DBOS 日前发表了一篇引起不少讨论的博文,核心观点是"Postgres 是你持久化执行所需的全部"——既然你已经信任你的数据库,就不需要额外的编排层。这个逻辑得到了不少共鸣,但 Obelisk 团队认为,这个思路还可以再往前走一步:对于一大类持久化系统,SQLite 就足够了。
这篇文章来自 Obelisk 官方博客。Obelisk 是一个开源的工作流引擎,而他们的答案指向了一个截然不同的架构思路。
持久化的本质:状态要持久,计算层可以丢弃
持久化执行常常被认为必然需要持久化的基础设施。但实际上,答案并没有这么绝对——真正需要持久化的,是工作流的状态;计算层则可以保持廉价且可丢弃。
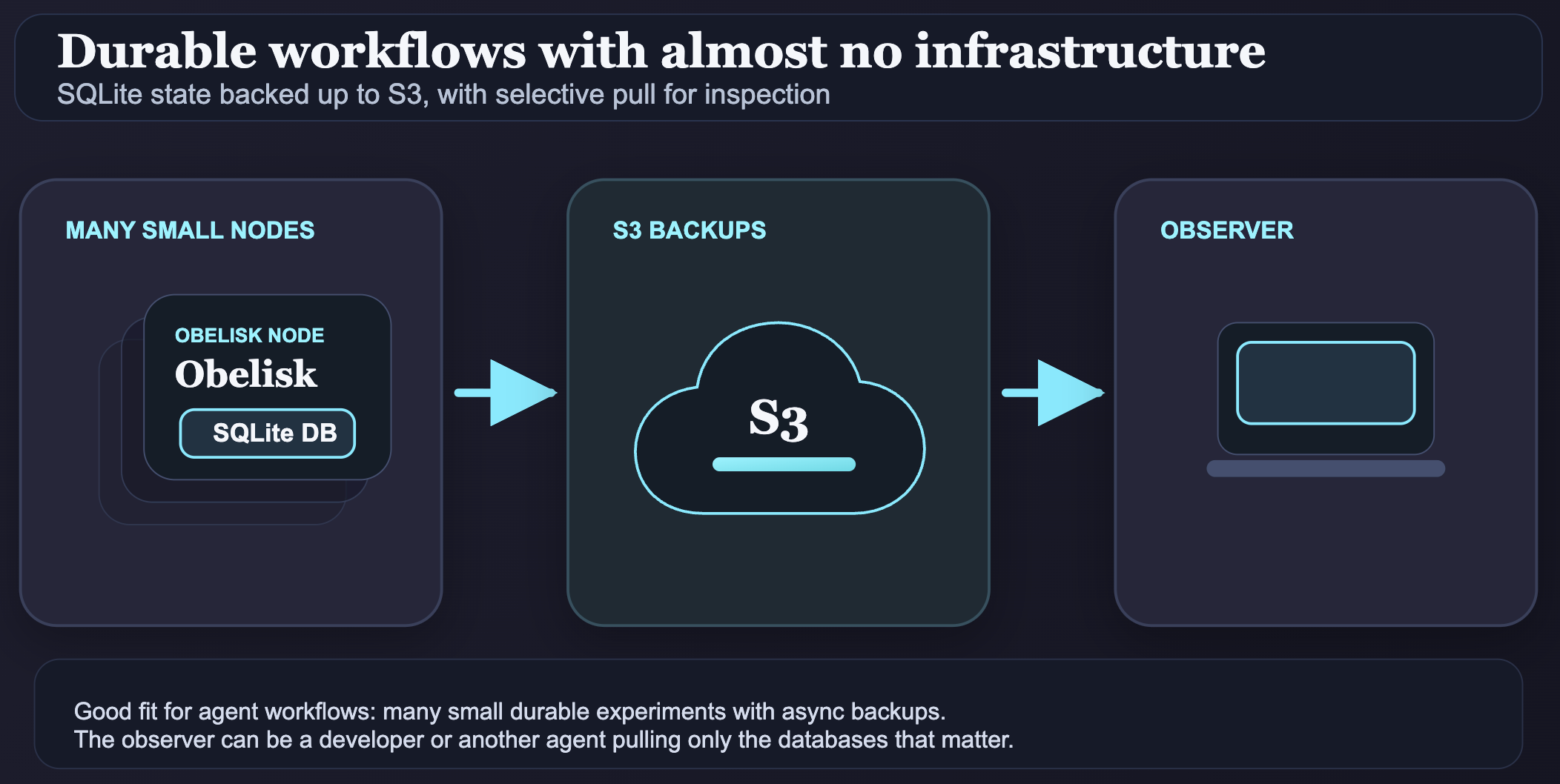
这恰恰是 Obelisk 的核心设计思路:工作流进度存储在执行日志中,工作流从持久化的历史记录重放,activity 可以重试。真正重要的,是保证工作流状态始终存在且易于检查。至于计算发生在哪里,其实没那么关键—— worker 可以随时重建、重启、替换。
SQLite 为什么是合适的选择
SQLite 的吸引力在于:它提供了事务性的持久化状态,却不需要引入一个独立的数据库服务。没有网络开销,没有额外的控制平面,也不需要为"保护工作流进度"这件事单独开辟一块运维复杂度。对于很多系统来说,一个本地数据库文件恰好是正确规模的基础设施。
这个逻辑在 AI 场景下尤为成立。AI 系统往往是突发性的、实验性的,当每个 agent 或租户拥有独立的小型自包含状态单元时,整个系统更容易推理和维护。一组部署在微型虚拟机或容器中的小型服务器,每台配备自己的 SQLite 数据库和对象存储备份,往往比一个大型共享系统更合适——更简单、更便宜、故障隔离更好。
Litestream 让数据可迁移
一个自然而然的问题是:当实验积累起来的 SQLite 文件越来越多时,该怎么处理?
这正是 Litestream 的用武之地。Litestream 可以将 SQLite 变更异步流式传输到 S3 兼容的对象存储。这提供了一种简洁的方式,既能将工作状态保留在运行时附近,又能在需要时将数据库复制出来用于备份、迁移和检查。
当然,这里有一个重要的限制:Litestream 的复制是异步的。如果 SQLite 卷在本地写入被复制到 S3 之前消失,恢复时可能会丢失最新的本地写入。这对于很多 AI 和实验工作流来说是可以接受的,但它与高可用的共享数据库并非同一回事。
这带来了一种实用的运维模型:运行一个配备 SQLite 数据库的 Obelisk 服务器,用 Litestream 备份,需要时让 observer 拉取感兴趣的数据库。同一份文件既可以用于本地重放、调试,也能用来理解一个 agent 到底做了什么。
Postgres 的适用场景
SQLite 并非所有部署形态的答案。Obelisk 同时也支持 Postgres,当需要更高的可用性、更广泛的共享扩展性,或者需要其他网络数据库才能更好服务的部署属性时,Postgres 是正确的选择。如果异步复制到对象存储不是你所需要的持久化模型,Postgres 同样是更合适的选项。
关键在于:很多工作流系统在其早期阶段并不需要那么复杂的基础设施,不应该用超出实际需求的架构来承载状态。
AI Agents 时代的最务实选择
对于 AI agents 领域,本地 SQLite + Litestream 备份到 S3 配合廉价 workers,构成了一个持久化系统所需基础设施最少的方案。在不需要高可用的场景下,这个组合的实用程度可能超出预期——它不需要运维一个数据库集群,不需要管理连接池,不需要担心网络分区,状态文件本身就可以直接复制到任何地方使用和检查。
很多工作流系统在第一天不需要 Postgres,应该从更简单的东西开始。
参考来源:https://obeli.sk/blog/sqlite-is-all-you-need-for-durable-workflows/
