ByteDance Intelligent Creation Lab 宣布推出了一款原生统一多模态模 型Lance,以 3B 激活参数和多任务协同训练,在单一原生统一框架中支持图像/视频理解、生成与编辑,兼顾资源效率、能力广度与跨任务泛化。目前相关模型权重和代码以开源。
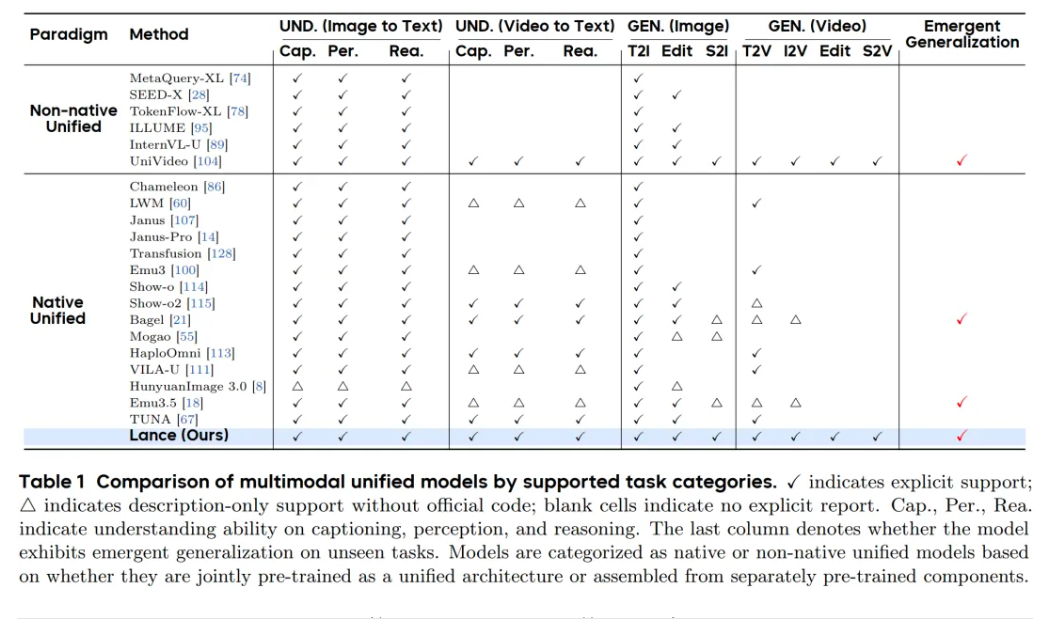
根据介绍,Lance 的核心优势之一,是在 3B 模型规模下提供更完整的多任务支持。它不是将若干模块简单拼接,而是在统一上下文空间中联合建模不同模态与任务,使理解、生成和编辑能力能够相互促进。
Lance 在视频生成中能够准确遵循复杂文本指令,生成具备自然运动、稳定时序一致性、清晰视觉细节和较强语义表达的视频内容。
在视频编辑中能够根据文本指令实现对象替换、背景变化、风格迁移与细粒度属性修改,同时保持主体身份、画面结构和运动过程的时序一致性,并支持多轮一致性编辑。
在视频理解中能够准确识别动态场景中的人物、物体、动作与时序变化,并结合视觉细节、OCR 信息和上下文语义生成细致可靠的描述与问答结果。
图像生成方面,可根据复杂文本指令生成较高质量、视觉自然的图像内容,并在数量关系、属性绑定、空间布局和风格控制等方面展现出较强的组合生成能力。
以及可基于自然语言指令完成图像中的主体增删、局部替换、风格迁移、动作调整和自由形式编辑,并在修改过程中较好地保持主体身份、画面结构和视觉一致性。
Lance 具备较强的图像理解能力,可准确识别图像中的物体、人物、场景、文字信息和空间关系,并结合视觉细节完成内容描述、OCR 理解和问答推理。
Lance 整体架构示意图:
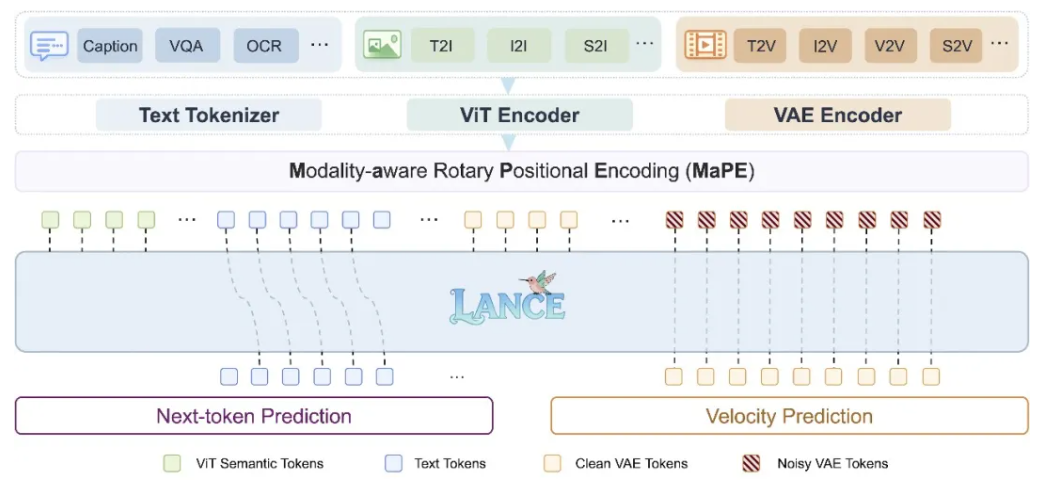
Lance 的核心设计围绕两个原则展开:一方面,通过统一上下文建模,将文本、图像和视频组织为共享的交错多模态序列,使不同任务能够在同一上下文空间中进行信息交互;另一方面,通过解耦能力路径,为理解和生成分别分配专门化的表征与模型容量,避免异质任务在优化目标和视觉表示上相互干扰。
具体来看,Lance 采用 dual-stream mixture-of-experts 架构:理解路径主要处理文本 token 与语义视觉 token,用于图像/视频理解、问答和推理;生成路径主要处理 VAE latent token,用于图像/视频生成与编辑。两条路径共享统一的交错多模态上下文,但在能力建模上保持解耦,从而兼顾跨任务交互与任务专门化。
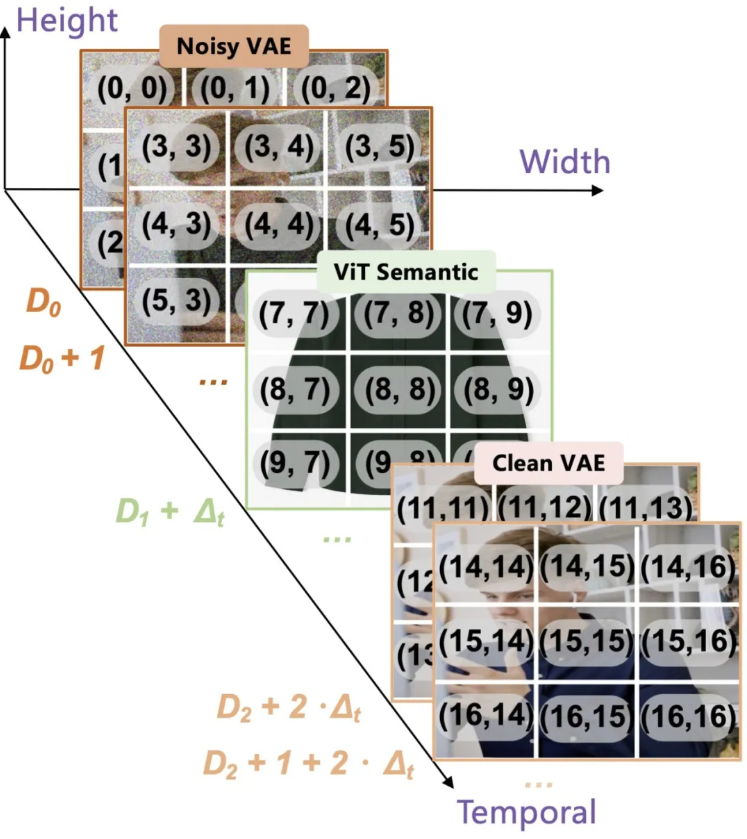
此外,为了更好地协调统一序列中的异构视觉 token,Lance 引入了 Modality-Aware Rotary Positional Encoding(MaPE)。在统一多模态训练中,同一序列中可能同时包含用于理解的语义 ViT token、用于生成条件的 clean VAE token,以及作为生成目标的 noisy VAE token。它们来源不同、功能不同,如果仅使用标准位置编码,容易造成位置空间中的角色混淆。
MaPE 通过在位置编码的时间维度中加入模态/功能组信息,使得模型在不破坏图像的空间结构和视频的时序关系的同时,能够显式区分不同视觉 token 的作用。整体而言,MaPE 有助于缓解多任务联合优化过程中的异构视觉 token 之间的位置干扰,并提升跨任务上下文对齐能力。
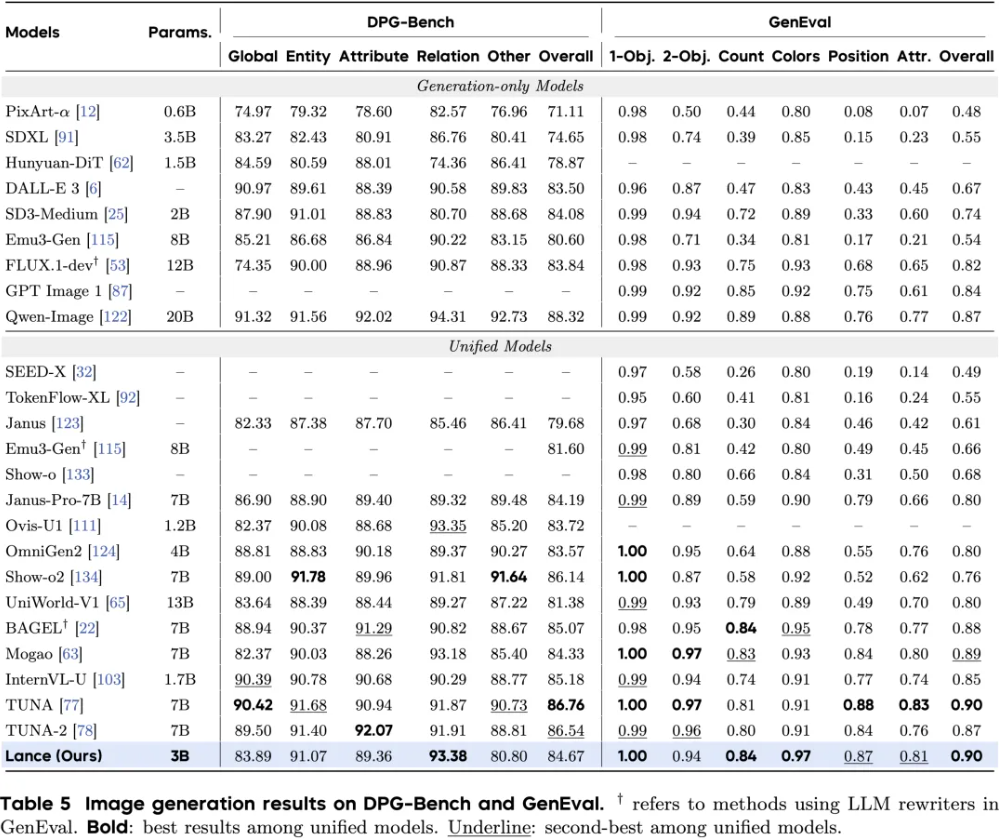
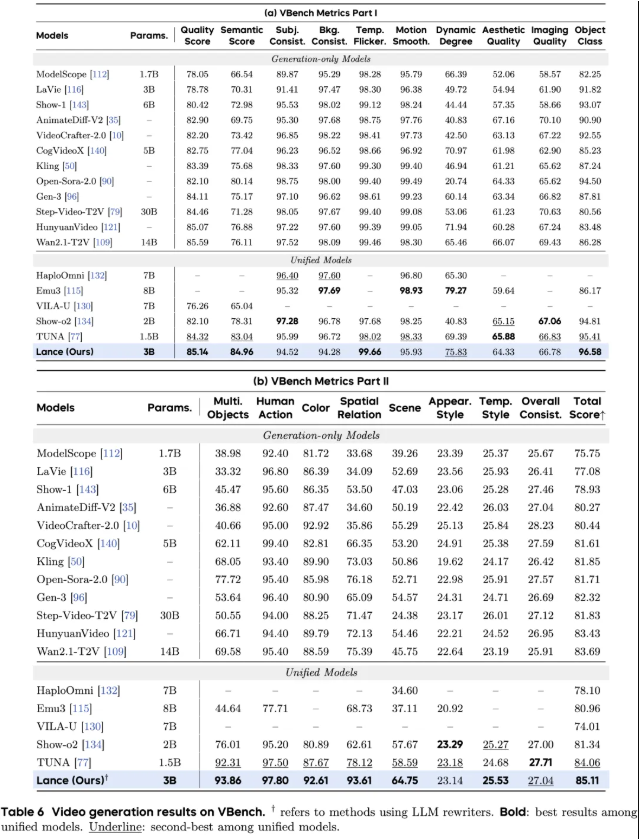
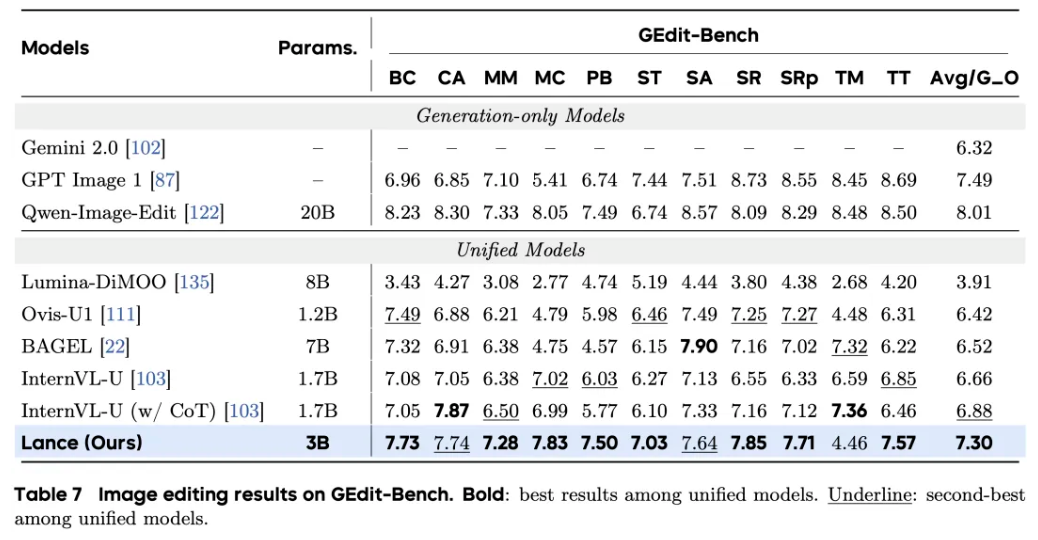
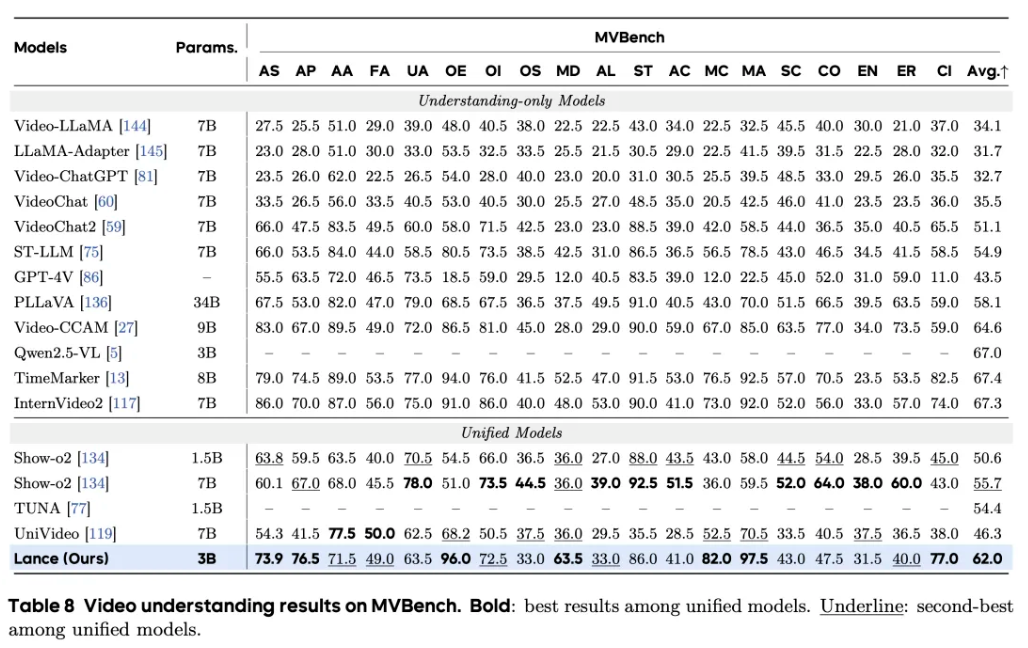
一些评测结果如下: