![数据库模式]()
本文将深入介绍 Apache DolphinScheduler 所采用的数据库模式,此模式主要用于持久化存储工作流定义、执行状态、调度信息以及系统元数据。它具备广泛的兼容性,可支持 MySQL、PostgreSQL 和 H2 等多种数据库,其具体定义存储在 dolphinscheduler - dao/src/main/resources/sql 目录下。
模式架构
DolphinScheduler 的数据库模式分为七个主要功能组:
| 组 |
目的 |
关键表 |
| 工作流管理 |
存储带有版本控制的工作流和任务定义 |
t_ds_workflow_definition、t_ds_task_definition、t_ds_workflow_task_relation |
| 执行状态 |
跟踪运行时实例及其状态 |
t_ds_workflow_instance、t_ds_task_instance、t_ds_command |
| 调度 |
通过 Quartz 管理基于 cron 的调度 |
t_ds_schedules、QRTZ_* 表 |
| 资源管理 |
数据源、文件和 UDF 元数据 |
t_ds_datasource、t_ds_resources、t_ds_udfs |
| 管理 |
用户、租户、项目和权限 |
t_ds_user、t_ds_tenant、t_ds_project |
| 告警 |
告警配置和历史记录 |
t_ds_alert、t_ds_alertgroup |
| 服务注册 |
基于 JDBC 的协调(ZooKeeper 的替代方案) |
t_ds_jdbc_registry_* 表 |
工作流和任务定义模型
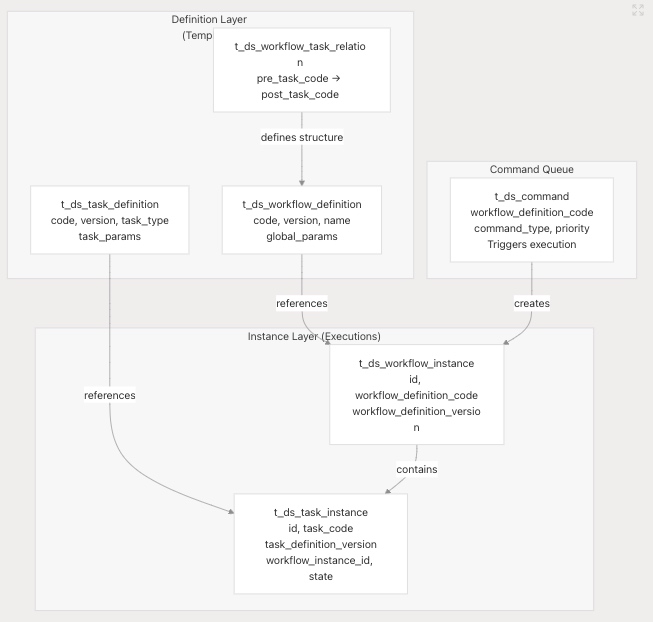
定义与实例分离
DolphinScheduler 严格区分定义(模板)和实例(执行)。这实现了版本控制、并发执行和审计跟踪。
![]()
关键设计原则:
- 基于代码的标识:工作流和任务都使用代码(bigint)作为跨版本的稳定标识符。
- 复合键:定义使用(代码,版本)作为复合自然键。
- 版本不可变性:每个版本都是不可变的;更改会创建新版本。
- 实例引用:实例引用特定版本的定义。
核心表参考
工作流定义表
t_ds_workflow_definition
工作流模板的主表。
| 列 |
类型 |
描述 |
| id |
int |
自动递增主键 |
| code |
bigint |
唯一工作流标识符(跨版本稳定) |
| version |
int |
版本号(默认 1) |
| name |
varchar(255) |
工作流名称 |
| project_code |
bigint |
所属项目 |
| release_state |
tinyint |
0 = 离线,1 = 在线 |
| global_params |
text |
JSON 格式的全局参数 |
| execution_type |
tinyint |
0 = 并行,1 = 串行等待,2 = 串行丢弃,3 = 串行优先级 |
| timeout |
int |
超时时间(分钟) |
| user_id |
int |
创建者用户 ID |
索引:
UNIQUE KEY workflow_unique (name, project_code)UNIQUE KEY uniq_workflow_definition_code (code)KEY idx_project_code (project_code)
t_ds_workflow_definition_log
存储工作流定义所有版本的审计日志。
镜像 t_ds_workflow_definition 的结构,额外列:operator、operate_time,主键:(code, version)。
t_ds_task_definition
可在工作流中重用的任务模板。
| 列 |
类型 |
描述 |
| code |
bigint |
唯一任务标识符 |
| version |
int |
版本号 |
| task_type |
varchar(50) |
Shell、SQL、Python、Spark 等 |
| task_params |
longtext |
JSON 格式的任务配置 |
| worker_group |
varchar(255) |
目标工作线程组 |
| fail_retry_times |
int |
失败重试次数 |
| fail_retry_interval |
int |
重试间隔(分钟) |
| timeout |
int |
任务超时时间(分钟) |
| cpu_quota |
int |
CPU 限制(-1 = 无限制) |
| memory_max |
int |
内存限制(MB,-1 = 无限制) |
t_ds_workflow_task_relation
通过指定任务之间的边来定义 DAG 结构。
| 列 |
类型 |
描述 |
| workflow_definition_code |
bigint |
父工作流 |
| workflow_definition_version |
int |
工作流版本 |
| pre_task_code |
bigint |
前置任务(根节点为 0) |
| post_task_code |
bigint |
后置任务 |
| condition_type |
tinyint |
0 = 无,1 = 判断,2 = 延迟 |
| condition_params |
text |
JSON 格式的条件配置 |
注意:pre_task_code = 0 表示根节点(无前驱任务)。
执行状态表
t_ds_workflow_instance
工作流的运行时执行记录。
| 列 |
类型 |
描述 |
| id |
int |
主键 |
| workflow_definition_code |
bigint |
引用定义 |
| workflow_definition_version |
int |
本次执行锁定的版本 |
| state |
tinyint |
0 = 提交,1 = 运行中,2 = 暂停准备,3 = 已暂停,4 = 停止准备,5 = 已停止,6 = 失败,7 = 成功,8 = 需要容错,9 = 已终止,10 = 等待,11 = 等待依赖 |
| state_history |
text |
状态转换日志 |
| start_time |
datetime |
执行开始时间 |
| end_time |
datetime |
执行结束时间 |
| command_type |
tinyint |
0 = 开始,1 = 从当前开始,2 = 恢复,3 = 恢复暂停,4 = 从失败处开始,5 = 补充,6 = 调度,7 = 重新运行,8 = 暂停,9 = 停止,10 = 恢复等待 |
| host |
varchar(135) |
执行此工作流的主服务器主机 |
| executor_id |
int |
触发执行的用户 |
| tenant_code |
varchar(64) |
用于资源隔离的租户 |
| next_workflow_instance_id |
int |
用于串行执行模式 |
索引:
KEY workflow_instance_index (workflow_definition_code, id)KEY start_time_index (start_time, end_time)
t_ds_task_instance
单个任务的运行时执行记录。
| 列 |
类型 |
描述 |
| id |
int |
主键 |
| task_code |
bigint |
引用任务定义 |
| task_definition_version |
int |
锁定的版本 |
| workflow_instance_id |
int |
父工作流实例 |
| state |
tinyint |
与 workflow_instance 相同的状态值 |
| submit_time |
datetime |
提交到队列的时间 |
| start_time |
datetime |
实际执行开始时间 |
| end_time |
datetime |
执行结束时间 |
| host |
varchar(135) |
执行任务的工作线程主机 |
| execute_path |
varchar(200) |
工作线程上的工作目录 |
| log_path |
text |
日志文件路径 |
| retry_times |
int |
当前重试次数 |
| var_pool |
text |
供下游任务使用的变量 |
索引:KEY idx_task_instance_code_version (task_code, task_definition_version)
命令模式与工作流执行
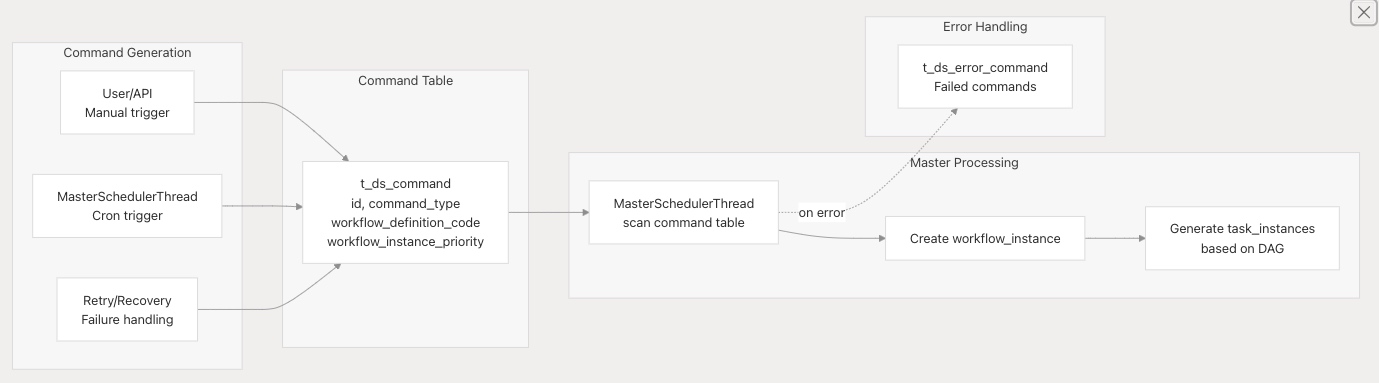
命令队列
t_ds_command 表实现了基于队列的执行模型,其中命令触发工作流实例。 ![]()
t_ds_command 结构
| 列 |
类型 |
描述 |
| command_type |
tinyint |
0 = 开始,1 = 从当前开始,2 = 恢复,3 = 恢复暂停,4 = 从失败处开始,5 = 补充,6 = 调度,7 = 重新运行,8 = 暂停,9 = 停止 |
| workflow_definition_code |
bigint |
目标工作流 |
| workflow_instance_id |
int |
用于恢复/重新执行操作 |
| workflow_instance_priority |
int |
0 = 最高,1 = 高,2 = 中,3 = 低,4 = 最低 |
| command_param |
text |
JSON 格式的执行参数 |
| worker_group |
varchar(255) |
目标工作线程组 |
| tenant_code |
varchar(64) |
执行的租户 |
| dry_run |
tinyint |
0 = 正常,1 = 试运行(无实际执行) |
处理流程:
- 通过 API、调度程序或重试逻辑将命令插入
t_ds_command。
- 主服务器的
MasterSchedulerThread 持续扫描该表(按优先级、id 排序)。
- 主服务器生成
t_ds_workflow_instance 记录。
- 主服务器分析 DAG 并为就绪任务创建
t_ds_task_instance 记录。
- 成功处理的命令将被删除;失败的命令将移动到
t_ds_error_command。
版本控制系统
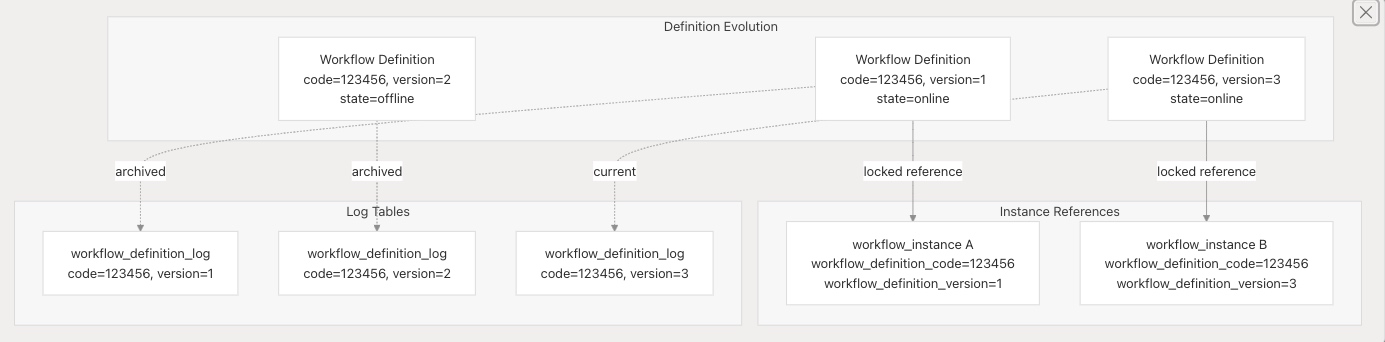
基于代码的版本控制模型
DolphinScheduler 使用复杂的版本控制系统,支持:
- 不同版本的并发执行。
- 安全更新而不影响正在运行的实例。
- 完整的变更审计跟踪。
![]()
版本管理规则
- 当前版本表:只有“当前”版本存在于
t_ds_workflow_definition 和 t_ds_task_definition 中。
- 日志表:所有版本保存在
*_log 表中,具有 UNIQUE KEY (code, version)。
- 在线状态:每个代码只能有一个版本的
release_state = 1(在线)。
- 实例锁定:工作流实例在创建时锁定到特定版本。
- 版本不可变性:一旦某个版本被实例引用,其日志记录即为不可变。
调度体系架构
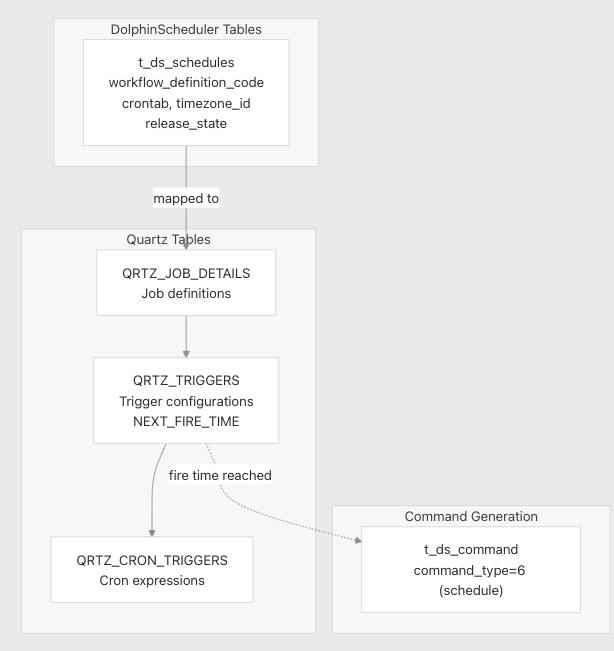
Quartz 集成
DolphinScheduler 集成了 Quartz 调度程序以实现基于 cron 的调度。模式包括标准 Quartz 表以及一个映射表。
![]()
t_ds_schedules
| 列 |
类型 |
描述 |
| workflow_definition_code |
bigint |
目标工作流(唯一) |
| start_time |
datetime |
调度活动开始时间 |
| end_time |
datetime |
调度活动结束时间 |
| timezone_id |
varchar(40) |
cron 表达式的时区 |
| crontab |
varchar(255) |
cron 表达式 |
| release_state |
int |
0 = 离线,1 = 在线 |
| failure_strategy |
int |
失败时的行为 |
| workflow_instance_priority |
int |
实例的默认优先级 |
Quartz 表要点:
QRTZ_TRIGGERS.NEXT_FIRE_TIME:已索引,便于高效扫描。QRTZ_CRON_TRIGGERS.CRON_EXPRESSION:解析后的 cron 定义。QRTZ_SCHEDULER_STATE:跟踪 Quartz 调度程序实例。
资源和配置表
数据源管理
t_ds_datasource
存储 SQL 任务的数据库连接配置。
| 列 |
类型 |
描述 |
| name |
varchar(64) |
数据源名称 |
| type |
tinyint |
数据库类型(MySQL、PostgreSQL、Hive 等) |
| connection_params |
text |
JSON 格式的连接配置(主机、端口、数据库、凭据) |
| user_id |
int |
所有者用户 |
约束:UNIQUE KEY (name, type) - 防止数据源重复。
文件资源
t_ds_resources(已弃用)
注意:此表在模式中已标记为弃用。资源元数据正在迁移到单独的存储后端。
| 列 |
类型 |
描述 |
| full_name |
varchar(128) |
包括租户的完整路径 |
| type |
int |
文件类型(文件/UDF) |
| size |
bigint |
文件大小(字节) |
| is_directory |
boolean |
目录标志 |
| pid |
int |
父目录 ID |
多租户与管理
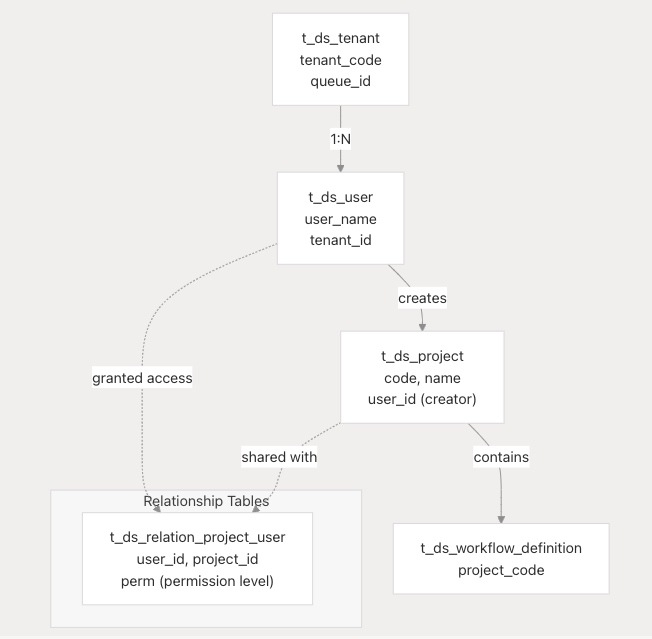
项目、用户和租户层次结构
![]()
关键管理表
t_ds_tenant
| 列 |
类型 |
描述 |
| tenant_code |
varchar(64) |
唯一租户标识符(唯一) |
| queue_id |
int |
任务的默认 YARN 队列 |
| description |
varchar(255) |
租户描述 |
默认租户:系统创建一个默认租户,id = -1,tenant_code = 'default'。
t_ds_user
| 列 |
类型 |
描述 |
| user_name |
varchar(64) |
登录用户名(唯一) |
| user_password |
varchar(64) |
哈希密码 |
| user_type |
tinyint |
0 = 普通用户,1 = 管理员 |
| tenant_id |
int |
关联的租户(默认 -1) |
| email |
varchar(64) |
电子邮件地址 |
| state |
tinyint |
0 = 禁用,1 = 启用 |
t_ds_project
| 列 |
类型 |
描述 |
| code |
bigint |
唯一项目代码(唯一) |
| name |
varchar(255) |
项目名称(唯一) |
| user_id |
int |
创建者/所有者 |
| description |
varchar(255) |
项目描述 |
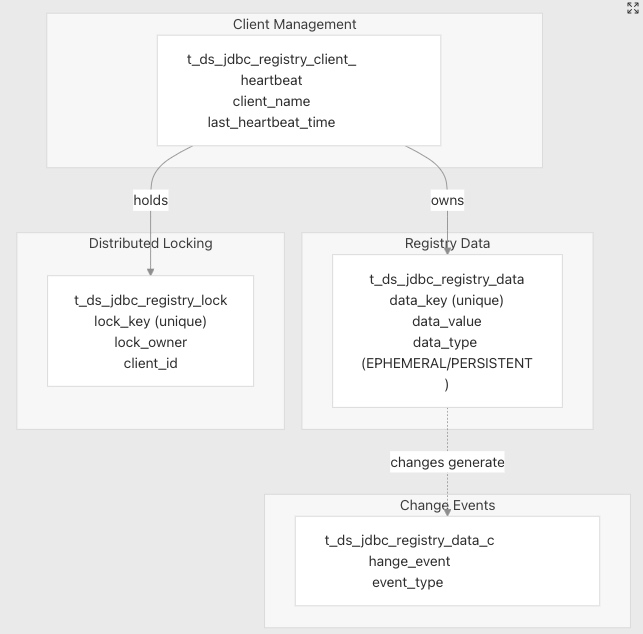
JDBC 注册表
对于不使用 ZooKeeper 的部署,DolphinScheduler 提供基于 JDBC 的注册表用于服务协调。
![]()
注册表详情
t_ds_jdbc_registry_data
存储类似于 ZooKeeper 节点的注册表项。
| 列 |
类型 |
描述 |
| data_key |
varchar(256) |
类似路径的键(唯一) |
| data_value |
text |
序列化数据 |
| data_type |
varchar(64) |
EPHEMERAL(客户端断开连接时删除)或 PERSISTENT |
| client_id |
bigint |
所属客户端 |
| 列 |
类型 |
描述 |
| last_update_time |
timestamp |
上次修改时间 |
t_ds_jdbc_registry_lock
实现分布式锁。
| 列 |
类型 |
描述 |
| lock_key |
varchar(256) |
锁标识符(唯一) |
| lock_owner |
varchar(256) |
持有锁的客户端(格式:ip_processId) |
| client_id |
bigint |
所属客户端 |
t_ds_jdbc_registry_client_heartbeat
跟踪活动客户端以清理临时数据。
| 列 |
类型 |
描述 |
| id |
bigint |
客户端 ID(主键) |
| client_name |
varchar(256) |
客户端标识符 |
| last_heartbeat_time |
bigint |
上次心跳时间戳 |
| connection_config |
text |
连接元数据 |
清理逻辑:当客户端的心跳过期时,其临时注册表数据和锁将自动删除。
告警系统
告警表
![]()
t_ds_alert
由工作流/任务失败或完成生成的告警记录。
| 列 |
类型 |
描述 |
| title |
varchar(512) |
告警标题 |
| sign |
char(40) |
内容的 SHA1 哈希值(用于去重) |
| content |
text |
告警消息正文 |
| alert_status |
tinyint |
0 = 等待,1 = 成功,2 = 失败 |
| warning_type |
tinyint |
1 = 工作流成功,2 = 工作流/任务失败 |
| workflow_instance_id |
int |
源工作流实例 |
| alertgroup_id |
int |
目标告警组 |
索引:KEY idx_sign (sign) - 实现去重。
t_ds_alertgroup
告警通道组。
| 列 |
类型 |
描述 |
| group_name |
varchar(255) |
唯一组名 |
| alert_instance_ids |
varchar(255) |
逗号分隔的插件实例 ID |
| description |
varchar(255) |
组描述 |
索引与查询优化
关键索引
该模式包含针对常见查询模式精心设计的索引:
- 按定义查询工作流实例:
`KEY workflow_instance_index (workflow_definition_code, id)`
- 按定义查询任务实例:
`KEY idx_task_instance_code_version (task_code, task_definition_version)`
- 用于监控的时间范围查询*:
`KEY start_time_index (start_time, end_time)`
基于优先级的命令扫描:
`KEY priority_id_index (workflow_instance_priority, id)`
- 正向和反向 DAG 遍历:
`KEY idx_pre_task_code_version (pre_task_code, pre_task_version)`
正向和反向 DAG 遍历:
`KEY idx_post_task_code_version (post_task_code, post_task_version)`
`KEY idx_code (project_code, workflow_definition_code)`
唯一约束
在数据库级别强制执行的关键业务规则:
| 表 |
约束 |
目的 |
t_ds_workflow_definition |
UNIQUE (name, project_code) |
项目中无重复的工作流名称 |
t_ds_workflow_definition |
UNIQUE (code) |
全局工作流标识符 |
t_ds_workflow_definition_log |
UNIQUE (code, version) |
每个版本一条记录 |
t_ds_datasource |
UNIQUE (name, type) |
每种类型无重复的数据源名称 |
t_ds_schedules |
UNIQUE (workflow_definition_code) |
每个工作流一个调度 |
模式演变与升级
DolphinScheduler 在 dolphinscheduler - dao/src/main/resources/sql/upgrade 中维护用于跨版本模式迁移的升级脚本。
近期模式变更
3.3.0 变更
- 将表和列从“process”重命名为“workflow”。
- 删除数据质量表(
t_ds_dq_*)。
- 添加用于替代 ZooKeeper 的 JDBC 注册表。
- 从任务表中删除与缓存相关的列。
3.2.0 变更
- 向工作流定义中添加
execution_type(并行/串行模式)。
- 为串行执行链添加
next_workflow_instance_id。
- 向命令和实例表中添加
tenant_code。
- 创建
t_ds_project_parameter 和 t_ds_project_preference。
数据库交互模式
服务层访问
数据库访问通过 dolphinscheduler - dao 中的 DAO 层进行抽象。 关键服务类:
ProcessService:工作流/任务定义和实例的 CRUD 操作。CommandService:命令队列管理。ProjectService:项目和权限管理。ResourcesService:资源元数据操作。
事务管理
大多数操作使用 Spring 的 @Transactional 注解实现:
- 原子性地创建工作流实例及其任务实例。
- 消费命令并创建实例。
- 版本更新与日志表同步。
连接池
系统使用 HikariCP 进行连接池,在 application.yaml 中配置:
- 默认池大小:50 个连接。
- 连接超时:30 秒。
- 空闲超时:600 秒。