

英伟达将逐步向 OpenAI 投资最多 1000 亿美元
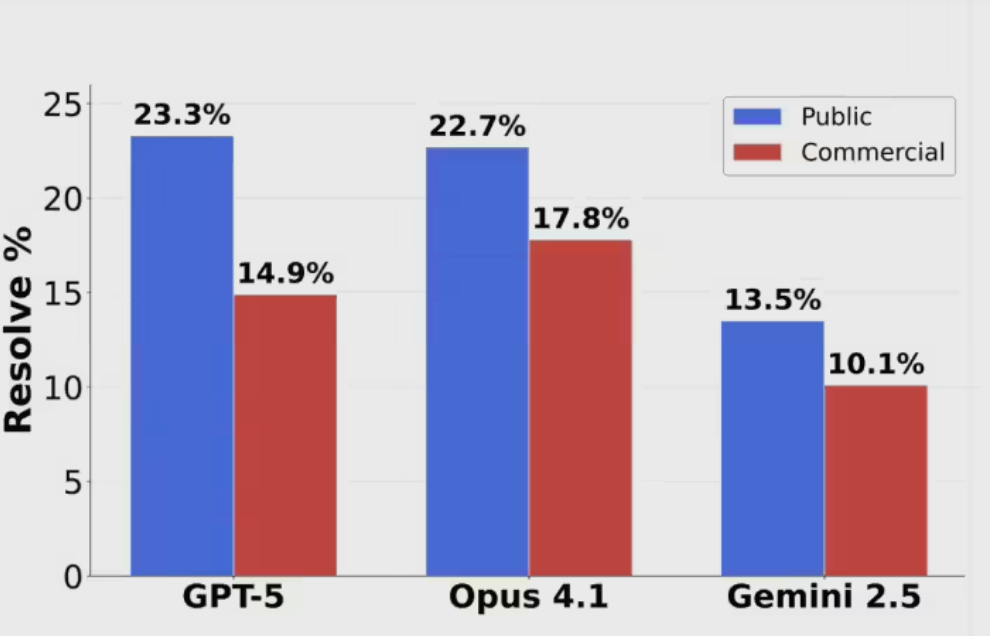
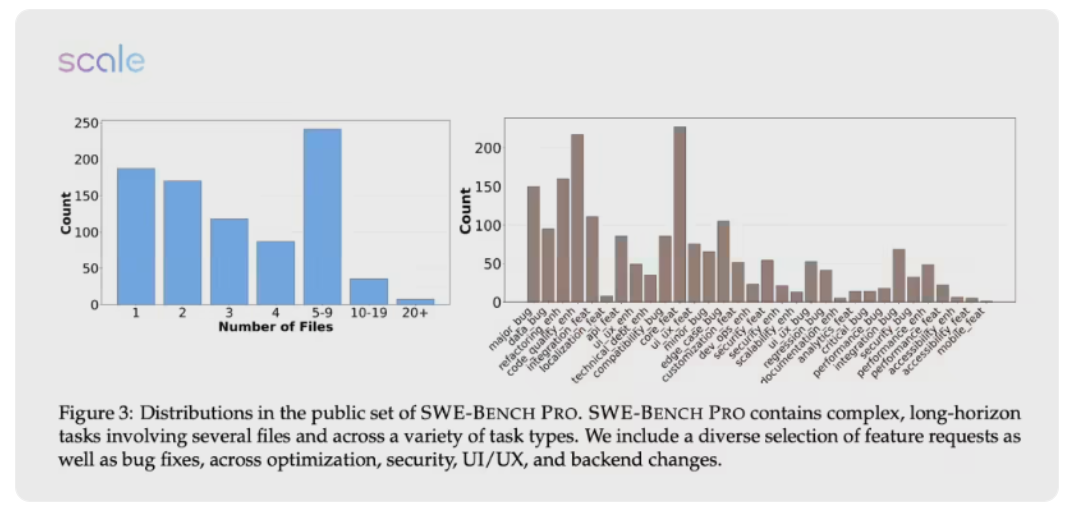
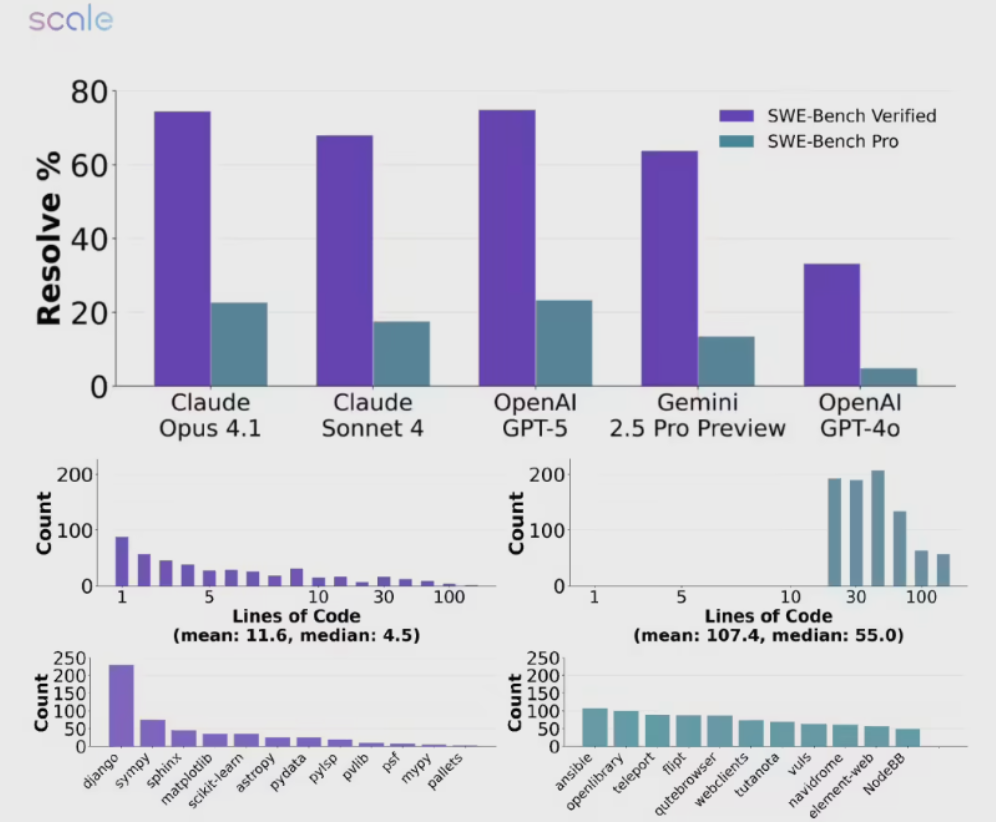
当地时间9月22日,OpenAI与英伟达宣布建立合作伙伴关系的意向书。 英伟达有意将逐步向OpenAI投资最多1000亿美元,用于支持数据中心及相关基础设施建设。双方合作将为OpenAI的下一代人工智能基础设施部署至少10吉瓦的英伟达系统,首批吉瓦级英伟达系统将于2026年下半年部署。这一耗电量相当于800万户美国家庭的用电量。 英伟达CEO黄仁勋周一在接受采访时表示,10吉瓦相当于400万至500万块图形处理器(GPU),约等于英伟达今年的出货总量,是去年的两倍。“这是一个庞大的项目”,黄仁勋与OpenAI首席执行官奥尔特曼以及总裁布罗克曼一同接受采访时表示。 据知情人士透露,英伟达首笔100亿美元投资将在第一个吉瓦数据中心建成时投入。投资将按当时的估值进行。双方表示,英伟达将随着每一吉瓦数据中心上线逐步投资,首个阶段预计在2026年下半年启用,基于英伟达的Vera Rubin平台。合作细节将在未来数周敲定。