一、市场份额
1.简介
Sphinx
优势:
- Sphinx是一个基于SQL的C++开发的开源全文检索引擎,在1千万条记录情况下的查询速度为0.x秒(毫秒级)
- 始于2001年,近20年的市场打磨(本文基于目前最新版3.0.3)
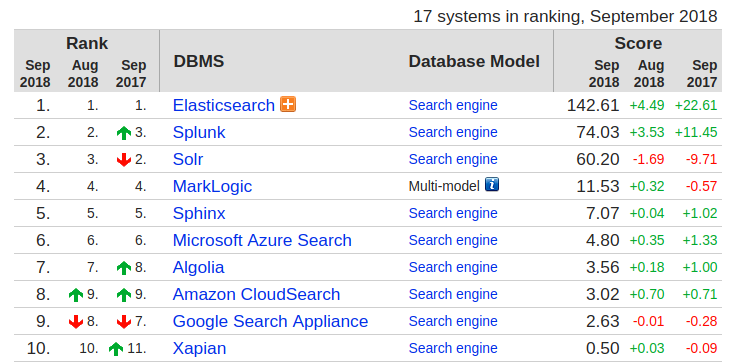
- 搜索引擎市场份额占比排名第5
- 阿里云RDS中有1款Mysql存储引擎:SphinxSE就是为此配套,支持SQL JOIN
- 提供SphinxQL,像使用SQL一样使用搜索引擎
- PHP官网文档目前收录了4款搜索引擎扩展,其中1种就是Sphinx
二、基础概念
1.搜索引擎
搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
![]()
2.数据源
数据来源,目前系统支持一些主流存储产品的自动对接。 比如:mysql, pgsql, mssql, xmlpipe, xmlpipe2, odbc... 支持写SQL JOIN语句,作为数据来源。
3.分词
对推送上来的文档进行词组切分,本文使用的是一元分词法,并非中文分词、盘古分词等。 一元分词: 我爱中国 将会分成 我 爱 中 国
4.索引
- 主索引:type=plain 通过SQL语句控制数据源范围
- 增量索引:type=plain 通过SQL语句控制数据源范围
- 实时索引:type=rt 在内存中CRUD进行搜索控制的类SQL操作
- 分布式索引:type=distributed 上述3种的结合,且可夸服务器拼接数据
5.幽灵数据
场景
在主索引中,有篇文章:我要吃饭
后来更改为:我要喝酒,并建立增量索引
这时在增量索引中搜新数据 喝酒 可以搜到,搜旧数据 吃饭 还是能搜到。
如何确保主索引在大数据下文档更新的及时性?
三、实战演练
1.准备数据源
2个函数
DELIMITER $$
CREATE DEFINER=`root`@`localhost` FUNCTION `rand_num`(`start_number` INT(11) UNSIGNED, `end_number` INT(11) UNSIGNED) RETURNS int(11)
BEGIN
DECLARE i int default 0;
set i = FLOOR(start_number+RAND() * (end_number-start_number+1));
return i;
END$$
DELIMITER ;
DELIMITER $$
CREATE DEFINER=`root`@`localhost` FUNCTION `rand_string`(`number` INT(11) UNSIGNED) RETURNS varchar(1024) CHARSET utf8
BEGIN
DECLARE chars_str varchar(1024) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789【买2免1】荣诚月饼纳福吉祥4口味月饼520g/袋中秋传统糕点点心配送范围送货范围仅限常州、扬州、苏州、盐城、徐州、宿迁、淮安、泰州、无锡、连云港、南通、镇江、南京地区(生鲜类别仅限部分地区)支付方式检测到您当前处于非安全网络环境,部分商品信息可能不准确,请在交易支付页面再次确认商品价格信息哈啊';
DECLARE return_str varchar(1024) DEFAULT '';
DECLARE i int DEFAULT 0;
WHILE i < number DO
set return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*200),1));
set i=i+1;
END while;
RETURN return_str;
END$$
DELIMITER ;
1个存储过程
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_main`(IN `number` INT(10) UNSIGNED)
BEGIN
DECLARE i int default 0;
# 设置自动提交为false
set autocommit =0;
# 开启循环
REPEAT
set i = i+1;
insert into main values(null,rand_num(0,999999999),rand_string(rand_num(0,1024)));
UNTIL i=number
END REPEAT;
commit;
END$$
DELIMITER ;
3个表
CREATE TABLE `add` (
`type` int(10) unsigned NOT NULL,
`id` int(10) unsigned NOT NULL,
PRIMARY KEY (`type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `change` (
`type` int(10) unsigned NOT NULL,
`id` int(10) unsigned NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `main` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`type` int(10) unsigned NOT NULL DEFAULT '0',
`beizhu` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
生成1亿条测试数据:23.1GiB
mysql -uroot -p123456;
use test;
call insert_main(100000000);
mysql> SELECT COUNT(*) FROM `main`;
+----------+
| COUNT(*) |
+----------+
| 100000000 |
+----------+
1 row in set (4 min 38.74 sec)
2.安装Sphinx
wget -P ~/ http://sphinxsearch.com/files/sphinx-3.0.3-facc3fb-linux-amd64.tar.gz
mkdir ~/sphinx
cd ~/sphinx
tar -xzvf ~/sphinx-3.0.3-facc3fb-linux-amd64.tar.gz -C ./ --strip-components 1
mkdir log/ data/
3.搜索配置
sudo vim ~/sphinx/etc/sphinx.conf
1/8.主数据源
source main
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass = 123456
sql_db = test
sql_port = 3306
sql_query_pre = SET NAMES utf8
sql_query_pre = REPLACE INTO `add` SELECT 1,MAX(id) FROM `main`
sql_query_pre = TRUNCATE `change`
sql_query = SELECT `id`, `type`, `beizhu` FROM `main` WHERE `id`<=( SELECT `id` FROM `add` WHERE `type`=1)
sql_attr_uint = type
}
2/8增量数据源
source zengliang:main
{
sql_query_pre = SET NAMES utf8
sql_query_pre =
sql_query_pre =
sql_query = SELECT `id`, `type`, `beizhu` FROM `main` WHERE `id`>( SELECT `id` FROM `add` WHERE `type`=1) UNION SELECT `id`, `type`, `beizhu` FROM `main` WHERE `id` IN(SELECT `id` FROM `change` WHERE `type`=1)
sql_query_killlist = SELECT `id` FROM `change` WHERE `type`=1
}
3/8主索引
其中ngram_chars配置在unicode官网可以查到,比如中文汉字通用的unicode编码范围。
index main
{
source = main
path = /home/letwang/sphinx/data/main
min_infix_len = 2
ngram_len = 1
ngram_chars = U+3000..U+2FA1F
kbatch = main
}
4/8增量索引
index zengliang:main{
source = zengliang
path = /home/letwang/sphinx/data/zengliang
}
5/8实时索引
index shishi
{
type = rt
rt_mem_limit = 128M
rt_attr_uint = type
rt_field = beizhu
path = /home/letwang/sphinx/data/shishi
min_infix_len = 2
ngram_len = 1
ngram_chars = U+3000..U+2FA1F
}
6/8分布式索引
index fenbushi
{
type = distributed
agent =127.0.0.1:9312:main #local = main
agent =127.0.0.1:9312:zengliang #local = zengliang
agent =127.0.0.1:9312:shishi #local = shishi
}
7/8索引器
indexer
{
mem_limit = 1024M
}
8/8守护服务
searchd
{
listen = 9312
listen = 9306:mysql41
log = /home/letwang/sphinx/log/searchd.log
query_log = /home/letwang/sphinx/log/query.log
read_timeout = 5
max_children = 30
pid_file = /home/letwang/sphinx/log/searchd.pid
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
workers = threads
dist_threads = 4
binlog_path = /home/letwang/sphinx/data
}
4.重建全量索引
~/sphinx/bin/indexer -c ~/sphinx/etc/sphinx.conf --all --rotate
Sphinx 3.0.3 (commit facc3fb)
using config file '/home/letwang/sphinx/etc/sphinx.conf'...
indexing index 'main'...
collected 100000000 docs, 17421.4 MB
sorted 6623.4 Mhits, 100.0% done
total 100000000 docs, 17.42 Gb
total 2819.8 sec, 6.178 Mb/sec, 35464 docs/sec
indexing index 'zengliang'...
collected 0 docs, 0.0 MB
total 0 docs, 0.0 Kb
total 0.0 sec, 0.0 Kb/sec, 0 docs/sec
skipping non-plain index 'shishi'...
skipping non-plain index 'fenbushi'...
5.启动Sphinx
~/sphinx/bin/searchd -c ~/sphinx/etc/sphinx.conf
Sphinx 3.0.3 (commit facc3fb)
using config file '/home/letwang/sphinx/etc/sphinx.conf'...
listening on all interfaces, port=9312
listening on all interfaces, port=9306
precaching index 'main'
rotating index 'main': success
precaching index 'zengliang'
rotating index 'zengliang': success
precaching index 'shishi'
precached 3 indexes in 0.130 sec
停止服务:
~/sphinx/bin/searchd -c ~/sphinx/etc/sphinx.conf --stopwait
6.SphinxQL查看搜索引擎状态
➜ ~ mysql -h127.0.0.1 -P9306
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 3.0.3 (commit facc3fb)
mysql> show databases;
Empty set (0.00 sec)
mysql> show tables;
+-----------+-------------+
| Index | Type |
+-----------+-------------+
| fenbushi | distributed |
| main | local |
| shishi | rt |
| zengliang | local |
+-----------+-------------+
4 rows in set (0.00 sec)
7.生成增量索引
➜ ~ mysql -uroot -p123456;
mysql> call insert_main(1);
~/sphinx/bin/indexer -c ~/sphinx/etc/sphinx.conf zengliang --rotate
Sphinx 3.0.3 (commit facc3fb)
Copyright (c) 2001-2018, Andrew Aksyonoff
Copyright (c) 2008-2016, Sphinx Technologies Inc (http://sphinxsearch.com)
using config file '/home/letwang/sphinx/etc/sphinx.conf'...
indexing index 'zengliang'...
collected 1 docs, 0.0 MB
sorted 0.0 Mhits, 100.0% done
total 1 docs, 0.5 Kb
total 0.1 sec, 4.8 Kb/sec, 10 docs/sec
rotating indices: successfully sent SIGHUP to searchd (pid=11713).
8.合并增量索引到主索引(可选操作)
mysql> select * from zengliang;
+-----------+-----------+
| id | type |
+-----------+-----------+
| 100000001 | 172620683 |
+-----------+-----------+
1 row in set (0.00 sec)
~/sphinx/bin/indexer -c ~/sphinx/etc/sphinx.conf --merge main zengliang --rotate
Sphinx 3.0.3 (commit facc3fb)
using config file '/home/letwang/sphinx/etc/sphinx.conf'...
merging index 'zengliang' into index 'main'...
merged 7233.8 Kwords
merged in 1590.479 sec
rotating indices: successfully sent SIGHUP to searchd (pid=7718).
9.使用实时索引
➜ ~ mysql -h127.0.0.1 -P9306
mysql> DESC shishi;
+--------+--------+------------+------+
| Field | Type | Properties | Key |
+--------+--------+------------+------+
| id | bigint | | |
| beizhu | field | indexed | |
| type | uint | | |
+--------+--------+------------+------+
3 rows in set (0.00 sec)
mysql> INSERT INTO `shishi` values (1, '我是中国人', 11);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO `shishi` values (2, '我要吃饭', 22);
Query OK, 1 row affected (0.01 sec)
mysql> select * from shishi WHERE MATCH('"*我*"');
| id | type |
+------+------+
| 1 | 11 |
| 2 | 22 |
+------+------+
2 rows in set (0.00 sec)
Tips:你也可以近似疯狂的把主索引数据切换到实时索引中
mysql> TRUNCATE RTINDEX shishi;
mysql> ATTACH INDEX main TO RTINDEX shishi;
10.搜索分布式索引
mysql> SELECT * FROM `fenbushi` WHERE MATCH('"*鲜中交货淮州*"') LIMIT 10;
| id | type |
| 100000001 | 172620683 |
1 row in set, 1 warning (1.01 sec)
mysql> select count(*) from fenbushi;
| count(*) |
| 100000003 |
1 row in set (1.01 sec)
mysql> select count(*) from main;
| count(*) |
| 100000000 |
1 row in set (0.95 sec)
mysql> select count(*) from zengliang;
| count(*) |
| 1 |
1 row in set (0.00 sec)
mysql> select count(*) from shishi;
| count(*) |
| 2 |
1 row in set (0.00 sec)
11.定时任务
crontab -e
*/1 * * * * /bin/sh ~/sphinx/bin/indexer -c ~/sphinx/etc/sphinx.conf zengliang --rotate
*/720 * * * * /bin/sh ~/sphinx/bin/indexer -c ~/sphinx/etc/sphinx.conf --merge main zengliang --rotate
30 1 * * * /bin/sh ~/sphinx/bin/indexer -c ~/sphinx/etc/sphinx.conf --all --rotate
每1分钟执行一遍增量索引
每720分钟执行一遍合并索引
每天1:30执行整体索引
12.准备搜索
从主索引里搜索数据
mysql> SELECT * FROM `main` WHERE MATCH('"*仅非确息类*"');
1 row in set (0.95 sec)
从增量索引里搜索数据
mysql> SELECT * FROM `zengliang` WHERE MATCH('"*仅非确息类*"');
0 row in set (0.01 sec)
从实时索引里搜索数据
mysql> SELECT * FROM `shishi` WHERE MATCH('"*仅非确息类*"');
0 row in set (0.02 sec)
从分布式索引里搜索数据
mysql> SELECT * FROM `fenbushi` WHERE MATCH('"*仅非确息类*"');
1 row in set (0.80 sec)
搜索调试
mysql> SHOW META;
| Variable_name | Value |
| total | 1 |
| total_found | 1 |
| time | 0.80 |
| keyword[0] | 仅 |
| docs[0] | 24152970 |
| hits[0] | 74754214 |
| keyword[1] | 非 |
| docs[1] | 16617532 |
| hits[1] | 37394418 |
| keyword[2] | 确 |
| docs[2] | 23187798 |
| hits[2] | 49207648 |
| keyword[3] | 息 |
| docs[3] | 23188209 |
| hits[3] | 49235777 |
| keyword[4] | 类 |
| docs[4] | 16628887 |
| hits[4] | 37414147 |
18 rows in set (0.00 sec)
13.总结
性能指标
total 100000000 docs, 17.42 Gb
Ubuntu 14.04 64bit
Intel:registered: Core:tm: i5-6500 CPU @ 3.20GHz × 4
Intel:registered: HD Graphics 530 (Skylake GT2)
2*4G 2133 MHz
ATA Disk Seagate 976.0 GB
属性筛选:300-400 毫秒
全文检索:1秒左右
搜索引擎Sphinx亿级数据大并发实时搜索通用架构设计方案
- 客户搜索【分布式索引】,其已包含:【主索引】、【增量索引】、【实时索引】
- 定时任务每分钟更新 【增量索引】,解决幽灵数据问题,达到准实时搜索
- 当用户操作数据时,同步到实时索引中,达到实时搜索;实时索引重启不会丢失数据
四、附录
PPT中所用的文件地址
- https://baike.baidu.com/item/Sphinx/14627
- http://sphinxsearch.com/
- http://sphinxsearch.com/wiki/doku.php?id=third_party
- http://php.net/manual/zh/book.sphinx.php
- https://db-engines.com/en/ranking/search+engine