Java动态代理之JDK实现和CGlib实现(简单易懂)
转自:https://www.cnblogs.com/ygj0930/p/6542259.html
该文章综合了几本书的内容.
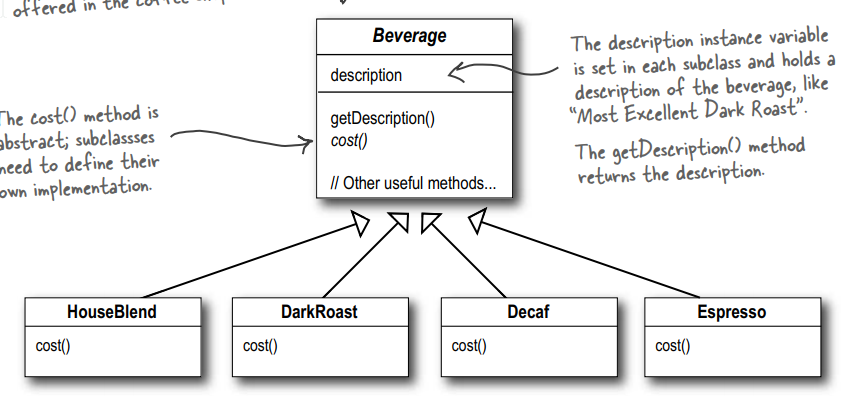
某咖啡店供应咖啡, 客户买咖啡的时候可以添加若干调味料, 最后要求算出总价钱.
Beverage是所有咖啡饮料的抽象类, 里面的cost方法是抽象的. description变量在每个子类里面都需要设置(表示对咖啡的描述).
每个子类实现cost方法, 表示咖啡的价格.
除了这些类之外, 还有调味品:
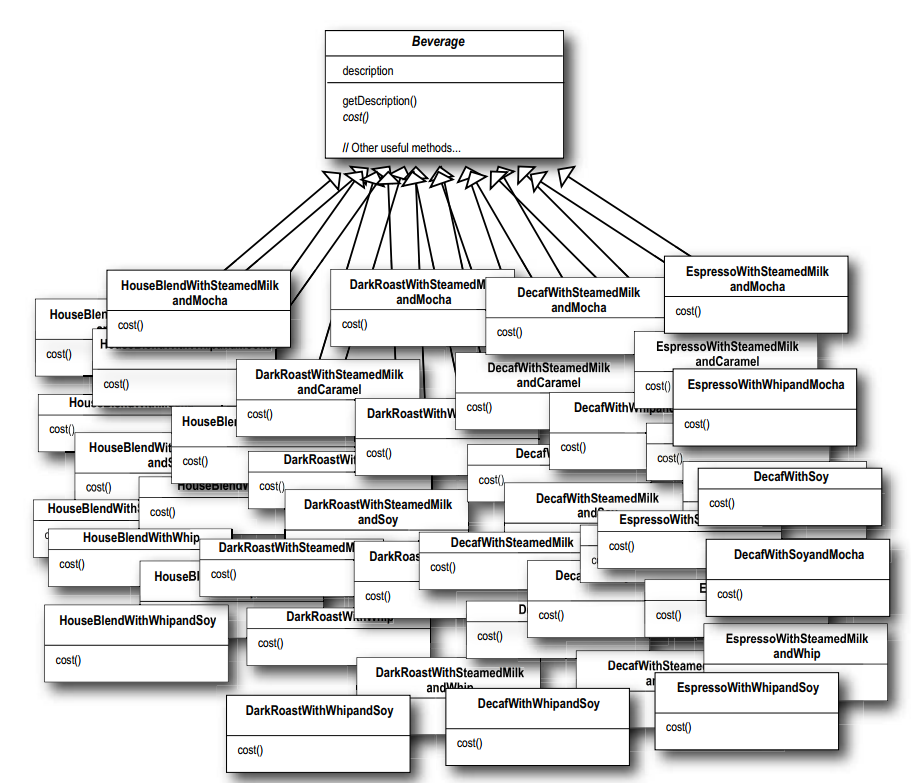
问题是调味品太多了, 如果使用继承来做的话, 各种组合简直是类的爆炸.
而且还有其他的问题, 如果牛奶的价格上涨了怎么办? 如果再加一种焦糖调料呢?
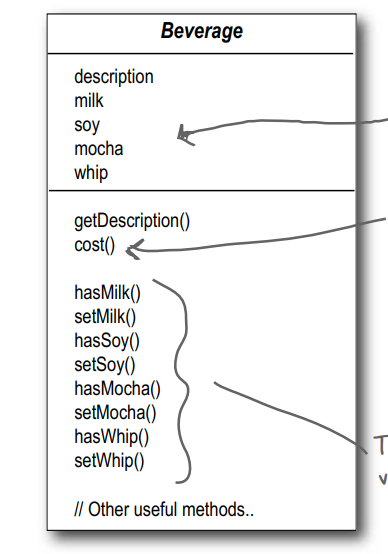
父类里面有调味料的变量(bool), 并且在父类里面直接实现cost方法(通过是否有某种调味料来计算价格).
子类override父类的cost方法, 但是也调用父类的cost方法, 这样就可以把子类这个咖啡的价格和父类里计算出来的调味料的价格加到一起算出最终的价格了.
下面就是:
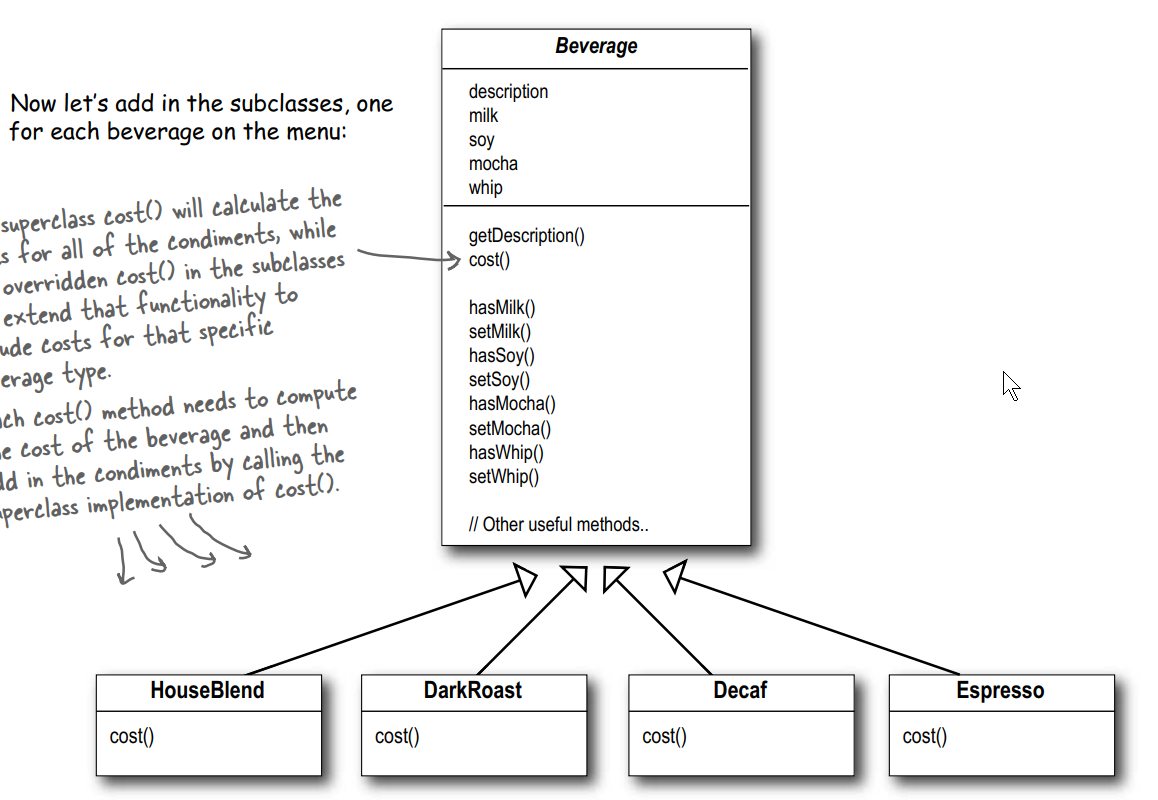
看起来不错, 那么, 问题来了:
类应该对扩展开放 而对修改关闭.
使用装饰模式, 我们可以购买一个咖啡, 并且在运行时使用调味料对它进行装饰.
大约步骤如下:

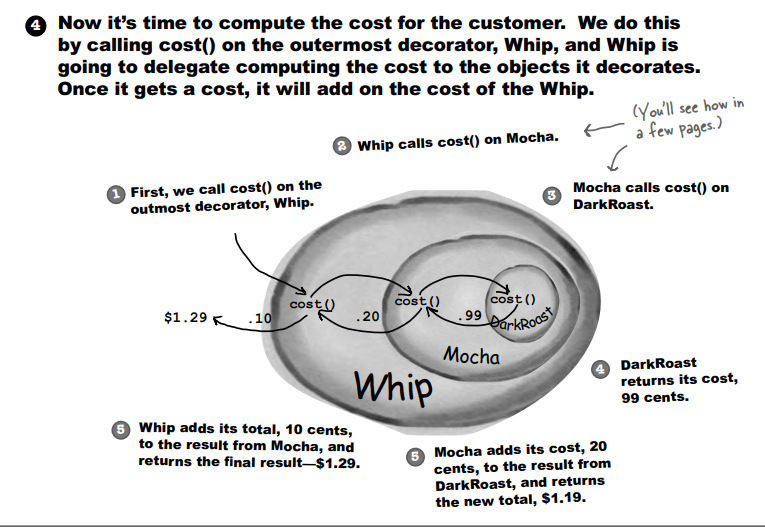
到目前我知道了这些:
动态的对某个对象进行扩展(附加额外的职责), 装饰器是除了继承之外的另外一种为对象扩展功能的方法.
下面看看该模式的类图:
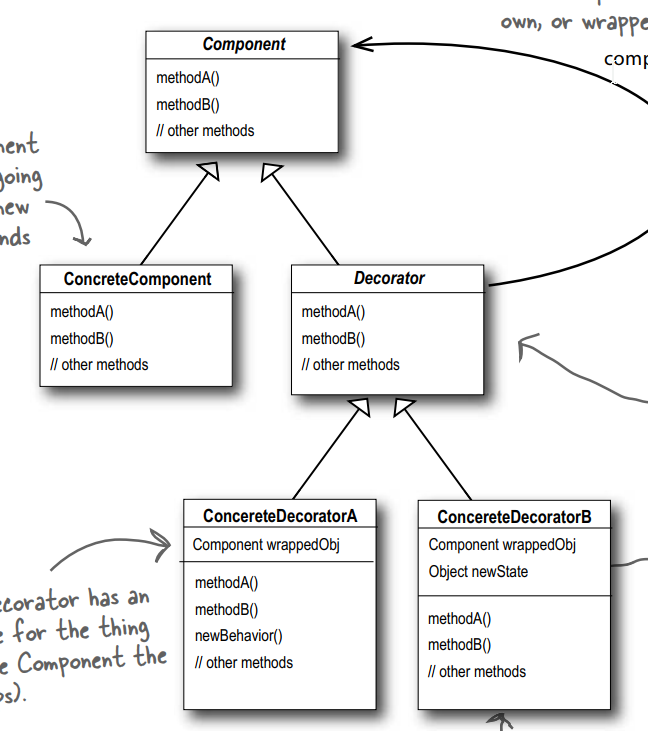
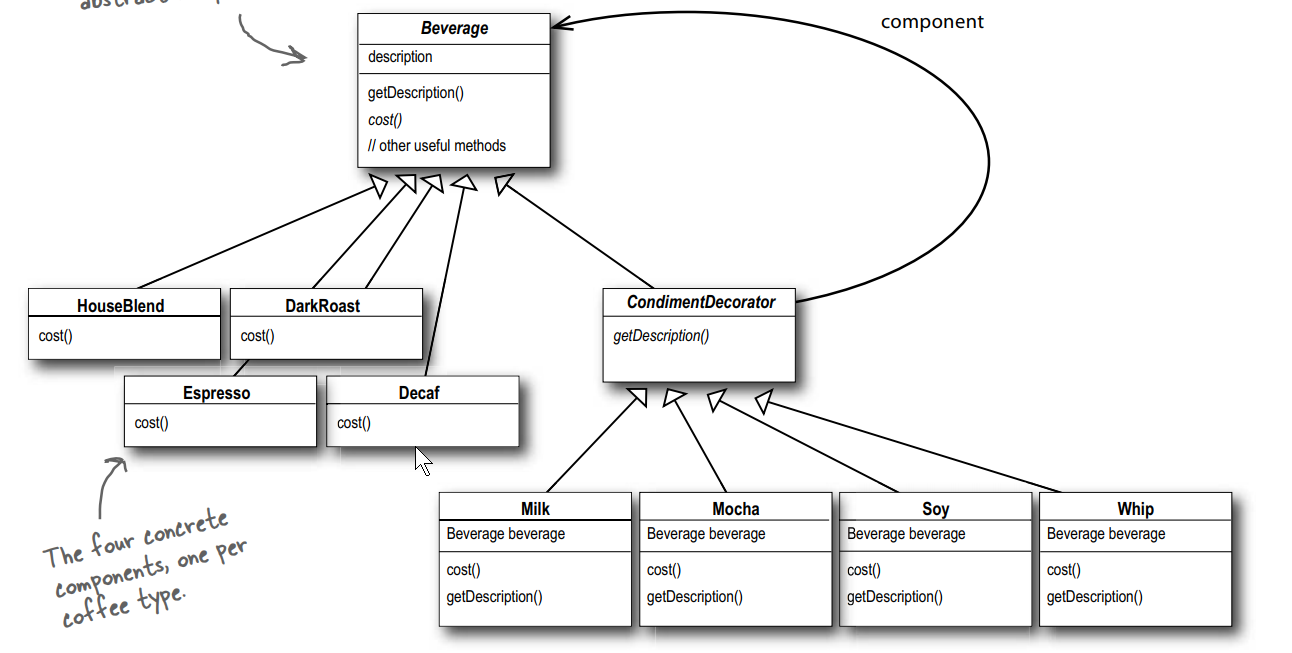
这个就很好理解了, 父类都是Beverage(饮料), 左边是四种具体实现的咖啡, 右边上面是装饰器的父类, 下面是具体的装饰器(调味料).
这里需要注意的是, 装饰器和咖啡都继承于同一个父类只是因为需要它们的类型匹配而已, 并不是要继承行为.
Beverage:
namespace DecoratorPattern.Core { public abstract class Beverage { public virtual string Description { get; protected set; } = "Unknown Beverage"; public abstract double Cost(); } }
CondimentDecorator:
namespace DecoratorPattern.Core { public abstract class CondimentDecorator : Beverage { public abstract override string Description { get; } } }
Espresso 浓咖啡:
using DecoratorPattern.Core; namespace DecoratorPattern.Coffee { public class Espresso : Beverage { public Espresso() { Description = "Espresso"; } public override double Cost() { return 1.99; } } }
using DecoratorPattern.Core; namespace DecoratorPattern.Coffee { public class HouseBlend : Beverage { public HouseBlend() { Description = "HouseBlend"; } public override double Cost() { return .89; } } }
Mocha:
using DecoratorPattern.Core; namespace DecoratorPattern.Condiments { public class Mocha : CondimentDecorator { private readonly Beverage beverage; public Mocha(Beverage beverage) => this.beverage = beverage; public override string Description => $"{beverage.Description}, Mocha"; public override double Cost() { return .20 + beverage.Cost(); } } }
Whip:
using DecoratorPattern.Core; namespace DecoratorPattern.Condiments { public class Whip : CondimentDecorator { private readonly Beverage beverage; public Whip(Beverage beverage) => this.beverage = beverage; public override string Description => $"{beverage.Description}, Whip"; public override double Cost() { return .15 + beverage.Cost(); } } }
Program:
using System; using DecoratorPattern.Coffee; using DecoratorPattern.Condiments; using DecoratorPattern.Core; namespace DecoratorPattern { class Program { static void Main(string[] args) { var beverage = new Espresso(); Console.WriteLine($"{beverage.Description} $ {beverage.Cost()}"); Beverage beverage2 = new HouseBlend(); beverage2 = new Mocha(beverage2); beverage2 = new Mocha(beverage2); beverage2 = new Whip(beverage2); Console.WriteLine($"{beverage2.Description} $ {beverage2.Cost()}"); } } }
运行结果:

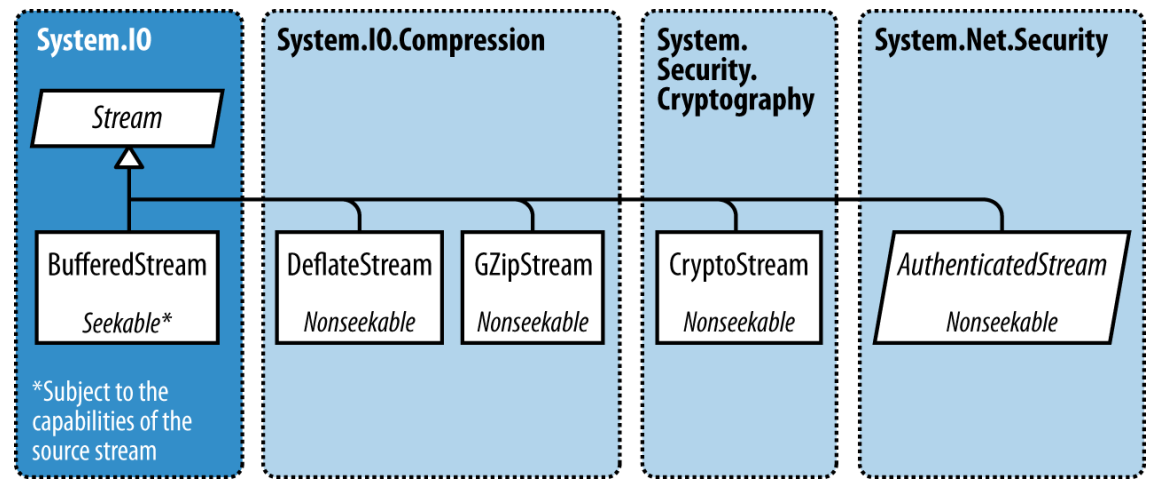
首先需要知道, System.IO命名空间是低级I/O功能的大本营.
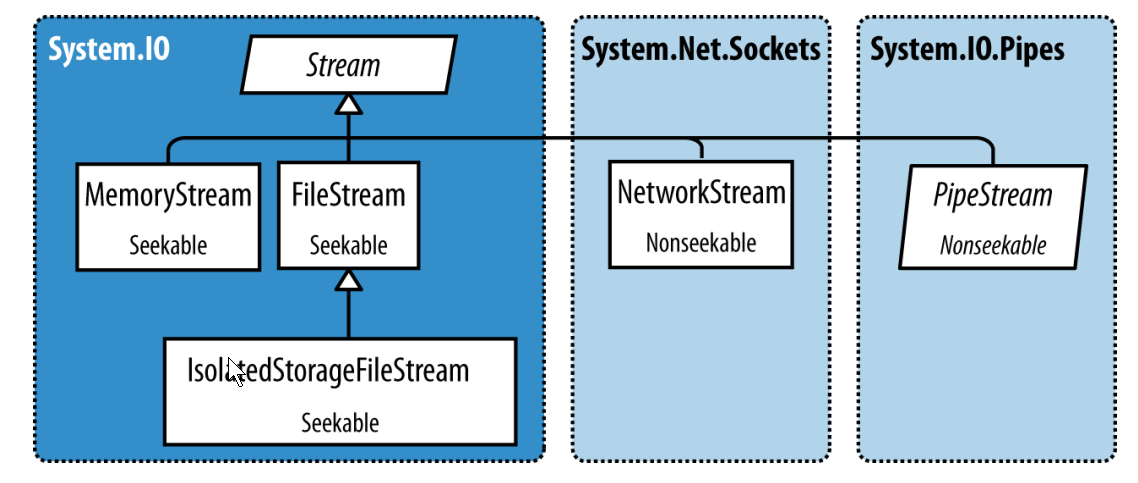
.NET Core里面的Stream主要是三个概念: 存储(backing stores 我不知道怎么翻译比较好), 装饰器, 适配器.
backing stores是让输入和输出发挥作用的端点, 例如文件或者网络连接. 就是下面任意一点或两点:
程序员可以通过Stream类来发挥backing store的作用. Stream类有一套方法, 可以进行读取, 写入, 定位等操作. 个数组不同的是, 数组是把所有的数据都一同放在了内存里, 而stream则是顺序的/连续的处理数据, 要么是一次处理一个字节, 要么是一次处理特定大小(不能太大, 可管理的范围内)的数据.
于是, stream可以用比较小的固定大小的内存来处理无论多大的backing store.
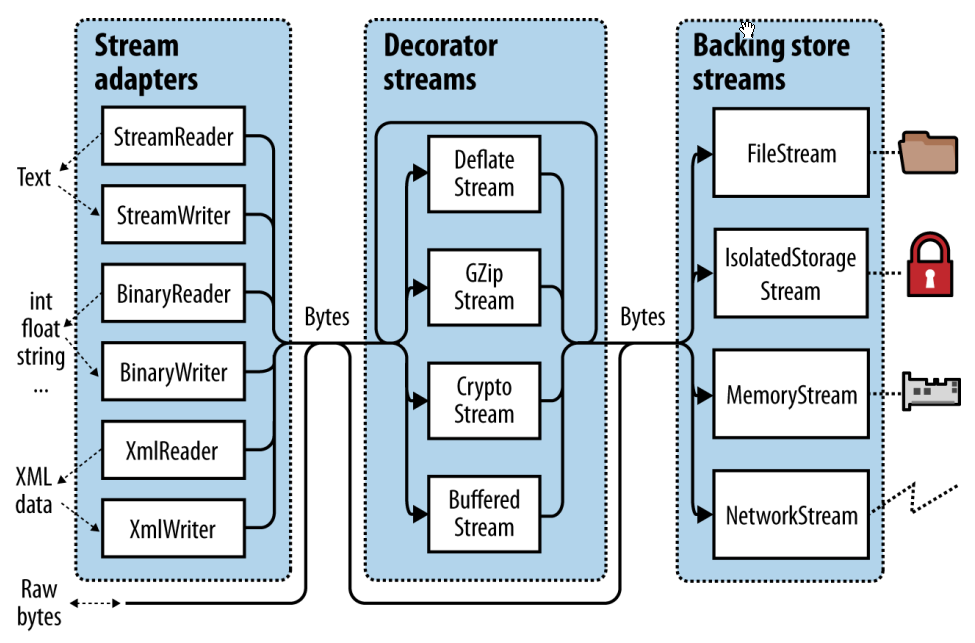
中间的那部分就是装饰器Stream. 它符合装饰模式.
从图中可以看到, Stream又分为两部分:
装饰器Stream有如下结构性的优点(参考装饰模式):
backing store和装饰器stream都是按字节进行处理的. 尽管这很灵活和高效, 但是程序一般还是采用更高级别的处理方式例如文字或者xml.
适配器通过使用特殊化的方法把类里面的stream进行包装成特殊的格式. 这就弥合了上述的间隔.
例如 text reader有一个ReadLine方法, XML writer又WriteAttributes方法.
注意: 适配器包装了stream, 这点和装饰器一样, 但是不一样的是, 适配器本身并不是stream, 它一般会把所有针对字节的方法都隐藏起来. 所以本文就不介绍适配器了.
总结一下:
backing store stream 提供原始数据, 装饰器stream提供透明的转换(例如加密); 适配器提供方法来处理高级别的类型例如字符串和xml.
想要连成串的话, 秩序把对象传递到另一个对象的构造函数里.
Stream抽象类是所有Stream的基类.
它的方法和属性主要分三类基本操作: 读, 写, 寻址(Seek); 和管理操作: 关闭(close), 冲(flush)和设定超时:
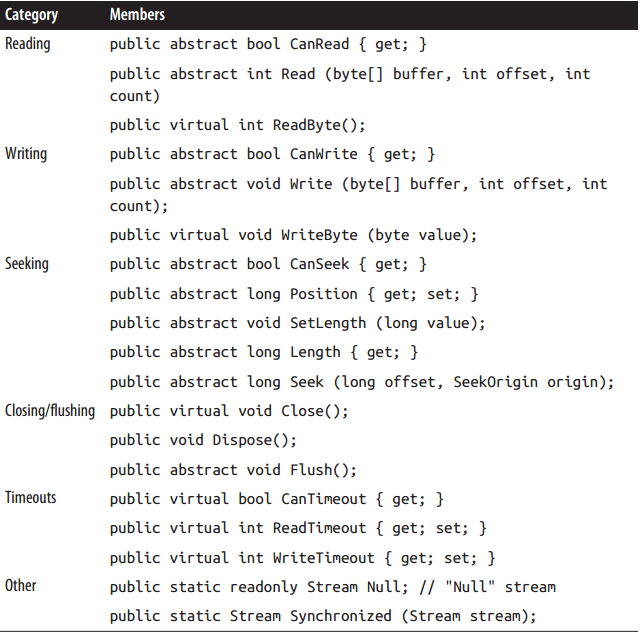
这些方法都有异步的版本, 加async, 返回Task即可.
一个例子:
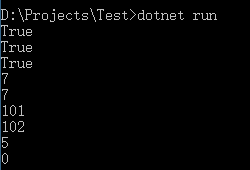
using System; using System.IO; namespace Test { class Program { static void Main(string[] args) { // 在当前目录创建按一个 test.txt 文件 using (Stream s = new FileStream("test.txt", FileMode.Create)) { Console.WriteLine(s.CanRead); // True Console.WriteLine(s.CanWrite); // True Console.WriteLine(s.CanSeek); // True s.WriteByte(101); s.WriteByte(102); byte[] block = { 1, 2, 3, 4, 5 }; s.Write(block, 0, block.Length); // 写 5 字节 Console.WriteLine(s.Length); // 7 Console.WriteLine(s.Position); // 7 s.Position = 0; // 回到开头位置 Console.WriteLine(s.ReadByte()); // 101 Console.WriteLine(s.ReadByte()); // 102 // 从block数组开始的地方开始read: Console.WriteLine(s.Read(block, 0, block.Length)); // 5 // 假设最后一次read返回 5, 那就是在文件结尾, 所以read会返回0: Console.WriteLine(s.Read(block, 0, block.Length)); // 0 } } } }
运行结果:
异步例子:
using System; using System.IO; using System.Threading.Tasks; namespace Test { class Program { static void Main(string[] args) { Task.Run(AsyncDemo).GetAwaiter().GetResult(); } async static Task AsyncDemo() { using (Stream s = new FileStream("test.txt", FileMode.Create)) { byte[] block = { 1, 2, 3, 4, 5 }; await s.WriteAsync(block, 0, block.Length); s.Position = 0; Console.WriteLine(await s.ReadAsync(block, 0, block.Length)); } } } }

异步版本比较适合慢的stream, 例如网络的stream.
CanRead和CanWrite属性可以判断Stream是否可以读写.
Read方法把stream的一块数据写入到数组, 返回接受到的字节数, 它总是小于等于count这个参数. 如果它小于count, 就说明要么是已经读取到stream的结尾了, 要么stream给的数据块太小了(网络stream经常这样).
一个读取1000字节stream的例子:
// 假设s是某个stream byte[] data = new byte[1000]; // bytesRead 的结束位置肯定是1000, 除非stream的长度不足1000 int bytesRead = 0; int chunkSize = 1; while (bytesRead < data.Length && chunkSize > 0) bytesRead += chunkSize = s.Read(data, bytesRead, data.Length - bytesRead);
ReadByte方法更简单一些, 一次就读一个字节, 如果返回-1表示读取到stream的结尾了. 返回类型是int.
Write和WriteByte就是相应的写入方法了. 如果无法写入某个字节, 那就会抛出异常.
上面方法签名里的offset参数, 表示的是缓冲数组开始读取或写入的位置, 而不是指stream里面的位置.
CanSeek为true的话, Stream就可以被寻址. 可以查询和修改可寻址的stream(例如文件stream)的长度, 也可以随时修改读取和写入的位置.
Position属性就是所需要的, 它是相对于stream开始位置的.
Seek方法就允许你移动到当前位置或者stream的尾部.
注意改变FileStream的Position会花去几微秒. 如果是在大规模循环里面做这个操作的话, 建议使用MemoryMappedFile类.
对于不可寻址的Stream(例如加密Stream), 想知道它的长度只能是把它读完. 而且你要是想读取前一部分的话必须关闭stream, 然后再开始一个全新的stream才可以.
Stream用完之后必须被处理掉(dispose)来释放底层资源例如文件和socket处理. 通常使用using来实现.
关闭装饰器stream的时候会同时关闭装饰器和它的backing store stream.
针对一连串的装饰器装饰的stream, 关闭最外层的装饰器就会关闭所有.
有些stream从backing store读取/写入的时候有一个缓存机制, 这就减少了实际到backing store的往返次数以达到提高性能的目的(例如FileStream).
这就意味着你写入数据到stream的时候可能不会立即写入到backing store; 它会有延迟, 直到缓冲被填满.
Flush方法会强制内部缓冲的数据被立即的写入. Flush会在stream关闭的时候自动被调用. 所以你不需要这样写: s.Flush(); s.Close();
如果CanTimeout属性为true的话, 那么该stream就可以设定读或写的超时.
网络stream支持超时, 而文件和内存stream则不支持.
支持超时的stream, 通过ReadTimeout和WriteTimeout属性可以设定超时, 单位毫秒. 0表示无超时.
Read和Write方法通过抛出异常的方式来表示超时已经发生了.
stream并不是线程安全的, 也就是说两个线程同时读或写一个stream的时候就会报错.
Stream通过Synchronized方法来解决这个问题. 该方法接受stream为参数, 返回一个线程安全的包装结果.
这个包装结果在每次读, 写, 寻址的时候会获得一个独立锁/排他锁, 所以同一时刻只有一个线程可以执行操作.
实际上, 这允许多个线程同时为同一个数据追加数据, 而其他类型的操作(例如同读)则需要额外的锁来保证每个线程可以访问到stream相应的部分.
文件流
构建一个FileStream:
FileStream fs1 = File.OpenRead("readme.bin"); // Read-only FileStream fs2 = File.OpenWrite(@"c:\temp\writeme.tmp"); // Write-only FileStream fs3 = File.Create(@"c:\temp\writeme.tmp"); // Read/write
OpenWrite和Create对于已经存在的文件来说, 它的行为是不同的.
Create会把现有文件的内容清理掉, 写入的时候从头开写.
OpenWrite则是完整的保存着现有的内容, 而stream的位置定位在0. 如果写入的内容比原来的内容少, 那么OpenWrite打开并写完之后的内容是原内容和新写入内容的混合体.
直接构建FileStream:
var fs = new FileStream ("readwrite.tmp", FileMode.Open); // Read/write
其构造函数里面还可以传入其他参数, 具体请看文档.
File类的快捷方法:
下面这些静态方法会一次性把整个文件读进内存:
下面的方法直接写入整个文件:
还有一个静态方法叫File.ReadLines: 它有点想ReadAllLines, 但是它返回的是一个懒加载的IEnumerable<string>. 这个实际上效率更高一些, 因为不必一次性把整个文件都加载到内存里. LINQ非常适合处理这个结果. 例如:
int longLines = File.ReadLines ("filePath").Count (l => l.Length > 80);
指定的文件名:
可以是绝对路径也可以是相对路径.
可已修改静态属性Environment.CurrentDirectory的值来改变当前的路径. (注意: 默认的当前路径不一定是exe所在的目录)
AppDomain.CurrentDomain.BaseDirectory会返回应用的基目录, 它通常是包含exe的目录.
指定相对于这个目录的地址最好使用Path.Combine方法:
string baseFolder = AppDomain.CurrentDomain.BaseDirectory; string logoPath = Path.Combine(baseFolder, "logo.jpg"); Console.WriteLine(File.Exists(logoPath));
通过网络对文件读写要使用UNC路径:
例如: \\JoesPC\PicShare \pic.jpg 或者 \\10.1.1.2\PicShare\pic.jpg.
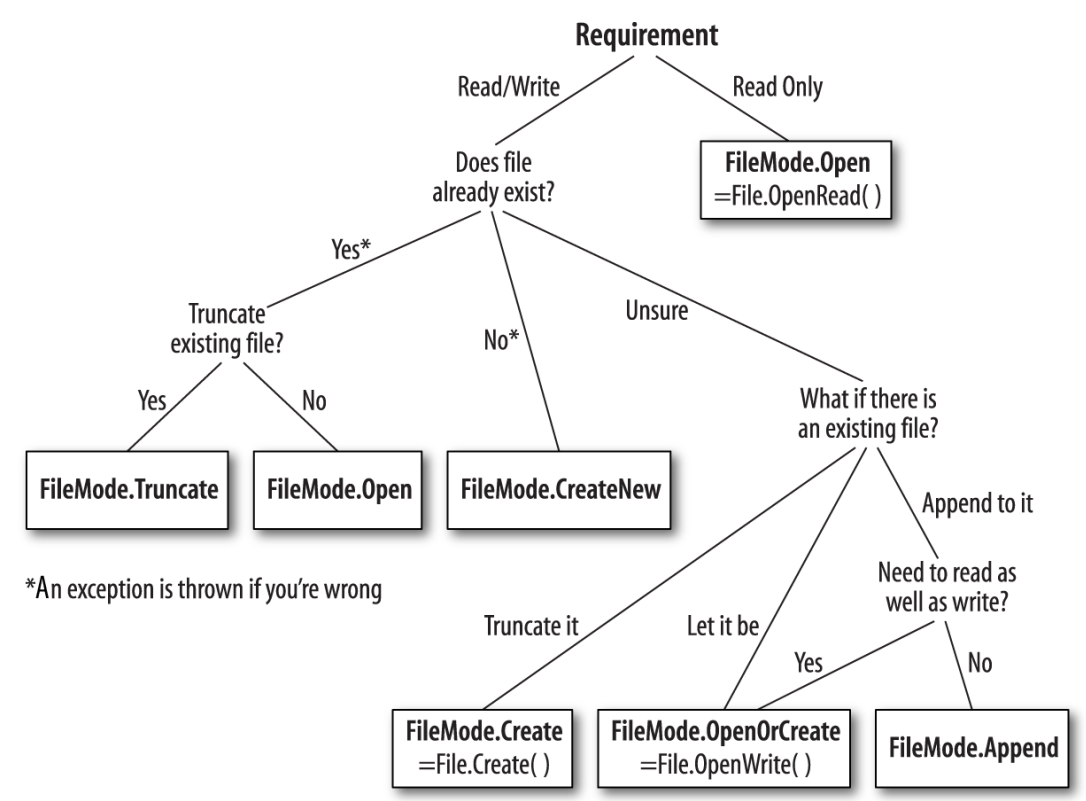
FileMode:
所有的FileStream的构造器都会接收一个文件名和一个FileMode枚举作为参数. 如果选择FileMode请看下图:
其他特性还是需要看文档.
MemoryStream在随机访问不可寻址的stream时就有用了.
如果你知道源stream的大小可以接受, 你就可以直接把它复制到MemoryStream里:
var ms = new MemoryStream(); sourceStream.CopyTo(ms);
可以通过ToArray方法把MemoryStream转化成数组.
GetBuffer方法也是同样的功能, 但是因为它是直接把底层的存储数组的引用直接返回了, 所以会更有效率. 不过不幸的是, 这个数组通常比stream的真实长度要长.
注意: Close和Flush 一个MemoryStream是可选的. 如果关闭了MemoryStream, 你就再也不能对它读写了, 但是仍然可以调用ToArray方法来获取其底层的数据.
Flush则对MemoryStream毫无用处.
PipeStream通过Windows Pipe 协议, 允许一个进程(process)和另一个进程通信.
分两种:
pipe很适合一个电脑上的进程间交互(IPC), 它并不依赖于网络传输, 这也意味着没有网络开销, 也不在乎防火墙.
注意: pipe是基于Stream的, 一个进程等待接受一串字符的同时另一个进程发送它们.
PipeStream是抽象类.
具体的实现类有4个:
匿名pipe:
命名Pipe:
命名Pipe
命名pipe的双方通过同名的pipe进行通信. 协议规定了两个角色: 服务器和客户端. 按照下述方式进行通信:
然后双方就可以读写stream来进行通信了.
例子:
using System; using System.IO; using System.IO.Pipes; using System.Threading.Tasks; namespace Test { class Program { static void Main(string[] args) { Console.WriteLine(DateTime.Now.ToString()); using (var s = new NamedPipeServerStream("pipedream")) { s.WaitForConnection(); s.WriteByte(100); // Send the value 100. Console.WriteLine(s.ReadByte()); } Console.WriteLine(DateTime.Now.ToString()); } } }
using System; using System.IO.Pipes; namespace Test2 { class Program { static void Main(string[] args) { Console.WriteLine(DateTime.Now.ToString()); using (var s = new NamedPipeClientStream("pipedream")) { s.Connect(); Console.WriteLine(s.ReadByte()); s.WriteByte(200); // Send the value 200 back. } Console.WriteLine(DateTime.Now.ToString()); } } }

命名的PipeStream默认情况下是双向的, 所以任意一方都可以进行读写操作, 这也意味着服务器和客户端必须达成某种协议来协调它们的操作, 避免同时进行发送和接收.
还需要协定好每次传输的长度.
在处理长度大于一字节的信息的时候, pipe提供了一个信息传输的模式, 如果这个启用了, 一方在调用read的时候可以通过检查IsMessageComplete属性来知道消息什么时候结束.
例子:
static byte[] ReadMessage(PipeStream s) { MemoryStream ms = new MemoryStream(); byte[] buffer = new byte[0x1000]; // Read in 4 KB blocks do { ms.Write(buffer, 0, s.Read(buffer, 0, buffer.Length)); } while (!s.IsMessageComplete); return ms.ToArray(); }
注意: 针对PipeStream不可以通过Read返回值是0的方式来它是否已经完成读取消息了. 这是因为它和其他的Stream不同, pipe stream和network stream没有确定的终点. 在两个信息传送动作之间, 它们就干等着.
这样启用信息传输模式, 服务器端 :
using (var s = new NamedPipeServerStream("pipedream", PipeDirection.InOut, 1, PipeTransmissionMode.Message)) { s.WaitForConnection(); byte[] msg = Encoding.UTF8.GetBytes("Hello"); s.Write(msg, 0, msg.Length); Console.WriteLine(Encoding.UTF8.GetString(ReadMessage(s))); }
客户端:
using (var s = new NamedPipeClientStream("pipedream")) { s.Connect(); s.ReadMode = PipeTransmissionMode.Message; Console.WriteLine(Encoding.UTF8.GetString(ReadMessage(s))); byte[] msg = Encoding.UTF8.GetBytes("Hello right back!"); s.Write(msg, 0, msg.Length); }
匿名pipe:
匿名pipe提供父子进程间的单向通信. 流程如下:
因为匿名pipe是单向的, 所以服务器必须创建两份pipe来进行双向通信
例子:
server:
using System; using System.Diagnostics; using System.IO; using System.IO.Pipes; using System.Text; using System.Threading.Tasks; namespace Test { class Program { static void Main(string[] args) { string clientExe = @"D:\Projects\Test2\bin\Debug\netcoreapp2.0\win10-x64\publish\Test2.exe"; HandleInheritability inherit = HandleInheritability.Inheritable; using (var tx = new AnonymousPipeServerStream(PipeDirection.Out, inherit)) using (var rx = new AnonymousPipeServerStream(PipeDirection.In, inherit)) { string txID = tx.GetClientHandleAsString(); string rxID = rx.GetClientHandleAsString(); var startInfo = new ProcessStartInfo(clientExe, txID + " " + rxID); startInfo.UseShellExecute = false; // Required for child process Process p = Process.Start(startInfo); tx.DisposeLocalCopyOfClientHandle(); // Release unmanaged rx.DisposeLocalCopyOfClientHandle(); // handle resources. tx.WriteByte(100); Console.WriteLine("Server received: " + rx.ReadByte()); p.WaitForExit(); } } } }
client:
using System; using System.IO.Pipes; namespace Test2 { class Program { static void Main(string[] args) { string rxID = args[0]; // Note we're reversing the string txID = args[1]; // receive and transmit roles. using (var rx = new AnonymousPipeClientStream(PipeDirection.In, rxID)) using (var tx = new AnonymousPipeClientStream(PipeDirection.Out, txID)) { Console.WriteLine("Client received: " + rx.ReadByte()); tx.WriteByte(200); } } } }
最好发布一下client成为独立运行的exe:
dotnet publish --self-contained --runtime win10-x64
运行结果:
匿名pipe不支持消息模式, 所以你必须自己来为传输的长度制定协议. 有一种做法是: 在每次传输的前4个字节里存放一个整数表示消息的长度, 可以使用BitConverter类来对整型和长度为4的字节数组进行转换.
BufferedStream对另一个stream进行装饰或者说包装, 让它拥有缓冲的能力.它也是众多装饰stream类型中的一个.
缓冲肯定会通过减少往返backing store的次数来提升性能.
下面这个例子是把一个FileStream装饰成20k的缓冲stream:
// Write 100K to a file: File.WriteAllBytes("myFile.bin", new byte[100000]); using (FileStream fs = File.OpenRead("myFile.bin")) using (BufferedStream bs = new BufferedStream(fs, 20000)) //20K buffer { bs.ReadByte(); Console.WriteLine(fs.Position); // 20000 } }
通过预读缓冲, 底层的stream会在读取1字节后, 直接预读了20000字节, 这样我们在另外调用ReadByte 19999次之后, 才会再次访问到FileStream.
这个例子是把BufferedStream和FileStream耦合到一起, 实际上这个例子里面的缓冲作用有限, 因为FileStream有一个内置的缓冲. 这个例子也只能扩大一下缓冲而已.
关闭BufferedStream就会关闭底层的backing store stream..
先写到这里, 略微有点跑题了, 但是.NET Core的Stream这部分没写完, 另开一篇文章再写吧.
下面是我的关于ASP.NET Core Web API相关技术的公众号--草根专栏:

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273