Hadoop 集群搭建
目录
集群简介
服务器准备
环境和服务器设置
JDK环境安装
Hadoop安装部署
启动集群
测试
集群简介
在进行集群搭建前,我们需要大概知道搭建的集群都是些啥玩意。
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者在逻辑上分离,但物理上常在一起(啥意思?就是说:HDFS集群和YARN集群,他们俩是两个不同的玩意,但很多时候都会部署在同一台物理机器上)
HDFS集群:负责海量数据的存储,集群中的角色主要有
NameNode (DataNode的管理者,负责保存元数据)
DataNode (负责保存具体的数据内容)
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有
ResourceManager (NodeManager的管理者,负责NodeManager的调用等)
NodeManager (当ResourceManager进行调用时,负责调用本地的运算资源等)
那mapreduce是什么呢?它其实是集群中一个应用程序开发包,放在yarn集群上面跑。
搭建构思
本集群搭建案例,以3节点为例进行搭建,角色分配如下:
| 服务器 |
角色1 |
角色2 |
角色3 |
| note1 |
NameNode |
ResourceManager |
|
| note2 |
DataNode |
NodeManager |
SecondaryNameNode |
| note3 |
DataNode |
NodeManager |
|
解析:
note1服务器担任的角色为NameNode和ResourceManager(即note1服务器为HDFS集群的NameNode节点,同时也是YARN集群的ResourceManager节点)
note2 服务器担任的角色为 DataNode 、 NodeManager 和 SecondaryNameNode(同上)
note3 服务器担任的角色为 DataNode 和 NodeManager(同上)
(ps:本来节点名字想打node的,错打成note,懒得改.)
服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
Vmware12.0
Centos6.5 64bit
下载安装过程就省略啦,网上链接和教程一大把。
环境和服务器设置
在进行网络准备的前提,是安装Vmware,新建三台虚拟机。
注:以下操作在root用户下操作。
配置虚拟机桥接方式,采用NAT方式联网
配置Linux的网络配置文件,具体设置步骤如下:
-
1、配置/etc/sysconfig/network-scripts/ifcfg-eth0
`shell> su root #切换为root用户`
`shell> vi /etc/sysconfig/network-scripts/ifcfg-eth0 #编辑配置文件`
配置内容如下(修改下面有值的项,没有的加上):
> DEVICE="..."
> BOOTPROTO="static" #设置为静态IP
> HWADDR="....."
> IPV6INIT="..."
> NM_CONTROLLED="...."
> ONBOOT="yes"
> TYPE="......"
> UUID=".........."
> IPADDR="192.168.88.3" #IP地址
> NETMASK="255.255.255.0" # 子网掩码
> GATEWAY="192.168.88.1" #网关地址
-
2、重启网络服务,使配置生效。
`shell> service network restart # 重启网络服务`
-
添加hadoop用户并添加sudo权限
shell> useradd hadoop #添加用户hadoop
shell> passwd hadoop #设置用户hadoop的密码
shell> chmod u+w /etc/sudoers # 添加写权限
shell> vi /etc/sudoers
进入编辑模式,找到这一 行:"root ALL=(ALL) ALL"在起下面添加"hadoop ALL=(ALL) ALL",然后保存退出。
shell> chmod u-w /etc/sudoers #撤销写权限
设置服务器时间同步
date -s "2016-08-18 12:21:00
-
修改主机名
shell> vi /etc/sysconfig/network
配置内容如下:
NETWORKING=yes
HOSTNAME=note1
-
配置内网域名映射
配置/etc/hosts配置文件:
shell> vi /etc/hosts
配置内容如下:
192.168.88.3 note1
192.168.88.4 note2
192.168.88.5 note3
-
配置ssh免密登陆
生成ssh免登陆密钥
shell> cd ~/.ssh #进入到我的home目录
shell> ssh-keygen -t rsa #(四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
shell> ssh-copy-id localhost
配置防火墙
因为需要进行免密登录,所以要对防火墙进行关闭。
shell> service iptables status #查看防火墙状态
shell> service iptables stop #关闭防火墙
shell> chkconfig iptables --list #查看防火墙开机启动状态
shell> chkconfig iptables off #关闭防火墙开机启动
shell> reboot # 重启
JDK环境安装
解压jdk
创建一个目录app来放置解压后的文件
shell> mkdir /home/hadoop/app #创建文件夹
shell> tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app #解压
-
配置环境变量
解压完毕后需要将java添加到环境变量中,并使其生效
shell> vi /etc/profile
在文件最后添加一下内容:
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
刷新配置,使其生效
shell> source /etc/profile
Hadoop安装部署
-
解压Hadoop安装包
解压到app目录下
shell> tar -zxvf hadoop-2.7.3.tar.gz -C /home/hadoop/app #解压
修改配置文件
配置文件都放在解压目录下的etc/hadoop/目录下(我这里的目录为/home/hadoop/app/hadoop-2.7.3/etc/hadoop/),但我们只对一部分的项进行配置,没有配置的项都将使用默认值。配置项是以xml的格式来进行的,最简化配置如下:
-
配置hadoop-env.sh
shell> vi hadoop-env.sh
在hadoop-env.sh配置文件中加入以下内容:
export JAVA_HOME=/home/hadoop/apps/jdk1.7.0_51 # JDK路径
-
配置core-site.xml
shell> vi core-site.xml
在core-site.xml配置文件中加入以下内容:
<configuration>
`<property>` `<name>fs.defaultFS</name>` `<value>hdfs://note1:9000</value>` `</property>`
<property>
<name>hadoop.tmp.dir</name>
<value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value>
</property>
</configuration>
-
配置hdfs-site.xml
在用户目录下(/home/hadoop)创建一个data目录,用来存放HDFS产生的数据。然后对hdfs-site.xml进行配置
shell> mkdir /home/hadoop/data
shell> vi hdfs-site.xml
在hdfs-site.xml配置文件中加入以下内容:
<configuration>
`<property>` `<name>dfs.namenode.name.dir</name>` `<value>/home/hadoop/data/name</value>` `</property>`
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/data</value>
</property>
`<property>` `<name>dfs.replication</name>` `<value>3</value>` `</property>`
<property>
<name>dfs.secondary.http.address</name>
<value>note2:50090</value>
</property>
</configuration>
-
配置mapred-site.xml
shell> vi mapred-site.xml
在mapred-site.xml配置文件中加入以下内容:
<configuration>
``
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
-
配置yarn-site.xml
shell> vi yarn-site.xml
在yarn-site.xml配置文件中加入以下内容:
<configuration>
`<property>` `<name>yarn.resourcemanager.hostname</name>` `<value>hadoop01</value>` `</property>`
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
-
配置salves
salves文件配置的内容是集群的主机地址
shell> vi salves
在salves配置文件中加入以下内容:
note1 #主机名,通过/etc/hosts文件映射为IP地址
note2
note3
注意:以上所有配置(除了免密登录外,免密登录只需要在NameNode节点配置即可)都要在所有节点服务器进行配置。
启动集群
初始化HDFS集群
bin/hadoop namenode -format
启动HDFS集群
sbin/start-dfs.sh
启动YARN集群
sbin/start-yarn.sh
当然,你也可以使用sbin/start-all.sh这个命令同时把HDFS和YARN集群启动,但是在做实验时不建议这样做,因为这样启动出现问题就不好定位了。在实际生产中,如果集群数量比较大,可以使用脚本进行启动。
注意:一般情况下HDFS和YARN集群的主节点(NameNode和ResourceManager物理上都是在同一服务器的)使用命令进行启动即可,其他节点会被主节点通过免密登录自动启动的。
测试
1、启动HDFS集群成功,通过jps命令查看,进程2521 为NameNode进程
![img_89c2125a9a92c344376ac5d9ef9654e0.png]()
启动HDFS集群
2、启动Yarn集群成功,通过jps命令查看,进程2803位 ResourceManager进程
![img_bc42bb2afae7025149708b4f5887223d.png]()
启动yarn集群
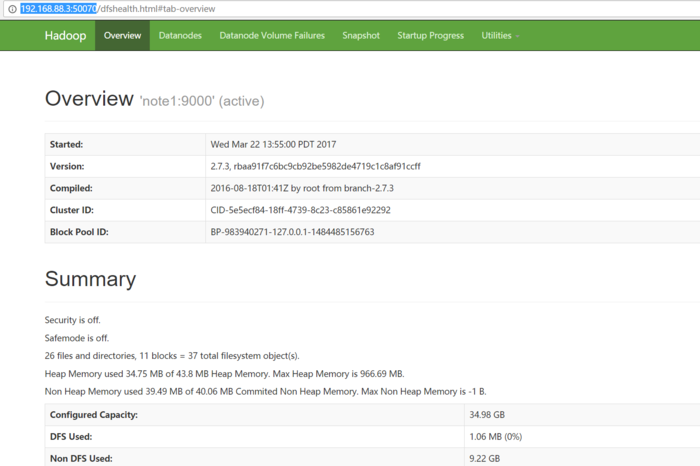
3、在浏览器查看HDFS集群(访问主节点的50070端口即可),浏览器中输入192.168.88.3:50070
![img_128403331046c6c0165f8952d6dae8f3.png]()
HDFS集群信息
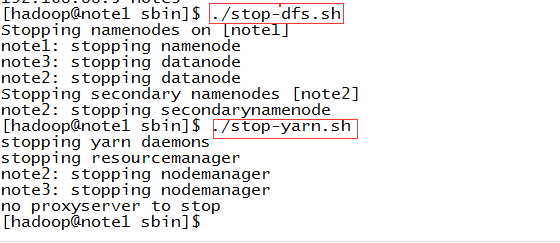
4、停止Hadoop集群,可以分别停止(分别使用stop-dfs.sh和stop-yarn.sh),当然你也可以一步停止集群(使用stop-all.sh)
![img_a23962c5c645ef5618149f4242d97a6c.png]()
停止集群
至此,Hadoop集群搭建完毕。