作者:屈岳(尧道)
引言
日志服务 SLS 作为云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台服务。在常规场景中,其全生命周期管理能力(采集、加工、查询分析、可视化、告警、消费投递等)已能高效满足需求。
但面对以下典型场景时,传统解决方案往往面临高成本与高风险:
- 上线时意外将用户手机号明文写入 TB 级日志数据
- 版本迭代中测试数据污染生产数据分析
- 线上故障后需快速清除非预期数据
SLS 全新推出的「软删除」功能,以接近索引查询的性能,解决了数据应急删除与脏数据治理的痛点。2 分钟掌握这一数据管理神器。
什么是软删除
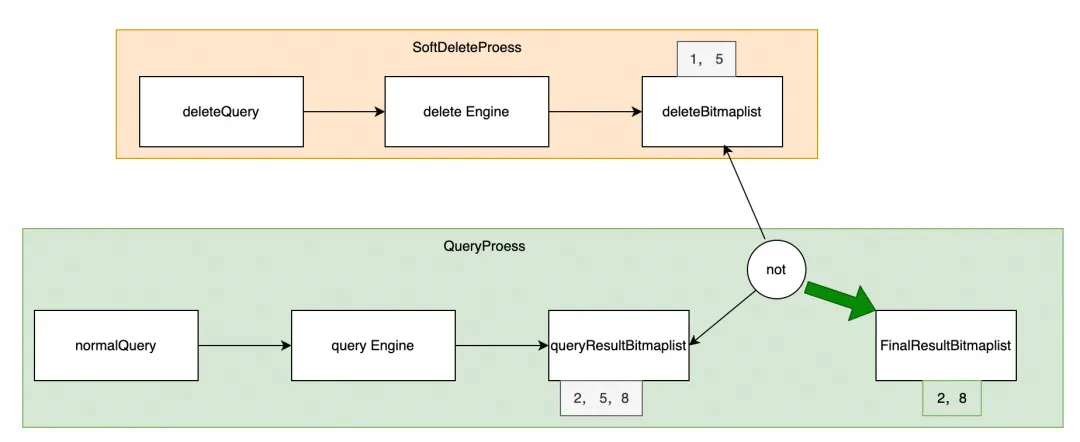
为何 SLS 此前不支持硬删除?作为面向大规模数据场景的实时日志平台,其设计初衷是极致的写入与查询性能。硬删除需定位原始文件及关联索引、列存文件中的数据位置并执行删除,涉及的资源消耗、状态同步和实时性要求在分布式系统中代价过大。
SLS 通过「标记+过滤」机制实现软删除:物理数据保留,但对用户隐藏。该设计在保证系统稳定性的同时,满足了数据删除的紧急需求。
软删除实现原理
传统硬删除需扫描改写底层存储,在 PB 级数据量下将引发显著 IO 开销与系统抖动风险。
SLS 软删除基于「标记+过滤」机制:
- 删除操作:主要分为两步(整体性能接近索引查询)
a)通过查询,快速筛选出需要被删除的日志行
b)对筛选出的日志行进行标记,表示数据被删除
- 查询过滤:自动屏蔽被标记数据,立即生效,同时支持查询和 sql
类比家庭整理:将不需要的物品标记隔离(软删除),待垃圾回收人员(TTL 过期后)统一清理(物理删除),既保持表面整洁又规避立即处理的成本。
![]()
优雅解决用户痛点
场景一:凌晨 3 点的紧急响应
某电商运维工程师小王遭遇双 11 前紧急事件:新上线的订单系统持续 2 小时将用户手机号明文写入日志。
-
传统方案
- 停机整改影响业务
- 通过 SPL 实时消费过滤后重写日志至新 logstore
- 消耗 6 小时处理 TB 级数据,业务中断
-
软删除方案
from_time = (int)(time.time()) - 2 * 3600 to_time = (int)(time.time()) toDeleteQuery = phoneNumber:* request = DeleteLogsRequest(project, logstore, from_time, to_time, query=toDeleteQuery) res: DeleteLogsResponse = client.delete_logs(request)
-
通过指定时间范围和删除条件删除敏感日志,秒级完成
-
查询结果立即隐藏敏感数据
-
业务持续运行无感知中断
-
数据随 logstore TTL 自动物理清理
场景二:测试数据污染生产环境
金融公司分析师发现风控模型异常,溯源发现测试环境数据流入生产日志污染模型训练。
-
传统方案 1
ETL 数据清洗方案耗时且成本高
-
传统方案 2
- 停止分析任务并抽象查询条件
- 遍历修改所有查询语句添加过滤条件
- 在字段未开启统计时需重建索引
- 整体耗时 2-3 天影响业务决策
-
软删除方案
from_time = (int)(time.time()) - 2 * 24 * 3600 to_time = (int)(time.time()) toDeleteQuery = dataSource:testEnv request = DeleteLogsRequest(project, logstore, from_time, to_time, query=toDeleteQuery) res: DeleteLogsResponse = client.delete_logs(request)
-
精准标记删除测试数据,秒级完成
-
分析任务无需修改即可恢复运行
-
实现真正的"数据急救"
场景三:精准剔除故障异常日志
某 SaaS 服务提供商,其核心业务是为企业客户提供在线协作平台。最近一周,某个 bug 版本(version)升级后,后端 actiontrail 模块产生了大量带有特定错误码(error_code)和关键日志标记(event_type: "file_upload_error")的异常日志,这些日志不仅污染了监控告警,也干扰了后续的数据分析。需要紧急清理异常日志。
-
传统方案 1
ETL 数据清洗方案耗时且成本高
-
传统方案 2
每次分析或查看监控图表时都需要额外添加脏数据过滤条件,不仅操作繁琐,还可能触发 SLS 资源限制。
-
软删除方案
from_time = (int)(time.time()) - 7 * 24 * 3600 to_time = (int)(time.time()) toDeleteQuery = '''version>=2.1 and version < 2.3 and tag:path: "/user/actiontrail.LOG" and (error_code:500 or error_code:502) and event_type:file_upload_error''' request = DeleteLogsRequest(project, logstore, from_time, to_time, query=toDeleteQuery) res: DeleteLogsResponse = client.delete_logs(request)
-
通过数值范围、文本多值匹配精准识别异常日志
-
精准删除异常日志,秒级完成。后台自动 merge 和高效 cache 删除信息,查询分析性能基本没有影响
-
数据报表后台自动刷新为订正后结果
-
删除之后如果发现还有其他数据也要删除,再次触发删除操作即可
写在最后
在数据治理需求日益增长的当下,"让数据立即消失"成为高频诉求。无论是合规要求、突发故障还是日常运维,都需要即时生效的删除方案。
传统方案需在数据清理速度与系统稳定性间权衡,而软删除实现了两者的兼得。该功能已在多场景稳定运行,成功应对诸多紧急情况。目前新加坡和华北 6(乌兰察布)已支持软删除, 其他地域逐步灰度中。如有需要欢迎点击如何使用软删除 [ 1] 获取实战指南。
相关链接:
[1] 如何使用软删除
https://help.aliyun.com/zh/sls/soft-delete
点击此处,了解更多产品详情。