核心能力
1. 全流程自动化
2. 高可用架构
-
支持高并发访问,具备主备容灾机制
-
系统稳定性与可维护性全面提升
3. 精细化部署策略
-
新增前端灰度发布能力
-
支持按业务需求灵活选择部署模式
部署模式
共享集群
私有集群
-
适用场景:
-
C端高流量页面(P0/P1级)
-
部门级需求(部门内部独立)
-
特点:
二、技术设计-流量视角
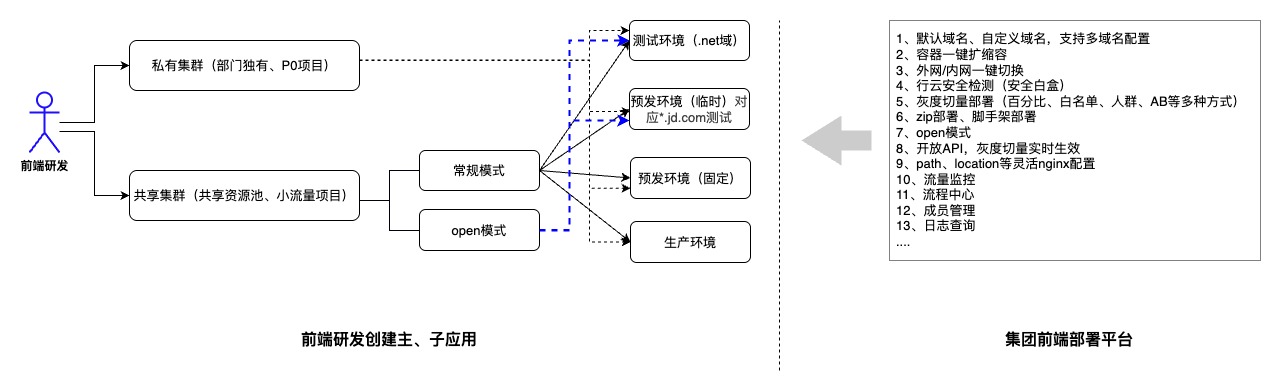
站在前端研发视角,您可以创建私有集群、共享集群应用。共享集权分为常规模式与open模式。open模式下,您不需要创建应用即可发布前端应用,open模式仅支持测试环境。详见图1所示
![]() 图1
图1
1. 常规流量
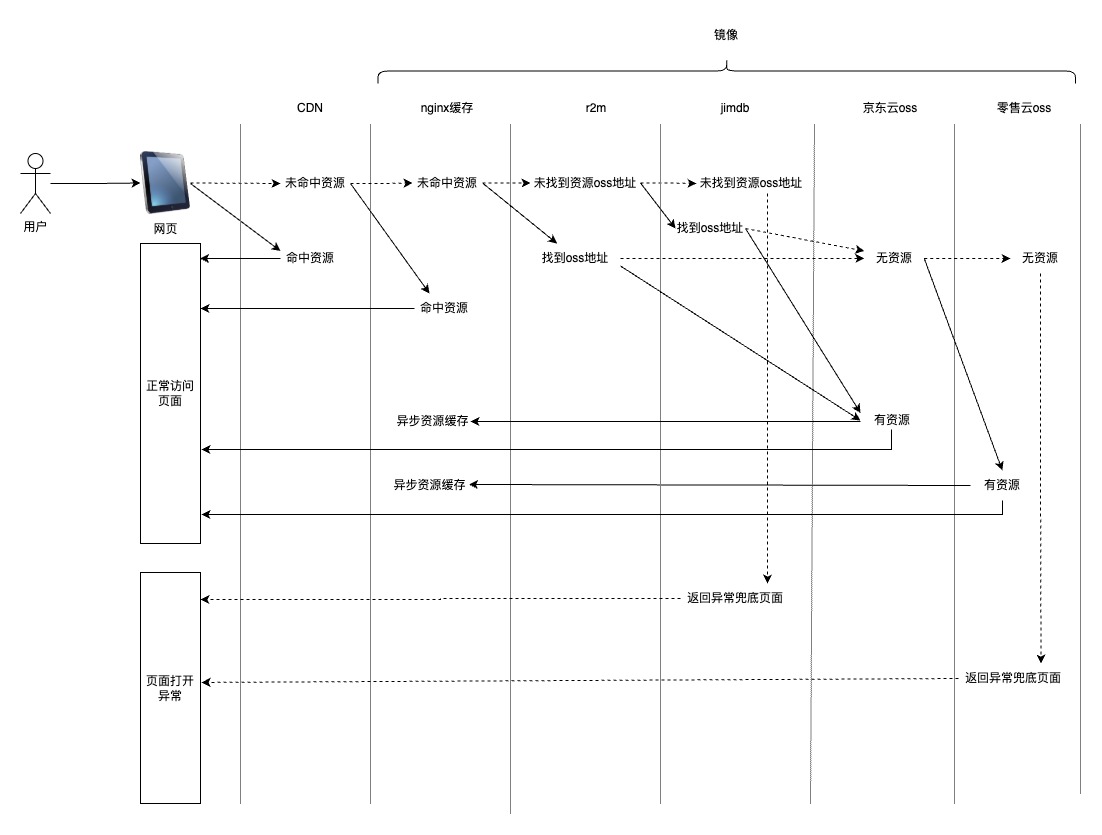
前端研发创建应用的时候,选择是否开启cdn,可以分为开启cdn与未开启cdn两种方式。
用户在浏览器打开url后,会根据研发的配置,寻找前端静态资源。
开启cdn:第一资源是cdn、第二资源是nginx缓存(10G)、第三资源是京东云oss、第四资源是零售云oss
未开启cdn:第一资源是nginx缓存(10G)、第二资源是京东云oss、第三资源是零售云oss。详见图2所示。
![]() 图2
图2
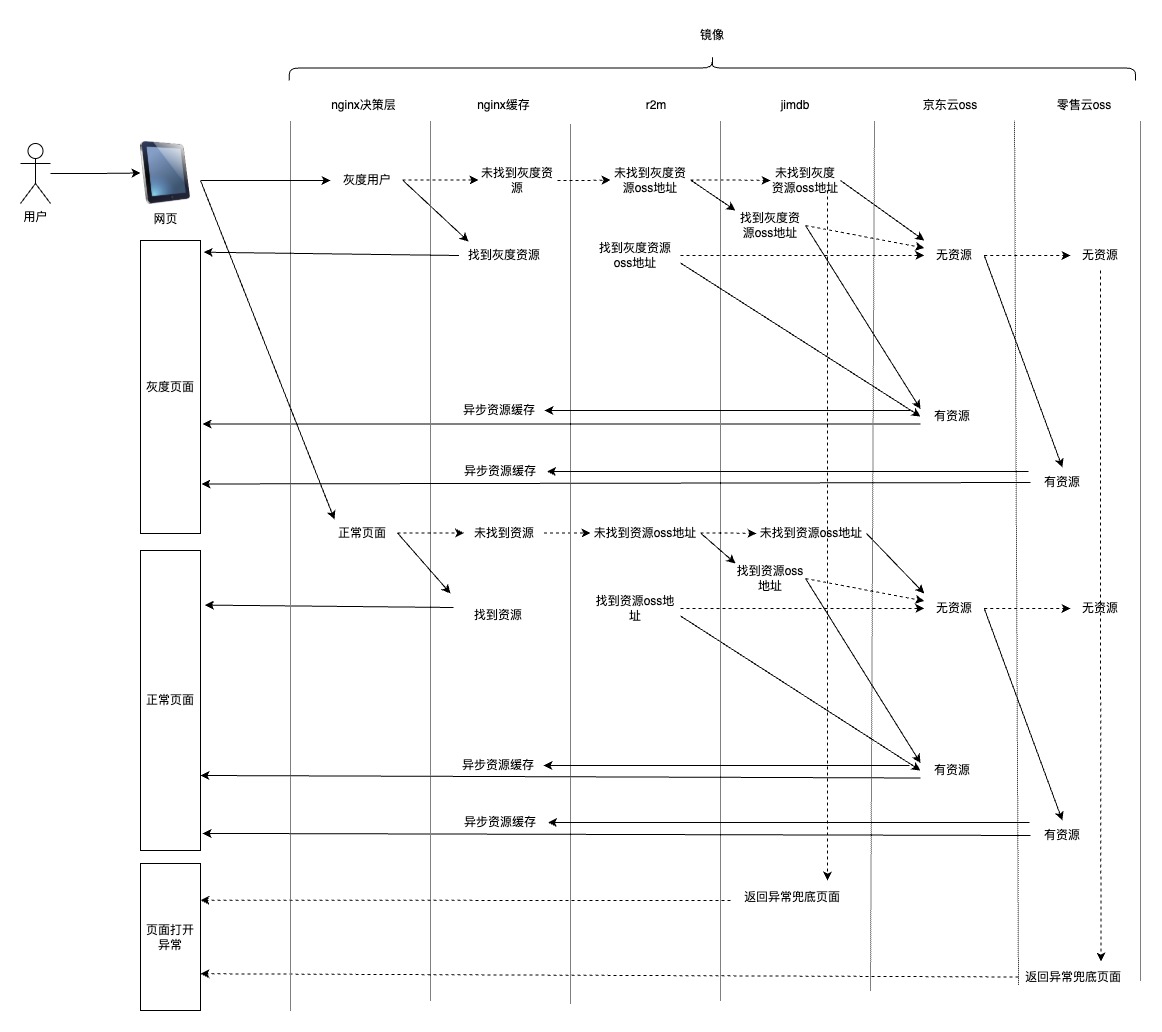
2. 灰度流量
前端研发配置灰度的时候,集团前端部署平台支持多种灰度模式,例如百分比、白名单、url参数、人群(25年Q4完成)、AB(25年Q4完成),该部分需要决策当前用户访问前端资源制定的版本,该流量会直接指向nginx层,该部分的决策能力由镜像提供,保证了每个容器对外一致性。
灰度期间:第一资源是nginx缓存(10G)、第二资源是京东云oss、第三资源是零售云oss。详见图3所示。
![]() 图3
图3
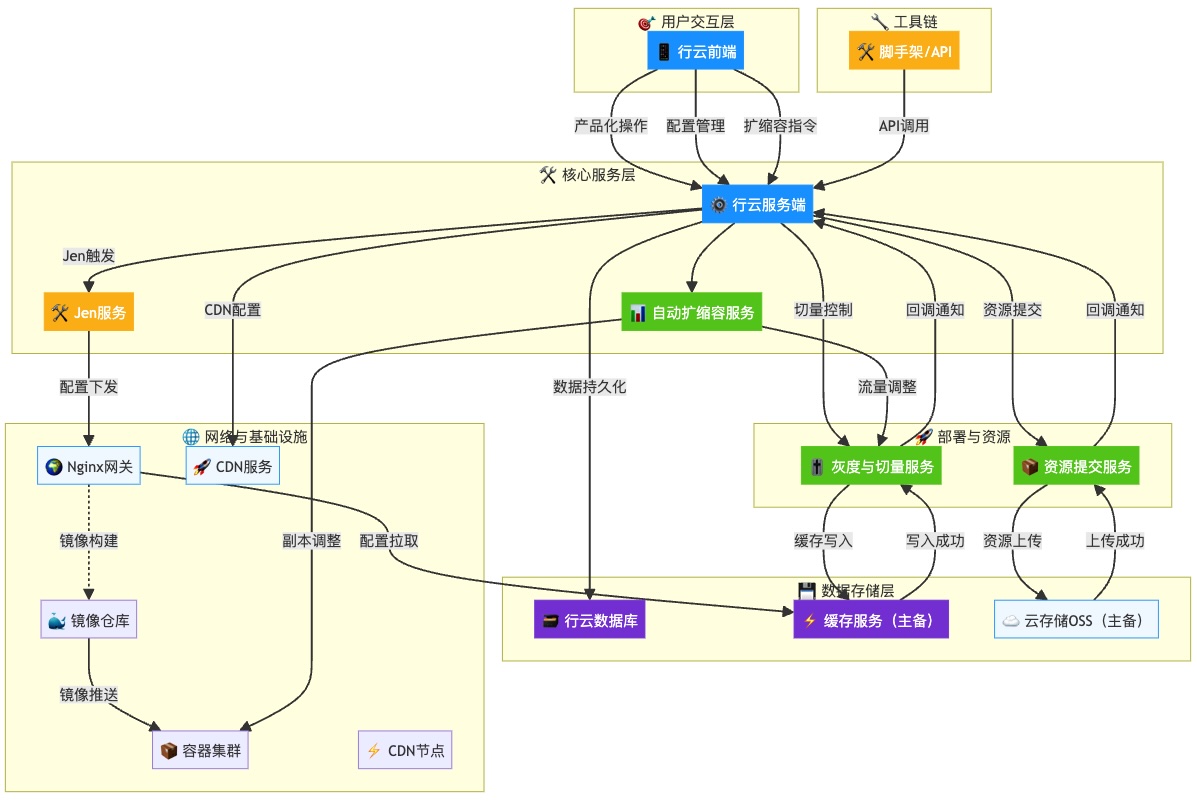
三、技术设计-各服务之间关系
集团前端部署平台系统按照P0级要求进行设计,设计目标
1、高可用:可用性达到 99.99%,主备设计。
2、高并发:CDN+nginx缓存+OSS设计。
3、易维护:共享集群、私有集群,项目独立。
各模块之间的关系详见图4所示
![]() 图4
图4
以上过程打通了Jen/行云/京东云OSS/零售云OSS/NP/CDN/R2M/JimDB/科技容器/零售容器/域名解析/镜像适配/测试站,除此之外我们还会打通持续交付、eone、监控检测等(25年Q4完成)
四、技术设计-精细化运营保证
1. 设计背景
为满足以下关键业务场景需求,集团前端部署平台进行了专项设计优化:
| Cookie 名称 |
含义 |
注入方式 |
| jddid_i |
部署id,deployId |
js |
| jddid_s |
当前会话id,32位 |
js |
| jddid_sg |
策略id(Grayscale strategy),有值则是灰度版本,无值则是normal版本 |
nginx |
2. 业务方-前端研发使用
为了便捷前端研发使用,前端研发也可通过js获取。
// 部署id
const jddid_i = window.__unifiedDeployMap__?.jddid_i;
// 单次页面当前会话有效
const jddid_s = window.__unifiedDeployMap__?.jddid_s;
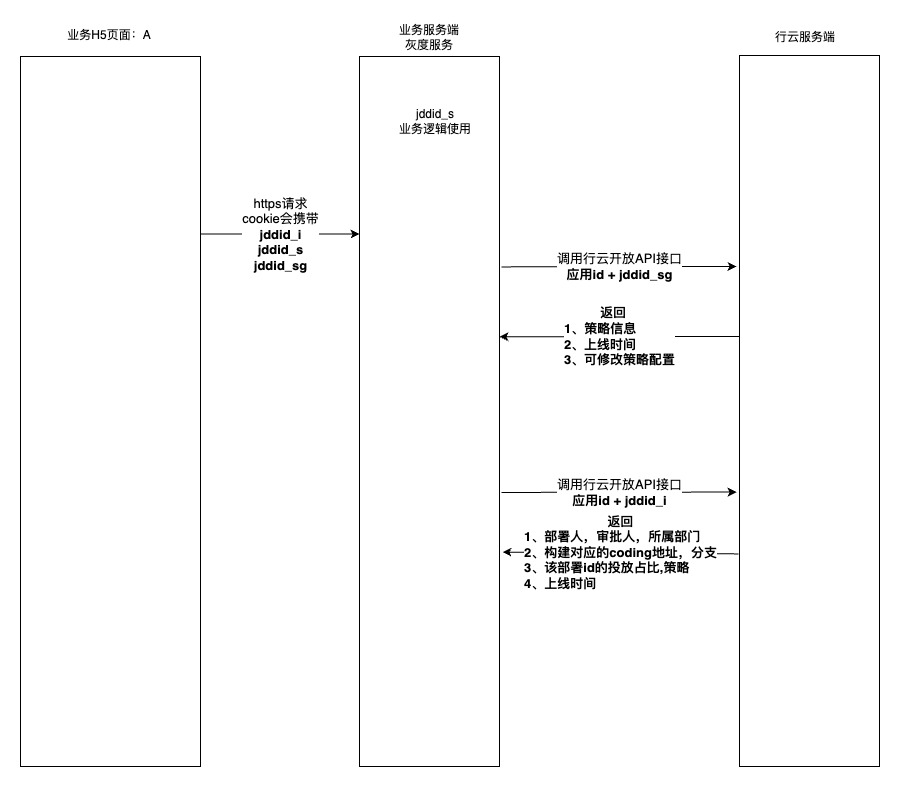
3. 业务方-服务端如何使用
为保证业务方前后端数据一致性,服务端可通过专用接口获取终端用户的灰度状态及配置信息。具体集成流程详见图5示意图。
![]() 图5
图5
核心价值:
-
确保灰度用户在全链路的体验一致性
-
支持服务端基于灰度策略进行差异化处理
-
实现前后端数据的精准匹配与分析