线)开头的文件)
编写mr代码
首先分析,map输入的格式为
该行偏移量 该行文本
如:
0 hello
我们知道,map的输出之后会根据相同的key来进行合并
而每个单词都不是唯一的,它可能在两个文本中都出现,使用单词作为key的话无法分辨出该单词属于哪个文本
而使用文本名字作为key的话,那么将达到我们原来的目的,因为map的输出就会变成a.txt->单词..单词..单词
这显然不是我们想要的结果
所以map输出的格式应该为
单个单词->所在文本 1
如:
hello->a.txt 1
这里用->作为单词和所在文本的分隔
这样就可以在根据key进行合并的时候不会影响到我们的结果
map代码如下:
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text k = new Text();
private Text v = new Text();
protected void map(
LongWritable key,
Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>.Context context)
throws java.io.IOException, InterruptedException {
String[] data = value.toString().split(" ");
//FileSplit类从context上下文中得到,可以获得当前读取的文件的路径
FileSplit fileSplit = (FileSplit) context.getInputSplit();
//文件路径为hdfs://hadoop:9000/ii/a.txt
//根据/分割取最后一块即可得到当前的文件名
String[] fileNames = fileSplit.getPath().toString().split("/");
String fileName = fileNames[fileNames.length - 1];
for (String d : data) {
k.set(d + "->" + fileName);
v.set("1");
context.write(k, v);
}
};
}
在map执行完毕之后
我们需要一个combiner来帮助完成一些工作
注意,combiner的输入格式和输出格式是一致的,也就是map的输出格式,否则会出错
再次分析,根据key合并value之后的键值对是这个样子的:
(hello->a.txt,{1,1,1,1,1})
combiner要做的工作就是讲values统计累加
并将key的单词和文本分隔开,将文本名和统计之后的values组合在一起形成新的value
如:
(hello,a.txt->5)
为什么要这么做?
因为在combiner执行完毕之后
还会根据key进行一次value的合并,跟map之后的是一样的
将key相同的value组成一个values集合
如此一来,在经过combiner执行之后,到达reduce的输入就变成了
(hello,{a.txt->5,b.txt->3})
这样的格式,然后在reduce中循环将values输出不就是我们想要的结果了吗~
combiner代码如下:
public static class MyCombiner extends Reducer<Text, Text, Text, Text> {
private Text k = new Text();
private Text v = new Text();
protected void reduce(
Text key,
java.lang.Iterable<Text> values,
org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, Text>.Context context)
throws java.io.IOException, InterruptedException {
//分割文件名和单词
String[] wordAndPath = key.toString().split("->");
//统计出现次数
int counts = 0;
for (Text t : values) {
counts += Integer.parseInt(t.toString());
}
//组成新的key-value输出
k.set(wordAndPath[0]);
v.set(wordAndPath[1] + "->" + counts);
context.write(k, v);
};
}
接下来reduce的工作就简单了
代码如下:
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
private Text v = new Text();
protected void reduce(
Text key,
java.lang.Iterable<Text> values,
org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, Text>.Context context)
throws java.io.IOException, InterruptedException {
String res = "";
for (Text text : values) {
res += text.toString() + "\r";
}
v.set(res);
context.write(key, v);
};
}
main方法代码:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path inPath = new Path("hdfs://hadoop:9000" + args[0]);
Path outPath = new Path("hdfs://hadoop:9000" + args[1]);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(InverseIndex.class);
FileInputFormat.setInputPaths(job, inPath);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(MyCombiner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, outPath);
job.setOutputFormatClass(TextOutputFormat.class);
job.waitForCompletion(true);
}
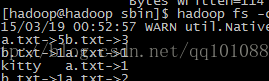
在hadoop上运行jar包执行结果如图:
![]()
初学hadoop,仅作笔记之用,其中如有错误望请告知^-^