来源:http://suxain.iteye.com/blog/1748356
hadoop 是工作在linux下的分布式系统,做为一个开发者,对于手里资源有限,不得不使用只有终端的虚拟机来运行hadoop集群。但是,在这种环境下,开发,调试就变得那么的不容易了。那么,有没有办法在windows下发调试呢。答案是肯定的。
hadoop为我们提供了一个Eclipes插件,使用我们可以在Eclipse环境下开发,调试hadoop程序,那么,应该如何安装eclipse-hadoop插件呢。下面把我的研究结果分享给大家(附上我自己编译的插件)。
1、编译eclipse-hadoop-plugins
在hadoop目录下的找到/src/contrib/eclipse-plugin,用eclipse导入该project,
![]()
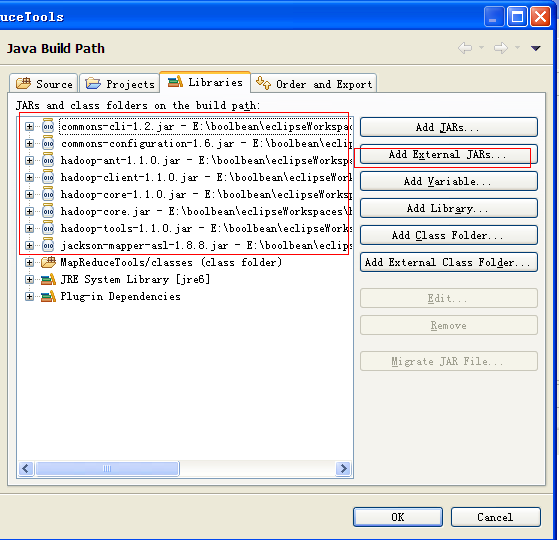
由于插件需要hadoop的一些JAR 文件,所以,右键单击项目->build path ->configuretion build path->libraies->add External jars 。在hadoop的目录和其lin目录找到下面的jar,并加入
![]()
然后打开 build-contrib.xml
修改以下地方
<property name="hadoop.root" location="E:\boolbean\eclipseWorkspaces\hadoop-1.1.0" />
<property name="eclipse.home" location="D:/Program Files/eclipse" />
<property name="version" value="1.1.0" />
然后右击 build.xml -> run as -> ant build...
编译成功后,到${hadoop.root}/build/contrib/eclipse-plugin/找到hadoop-eclipse-plugin-1.1.0.jar,
将该JAR复制到eclipse安装目录的 plugins目录下,重启eclipse。
待eclipse重启后,选择window->Preferences,出现如图效果,刚安装成功

交且可以在 Projects Explorer里看到DFS Location
然后单击 window -> show views -> others ,找到Map/Reduce Locations,显示MapReduce视图
![]()
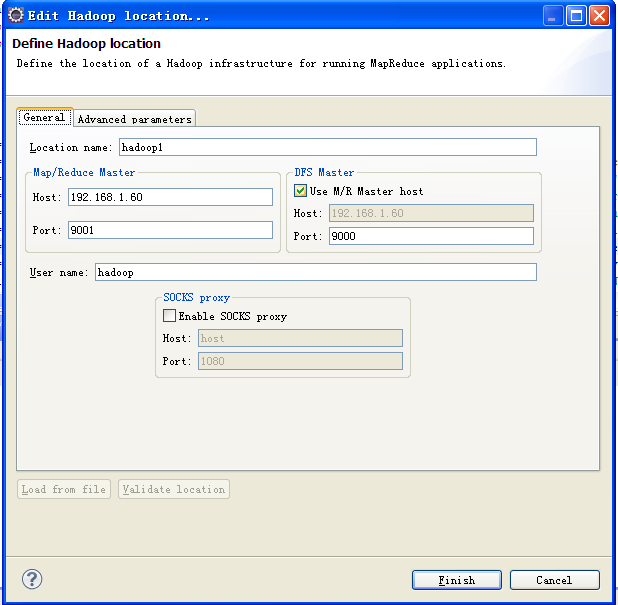
右击,选择Edit hadoop location...
![]()
Location name ,自定,无要求
Map/Reduce Master 对应 mapred-site.xml中设置的IP和端口
DFS Master core-site.xml 中的IP和端口
在 Advanced 中,有各项设置参数,在里面,对core-site.xml、hdfs-site.xml、mapred-site.xml中设置过的参数,在这里也做相应的修改。
然后 Finish
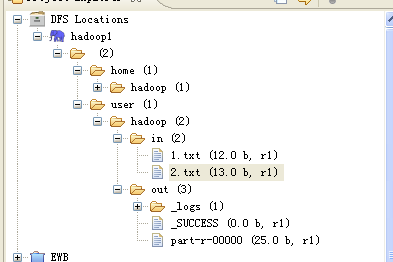
若成功,在DFS Location出现hdfs目录结构
![]()
在eclipse连接hadoop的时候,要关闭linux防火墙,或者编辑iptables过虑规则。
以上是本人纠结了很多天纠结出来的结果。编译安装过程中,新我这样的新手会遇到很多问题,各种谷歌,百度。另外,在连接hadoop的时候,把 eclipse 的 Error log 视图显示出来,可以让我们看到很详细的错误说明。以便找准方向解决问题。当遇到问题是,不防假设,问题会出在哪里。
![img_e00999465d1c2c1b02df587a3ec9c13d.jpg]()
微信公众号: 猿人谷
如果您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】
如果您希望与我交流互动,欢迎关注微信公众号
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。