作者:来自 Elastic Quynh Nguyen
学习如何在Elasticsearch中部署 e5 多语言嵌入模型,用于 vector search 和 cross-lingual retrieval。
从 vector search 到强大的 REST APIs,Elasticsearch 为开发者提供了最全面的搜索工具包。前往 GitHub 上的示例 notebooks探索新玩法。你也可以立即开始免费试用,或在本地运行 Elasticsearch。
介绍
在一个拥有全球用户的世界中,跨语言信息检索(cross-lingual information retrieval - CLIR)至关重要。CLIR 不再将搜索限制在单一语言,而是让你可以在任何语言中查找信息,从而提升用户体验并简化操作。想象一个全球化市场,电子商务用户可以用自己的语言搜索商品,而正确的结果会自动出现,无需提前对数据进行本地化。或者学术研究者可以用母语搜索论文,即使原文是其他语言,也能准确理解其中的细微差别。
多语言文本嵌入模型让我们能够实现这一点。嵌入是一种将文本含义表示为数值向量的方式。这些向量经过设计,使得含义相似的文本在高维空间中彼此接近。多语言文本嵌入模型特别旨在将不同语言中具有相同含义的单词和短语映射到相似的向量空间中。
像开源的 Multilingual E5 这样的模型在海量文本数据上训练,通常使用对比学习(contrastive learning)等技术。在这种方法中,模型学习区分含义相似的文本对(正样本)和含义不同的文本对(负样本)。模型会调整生成的向量,使正样本之间的相似度最大化,而负样本之间的相似度最小化。对于多语言模型,训练数据包括不同语言间的翻译文本对,使模型能够学习到一个适用于多种语言的共享表示空间。最终生成的嵌入可以用于各种 NLP 任务,包括跨语言搜索(cross-lingual search),通过比较文本嵌入之间的相似度来找到与查询语言无关的相关文档。
多语言向量搜索的好处
- 细微差别:vector search 擅长捕捉语义含义,而不仅仅是关键字匹配。这对于需要理解语言上下文和细微差别的任务至关重要。
- 跨语言理解:即使查询和文档使用不同的词汇,也能实现有效的信息检索。
- 相关性:通过关注查询与文档之间的概念相似性,提供更相关的结果。
例如,考虑一位研究“社交媒体对政治话语的影响”的学术研究者。使用vector search,他们可以输入 “l'impatto dei social media sul discorso politico”(意大利语)或 “ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị”(越南语)这样的查询,并找到用英语、西班牙语或任何已索引语言撰写的相关论文。这是因为 vector search 识别的是关于社交媒体影响政治的概念,而不仅仅是匹配相同关键字的论文。这极大地拓宽并加深了他们的研究。
开始入门
以下是在 Elasticsearch 中使用 E5 模型设置 CLIR 的方法(E5 模型开箱即用)。我们将使用开源的多语言 COCO 数据集(包含多语言图像标题)来帮助我们可视化两种类型的搜索:
- 使用其他语言的查询在单一英语数据集上进行搜索;
- 使用多语言查询在包含多语言文档的数据集上进行搜索。
然后,我们将利用混合搜索和重新排名的力量来进一步改善搜索结果。
前提条件
- Python 3.6+
- Elasticsearch 8+
- Elasticsearch Python client:
pip install elasticsearch
数据集
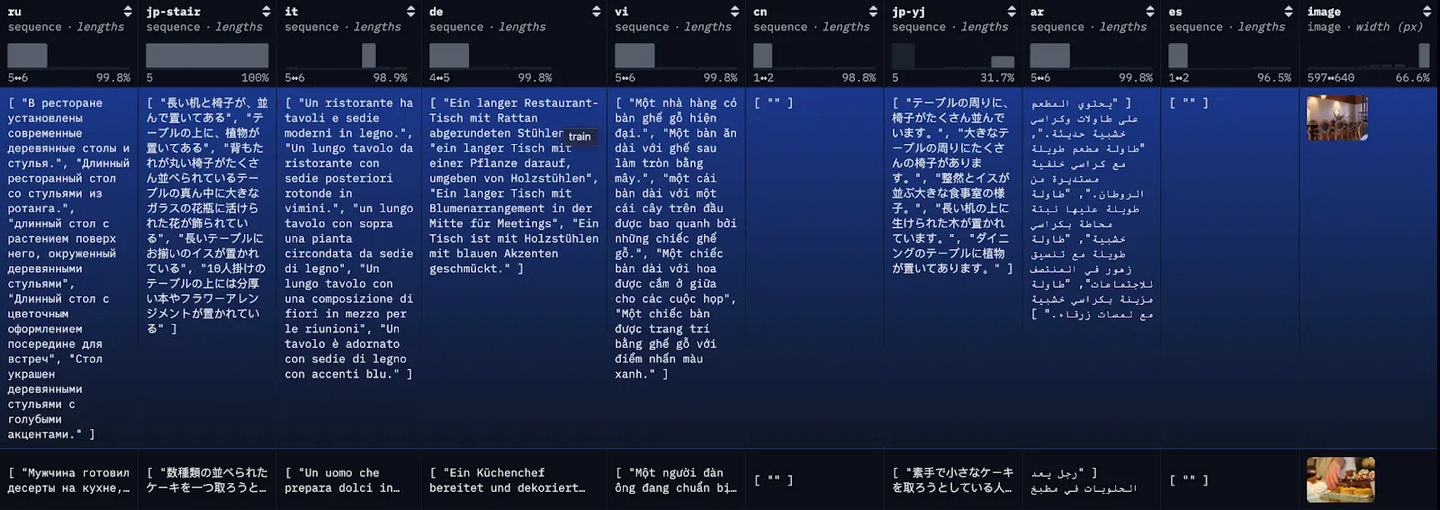
COCO 数据集是一个大规模的图像描述数据集。数据集中的每张图片都被用多种不同语言进行描述,每种语言都有多个翻译版本。
为了演示,我们将把每个翻译版本作为一个独立的文档进行索引,并附上第一个可用的英文翻译作为参考。
![]()
步骤 1:下载多语言 COCO 数据集
为了简化示例并便于跟进,这里我们通过一个简单的 API 调用,将 restval 的前 100 行加载到本地 JSON 文件中。
或者,你也可以使用 HuggingFace 的datasets库来加载完整数据集或其子集。
import requests
import json
import os
### Download multilingual coco dataset into a json file (for easy viewing)
### Here we are retrieving first 100 rows for this example
### Alternatively, you can use `datasets` library from Hugging Face
url = "https://datasets-server.huggingface.co/rows?dataset=romrawinjp%2Fmultilingual-coco&config=default&split=restval&offset=0&length=100"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
output_file = "multilingual_coco_sample.json"
### Loading the downloaded content into a json file locally
with open(output_file, "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
print(f"Data successfully downloaded and saved to {output_file}")
else:
print(f"Failed to download data: {response.status_code}")
print(response.text)
如果数据成功加载到 JSON 文件中,你应该会看到类似如下的信息:
Data successfully downloaded and saved to multilingual_coco_sample.json
步骤 2:(启动 Elasticsearch)并在 Elasticsearch 中索引数据
a) 启动本地的 Elasticsearch 服务器。
b) 初始化 Elasticsearch 客户端。
from elasticsearch import Elasticsearch
from getpass import getpass
# Initialize Elasticsearch client
es = Elasticsearch(getpass("Host: "), api_key=getpass("API Key: "))
index_name = "coco"
# Create the index if it doesn't exist
if not es.indices.exists(index=index_name):
es.indices.create(index=index_name, body=mapping)
c) 索引数据
# Load the JSON data
with open('./multilingual_coco_sample.json', 'r') as f:
data = json.load(f)
rows = data["rows"]
# List of languages to process
languages = ["en", "es", "de", "it", "vi", "th"]
# For each image, we will process each individual caption as its own document
bulk_data = []
for data in rows:
row = data["row"]
image = row.get("image")
image_url = image["src"]
# Process each language
for lang in languages:
# Skip if language not present in this row
if lang not in row:
continue
# Get all descriptions for this language
# along with first available English caption for reference
descriptions = row[lang]
first_eng_caption = row["en"][0]
# Prepare bulk indexing data
for description in descriptions:
if description == "":
continue
# Add index operation
bulk_data.append(
{"index": {"_index": index_name}}
)
# Add document
bulk_data.append({
"language": lang,
"description": description,
"en": first_eng_caption,
"image_url": image_url,
})
# Perform bulk indexing
if bulk_data:
try:
response = es.bulk(operations=bulk_data)
if response["errors"]:
print("Some documents failed to index")
else:
print(f"Successfully bulk indexed {len(bulk_data)} documents")
except Exception as e:
print(f"Error during bulk indexing: {str(e)}")
print("Indexing complete!")
数据索引完成后,你应该会看到类似如下的信息:
Successfully bulk indexed 4840 documents
Indexing complete!
步骤 3:部署 E5 训练模型
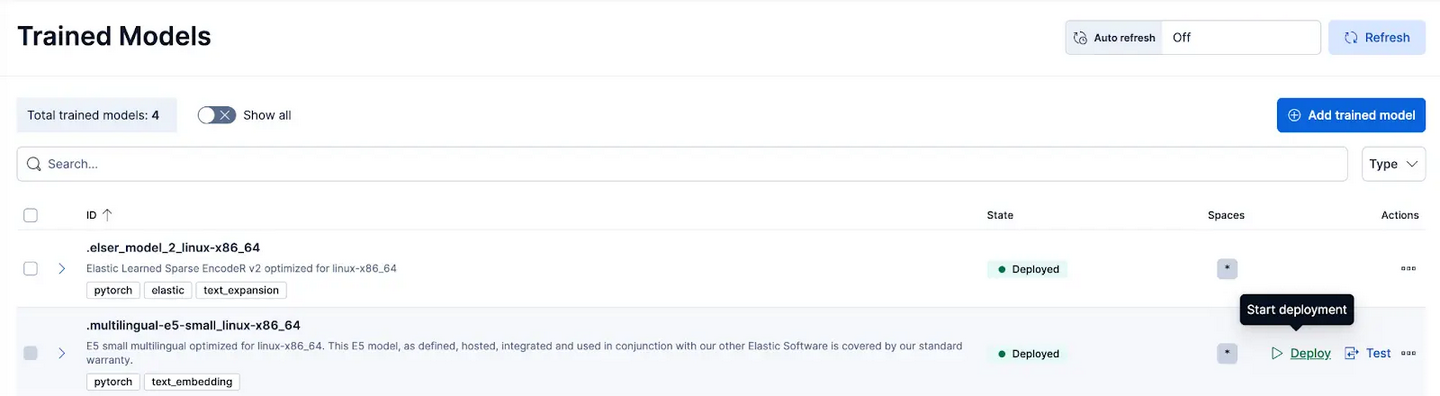
在 Kibana 中,导航到 Stack Management > Trained Models 页面,然后点击 .multilingual-e5-small_linux-x86_64 的 Deploy。
该 E5 模型是针对 linux-x86_64 优化的小型多语言模型,可开箱即用。
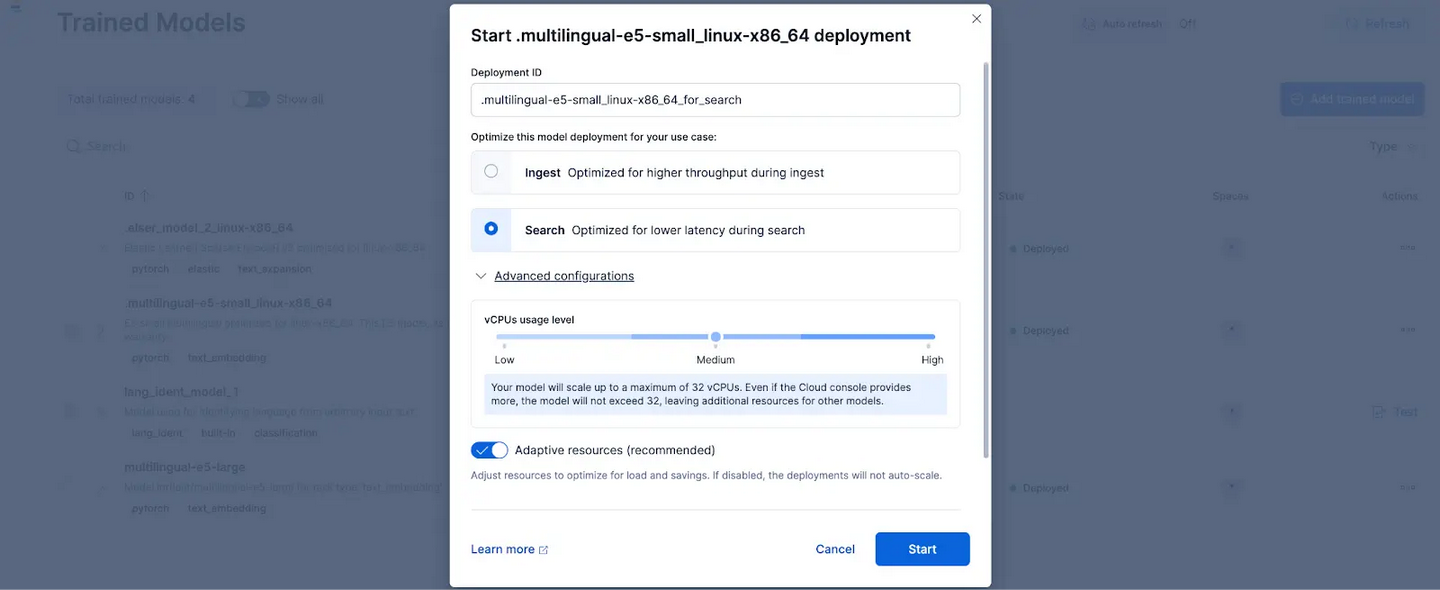
点击 Deploy 后,会显示一个界面,让你可以调整部署设置或 vCPU 配置。为简化操作,我们将使用默认选项,并选择 adaptive resources,它会根据使用情况自动调整部署规模。
![]()
![]()
可选地,如果你想使用其他文本嵌入模型,也是可以的。例如,要使用 BGE-M3,你可以使用 Elastic 的ElandPython 客户端从 HuggingFace 导入模型。
export MODEL_ID="bge-m3"
export HUB_MODEL_ID="BAAI/bge-m3"
export CLOUD_ID={{CLOUD_ID}}
export ES_API_KEY={{API_KEY}}
docker run -it --rm docker.elastic.co/eland/eland \
eland_import_hub_model --cloud-id $CLOUD_ID --es-api-key $ES_API_KEY --hub-model-id $HUB_MODEL_ID --es-model-id $MODEL_ID --task-type text_embedding --start
然后,导航到 Trained Models 页面,以所需配置部署导入的模型。
步骤 4:使用已部署的模型对原始数据进行向量化或创建嵌入
要创建嵌入,首先需要创建一个ingest pipeline,它允许我们将文本传入推理文本嵌入模型中。你可以通过 Kibana 的用户界面或 Elasticsearch 的 API 来完成此操作。
通过 Kibana 界面操作的方法如下:
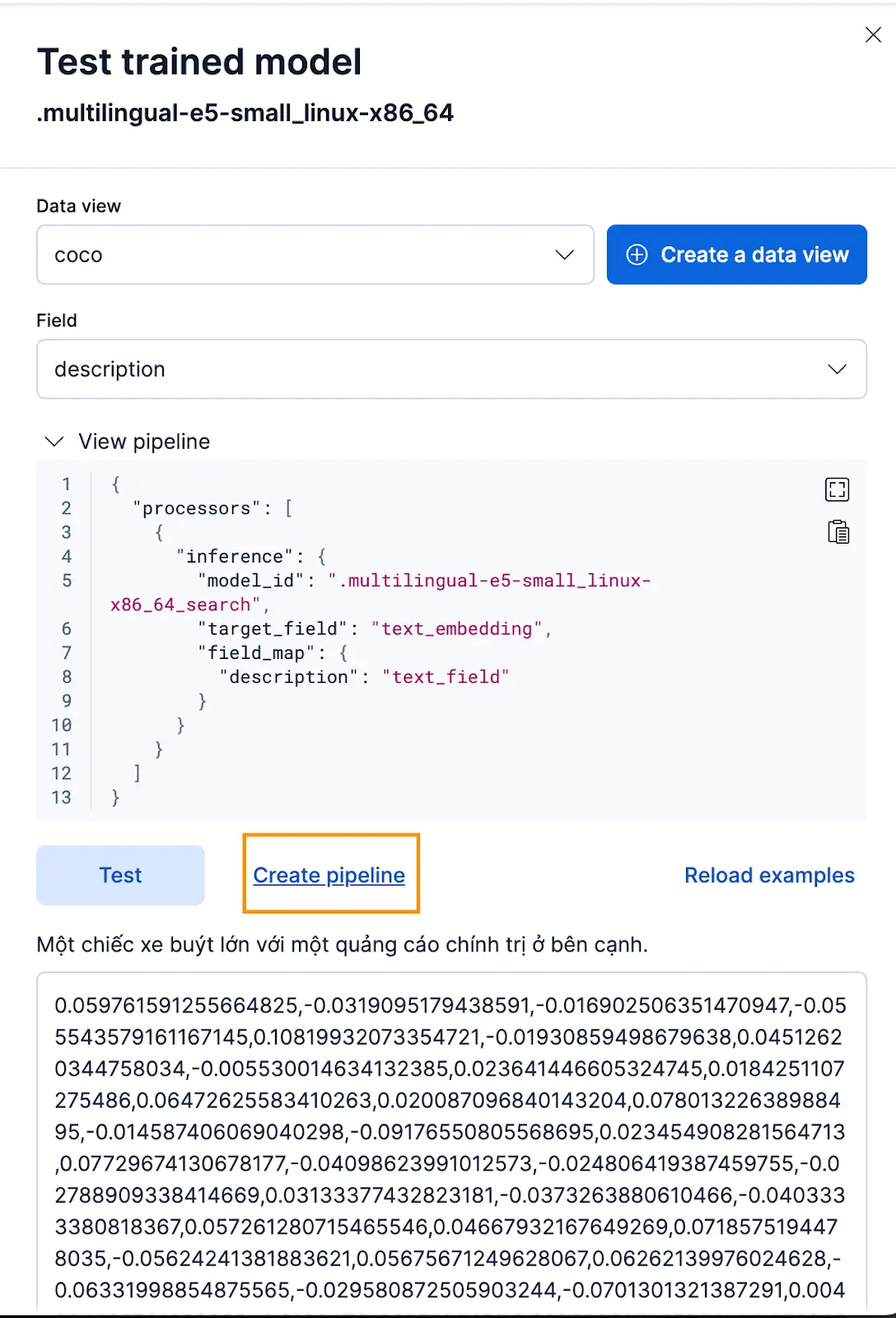
- 在部署 Trained Model 后,点击 Test 按钮。这可以让你测试并预览生成的嵌入。
- 为 coco 索引创建一个新的数据视图,将 Data view 设置为新创建的 coco 数据视图,并将 Field 设置为
description,因为这是我们希望生成嵌入的字段。
![]()
效果很好!现在我们可以继续创建ingest pipeline并重新索引原始文档,将它们通过管道处理,并创建一个包含嵌入的新索引。你可以点击Create pipeline来完成,这会引导你完成管道创建过程,并自动填充生成嵌入所需的处理器。
![]()
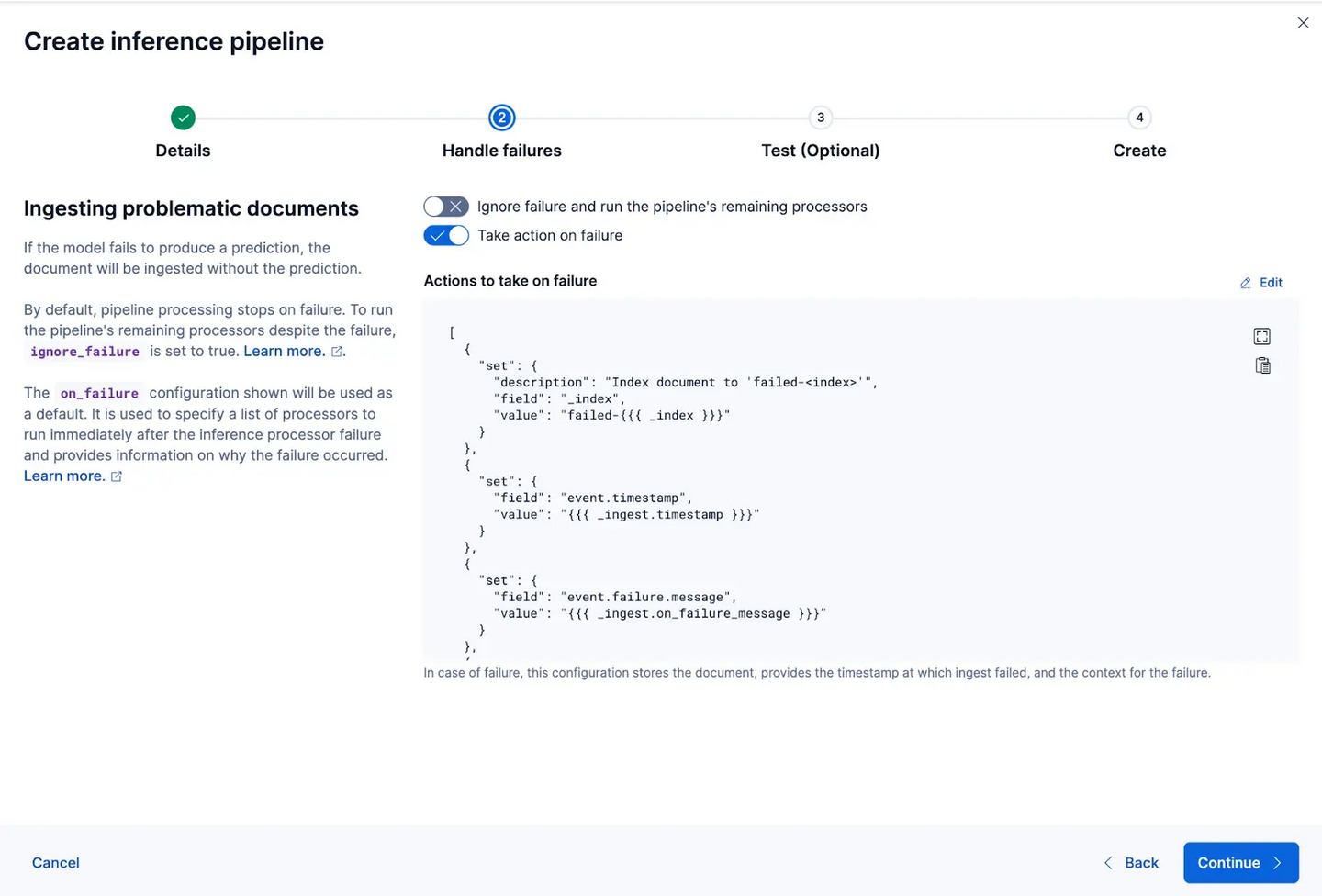
该向导还可以自动填充处理器,以在数据摄取和处理过程中处理失败情况。
![]()
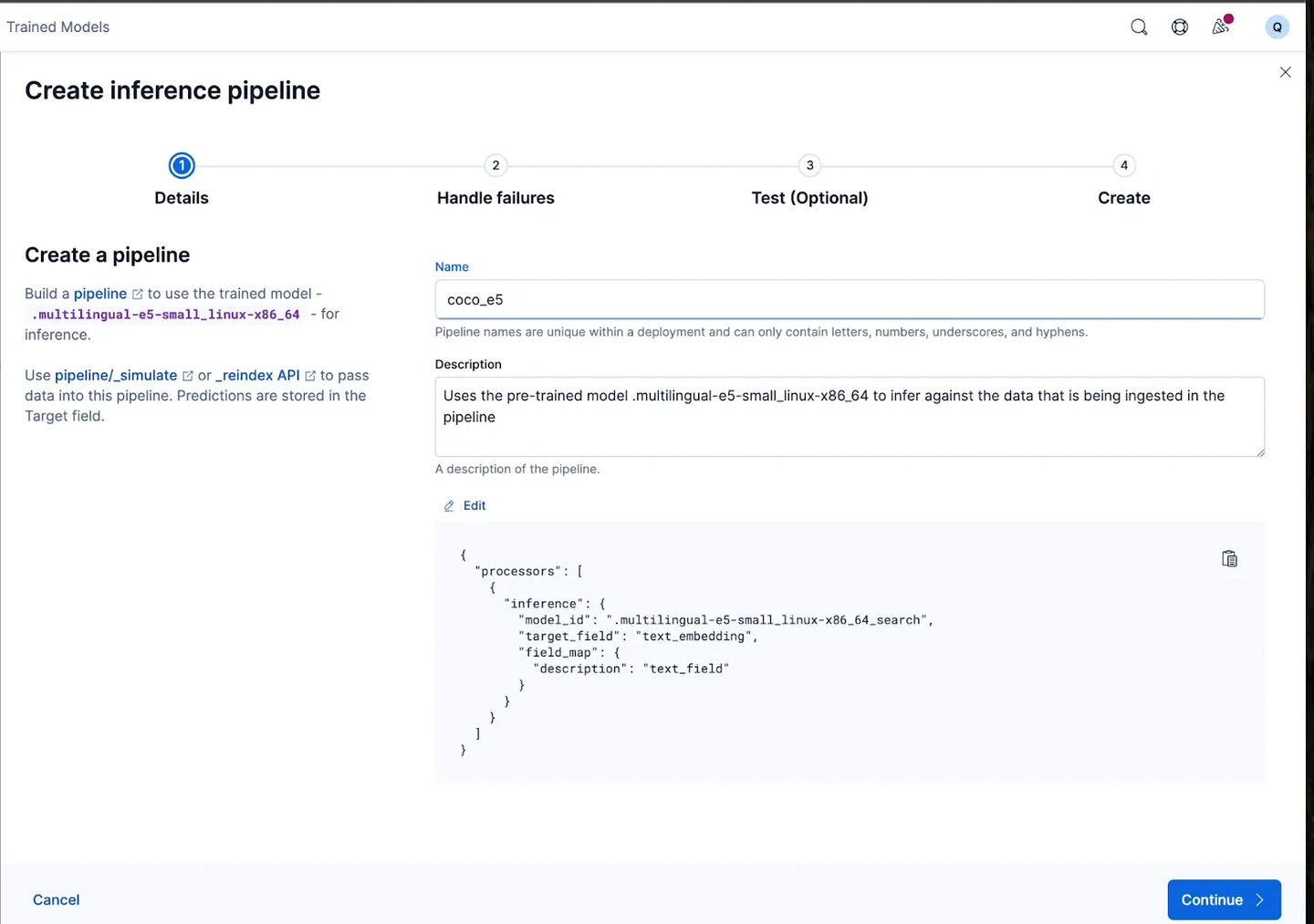
现在让我们创建 ingest pipeline,我将其命名为 coco_e5。
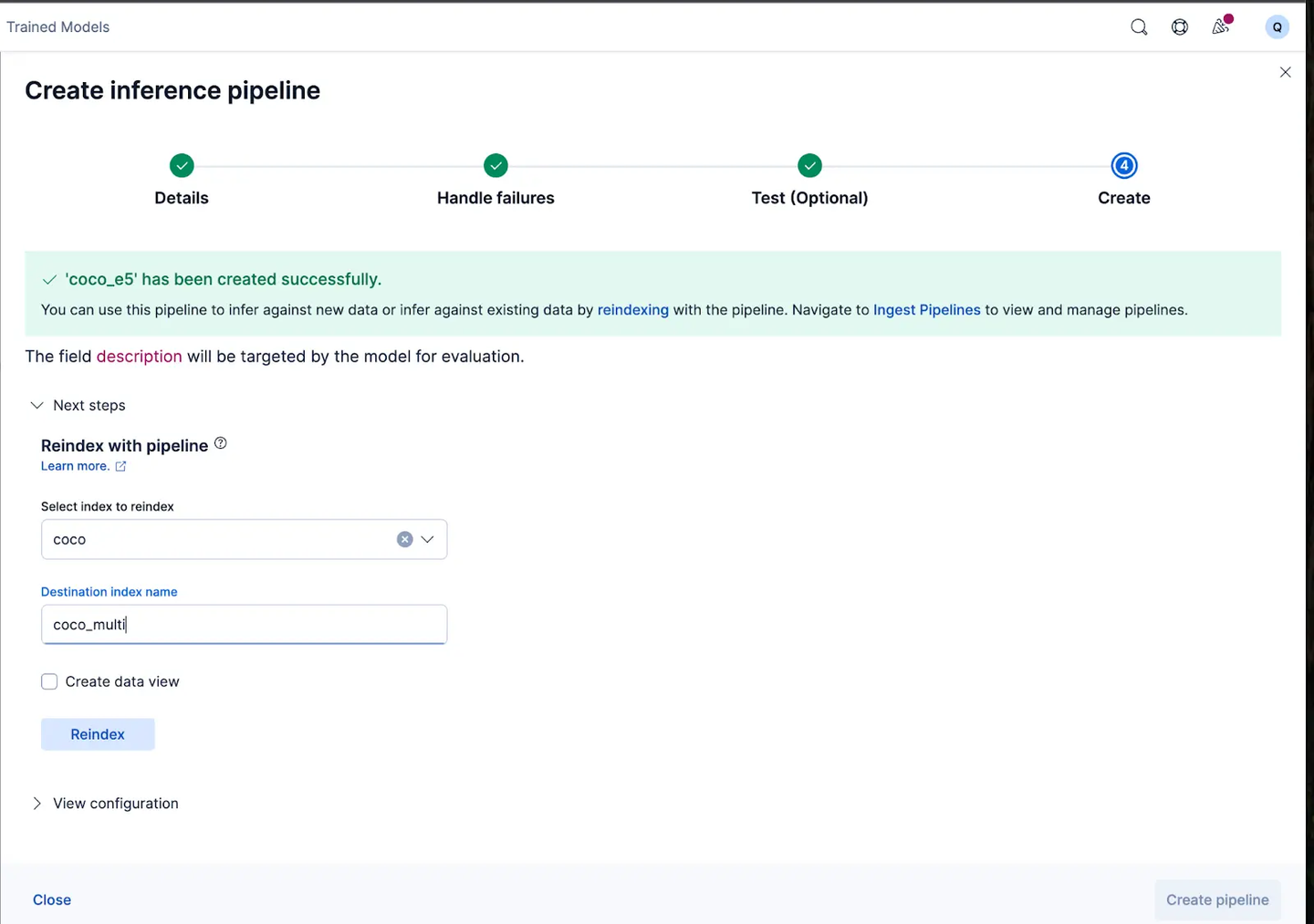
管道创建成功后,你可以立即使用该管道,通过向导将原始索引数据重新索引到新索引,从而生成嵌入。点击 Reindex 开始该过程。
![]()
对于更复杂的配置,我们可以使用 Elasticsearch API。
对于某些模型,由于训练方式的原因,在生成嵌入之前,可能需要在实际输入文本前后添加特定内容,否则性能可能下降。
例如,对于 E5,模型期望输入文本格式为passage: {content of passage}。我们可以利用ingest pipeline来实现这一点:
- 创建一个新的 ingest pipeline,命名为 vectorize_descriptions;
- 在该管道中,创建一个临时字段 temp_desc,在 description 文本前添加 "passage: ";
- 将 temp_desc 传入模型生成文本嵌入;
- 然后删除 temp_desc。
PUT _ingest/pipeline/vectorize_descriptions
{
"description": "Pipeline to run the descriptions text_field through our inference text embedding model",
"processors": [
{
"set": {
"field": "temp_desc",
"value": "passage: {{description}}"
}
},
{
"inference": {
"field_map": {
"temp_desc": "text_field"
},
"model_id": ".multilingual-e5-small_linux-x86_64_search",
"target_field": "vector_description"
}
},
{
"remove": {
"field": "temp_desc"
}
}
]
}
此外,我们可能希望指定生成向量的量化类型。默认情况下,Elasticsearch 使用int8_hnsw,但这里我想使用Better Binary Quantization(或bqq_hnsw),它将每个维度压缩为单比特精度。这可以将内存占用减少 96%(或 32 倍),但精度会有所下降。我选择这种量化类型,因为我知道稍后会使用reranker来改善精度损失。
为此,我们将创建一个名为coco_multi的新索引,并指定映射。在这里的关键在于vector_description字段,我们将index_options的类型指定为bbq_hnsw。
PUT coco_multi
{
"mappings": {
"properties": {
"description": {
"type": "text"
},
"en": {
"type": "text"
},
"image_url": {
"type": "keyword"
},
"language": {
"type": "keyword"
},
"vector_description.predicted_value": {
"type": "dense_vector",
"dims": 384,
"index": "true",
"similarity": "cosine",
"index_options": {
"type": "bbq_hnsw"
}
}
}
}
}
现在,我们可以使用ingest pipeline将原始文档重新索引到新索引,从而对descriptions字段进行“向量化”或生成嵌入。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "coco"
},
"dest": {
"index": "coco_multilingual",
"pipeline": "vectorize_descriptions"
}
}
就这样!我们已经成功在 Elasticsearch 和 Kibana 中部署了多语言模型,并逐步学习了如何使用 Elastic 为你的数据创建向量嵌入,无论是通过 Kibana 用户界面还是 Elasticsearch API。在本系列的第二部分,我们将探索结果以及使用多语言模型的细微差别。与此同时,你可以创建自己的 Cloud 集群,使用开箱即用的 E5 模型,在你选择的语言和数据集上尝试多语言语义搜索。
原文:https://www.elastic.co/search-labs/blog/multilingual-embedding-model-deployment-elasticsearch