Piotr Migdał 在 MacBook Max M5 128GB 上跑了一整天 Qwen 3.6 27B,结论是:这是他第一次觉得本地模型能当通用智能用,不需要将就。他把体验写成了一篇博客,标题直白——Qwen 3.6 27B is awesome。

先说配置。他用的是 unsloth 的 8-bit GGUF 量化版,llama.cpp 跑服务,开了多 token 预测(MTP)和 flash attention,64K 上下文,速度 32 tok/s。RTX 5090 上有人用 Q6_K 跑到了 50 tok/s、12.3 万上下文。两个 Qwen 3.6 变体——27B 密集版和 35B A3B MoE 版——都能塞进 48GB 的苹果统一内存里。

智力水平怎么衡量?他引了 Artificial Analysis 的评分。Qwen 3.6 27B 拿了 37 分,大致对应 2025 年中的 GPT-5 或 Claude Sonnet 4.5。作为对比,之前本地编码模型的默认选项 Gemma 4 31B 只有 29 分——那是 2024 年底的 Claude 3.5 Sonnet 水平。一年之内,本地模型从两年前前沿跨到了一年前的次前沿。
35B A3B MoE 版更快——同样 8-bit 下用 llama.cpp + MTP 能到 105 tok/s——但评分只有 32 分。Migdał 的态度是不纠结:"宁可生成三分之一的代码,但是质量更高。"他的实际测试佐证了这个判断:让模型写一首关于 Zouk 舞和量子物理的八行诗,推理过程"在术语和押韵上都说得通"。用 pnpm 写六边形扫雷游戏,27B 版一次过,35B 版忽略掉了包依赖指令。从一句话 prompt 生成蜡烛店落地页,出来的效果不错。
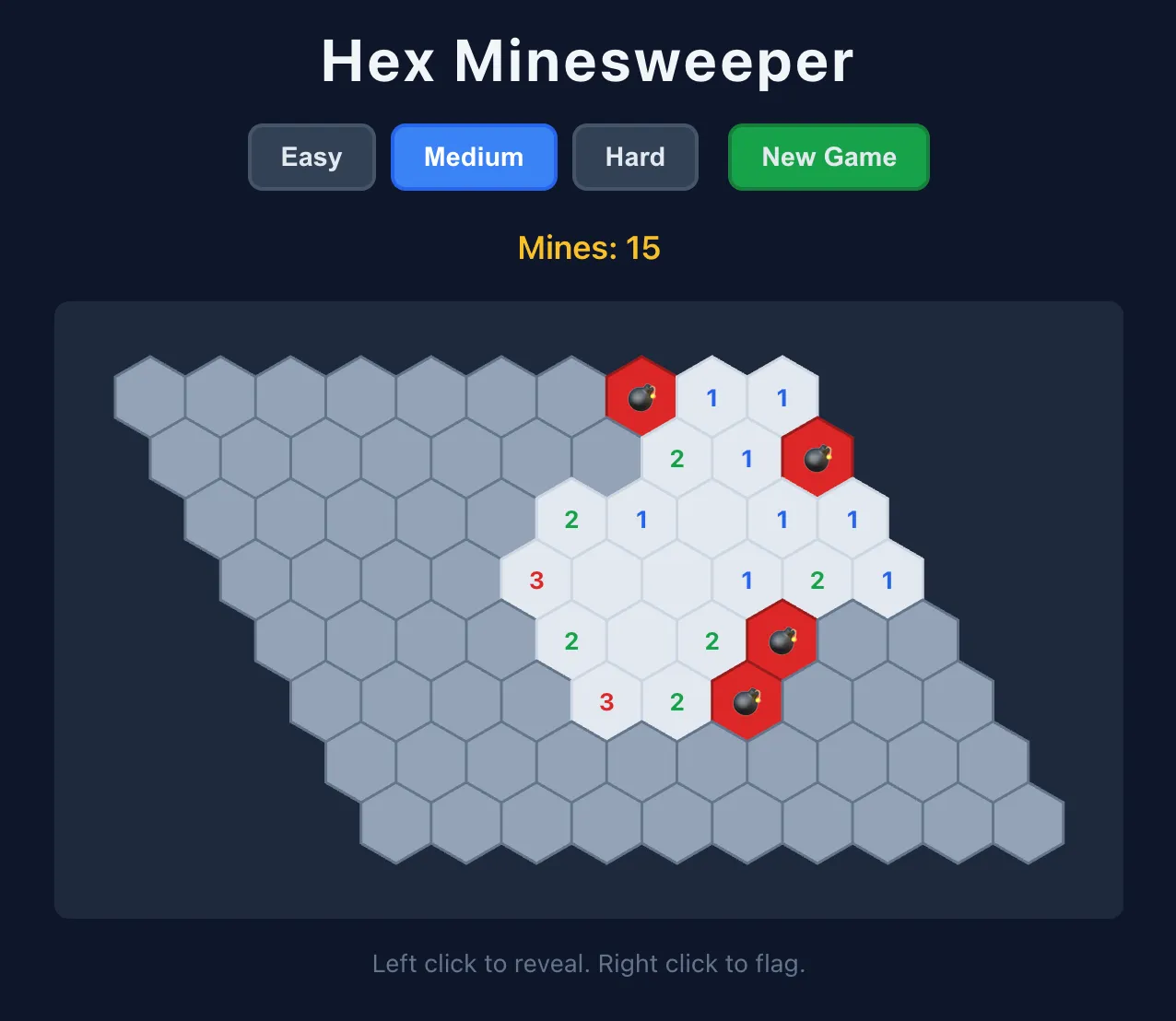
技术栈上他选的是 llama.cpp 直跑而非 Ollama——原话是“出于道德原因不推荐 Ollama”。服务端一行命令:llama-server -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0 --spec-type draft-mtp -ngl 999 -fa on -c 65536,OpenCode 挂上去直接写代码。
Migdał 的文末有一句话,是他整篇评测最值得琢磨的判断:"花了 100 美元订阅,换来的是价值数千美元的 token,这就是 API 定价里的大规模补贴。但本地模型不会被收回。"他指的是 Claude Fable 5 被下线的事,本地模型跑在自己的硬盘上,没人能拿走。
这条 27B 密集模型的意义确实值得想一下。当跑在消费级笔记本上的开源模型,智力水平对等到了一年前的付费 API,再往下算的不只是钱——是你在谁的计算机上运行代码。
参考来源:
