引言
"有没有遇到过这种情况?销售总监刚让你做一张行按「地区」、列按「支付方式」的销售报表,市场部又需要行按「产品类别」、列按「月份」查看数据。你只能无奈地再开发一张?或者,老板临时想将列的维度从「支付方式」切换成「月份」进行分析,你却只能回答:'等我重新调整矩表结构,下午给您'?"
"其实,你只需要一张会'自动变身'的智能报表就够了。"
其核心价值在于:仅凭一张报表,通过参数驱动,即可实现行、列分组维度的自由组合与切换,彻底告别重复开发,效率提升可达80%以上。
这就像为数据搭建乐高模型。行分析参数是你的左手,想按「地区」分组,就把「地区」这块底座积木安上;想换「产品类别」,左手换块积木就行。列分析参数是你的右手,要按「支付方式」展示,就把「支付方式」这块侧边积木插上;想切「月份」,右手换块积木即可。报表引擎(矩表)会立刻接收到双手的指令,自动把选中的行、列积木拼在一起,呈现出对应的分组数据。就像换不同的乐高零件,拼出来的造型(数据呈现)立刻不一样,但不用拆了重搭 ------ 矩表会自动帮你拼好新样子。
![]()
理论千遍,不如实战一回。接下来,我们以两个高频场景为例,手把手带你走完实现步骤。
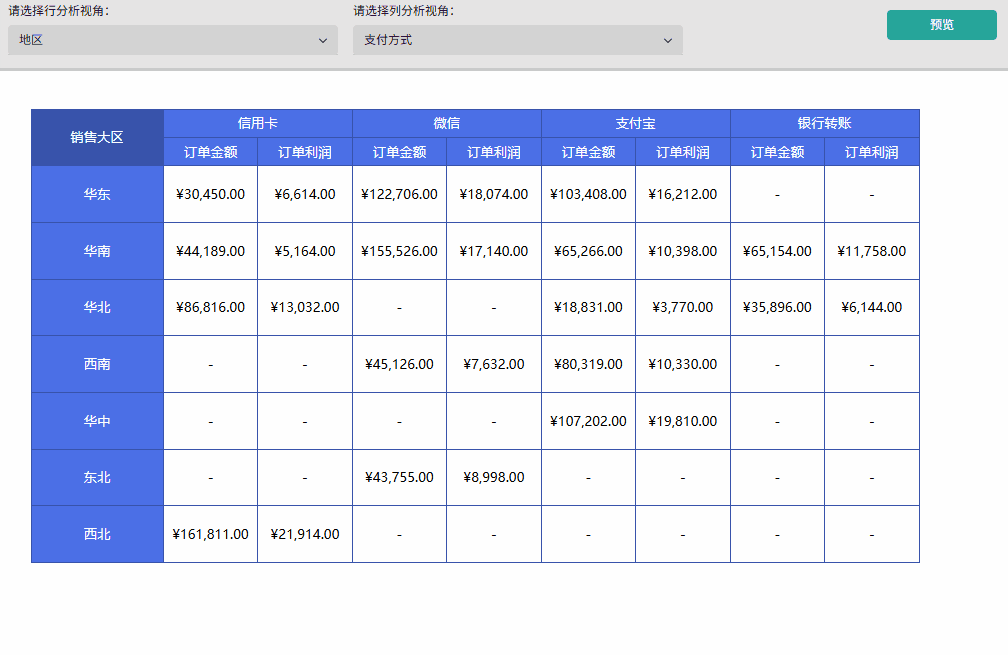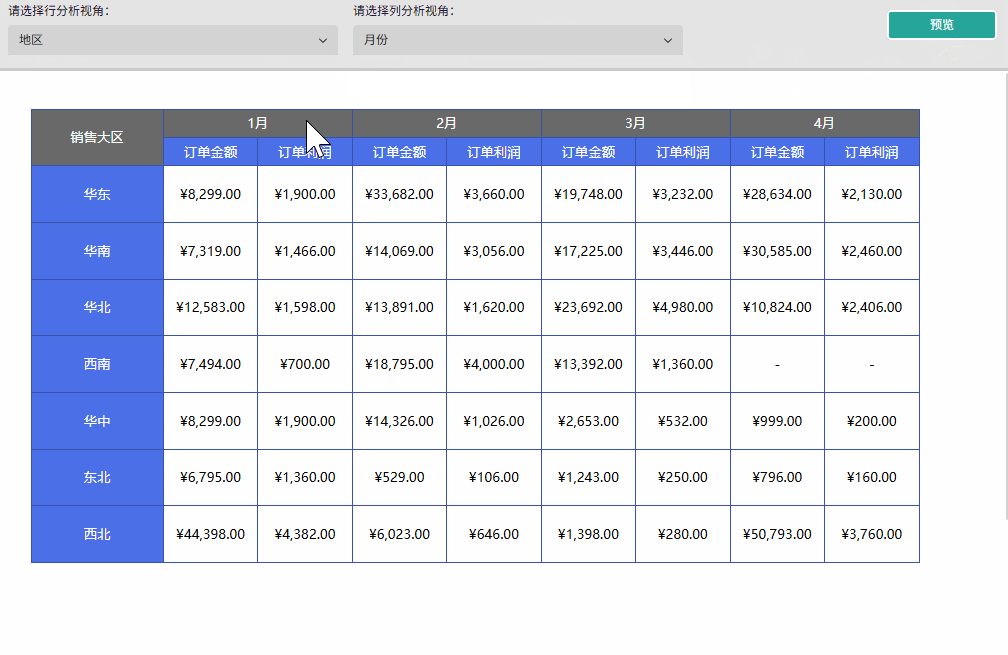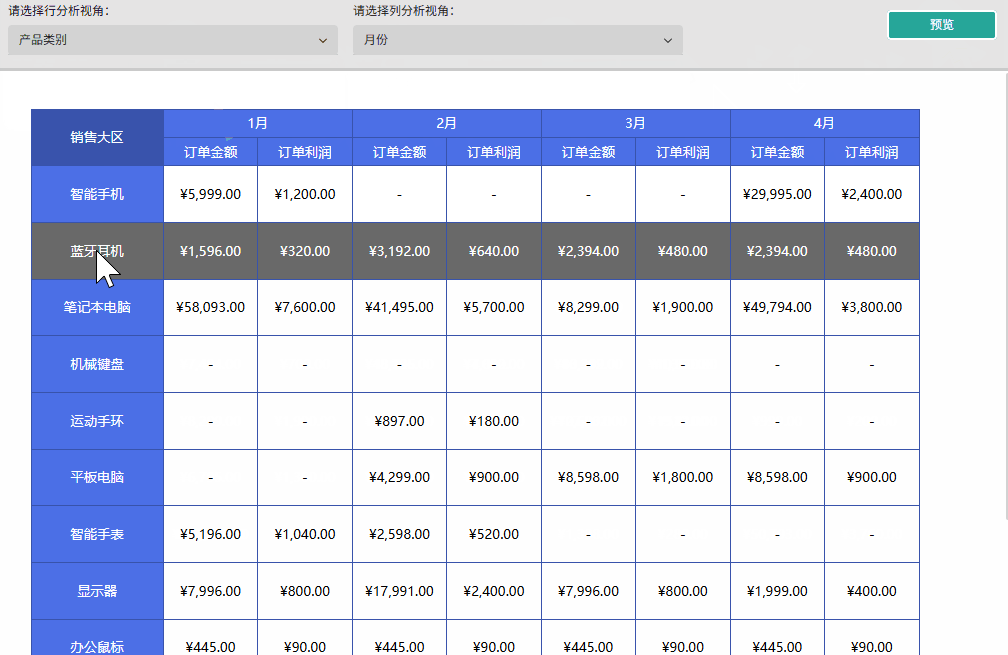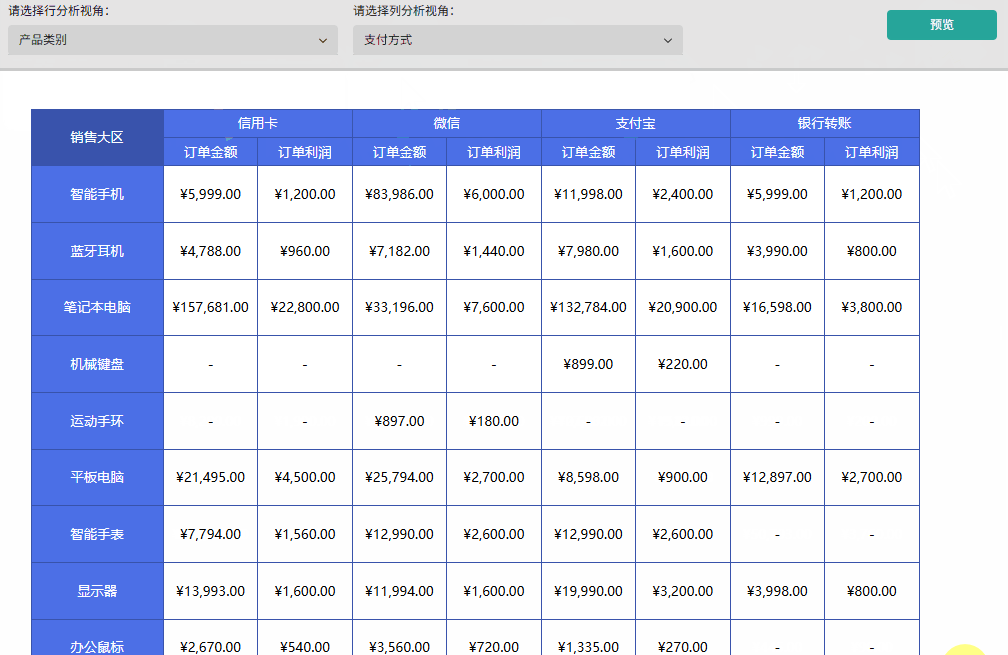
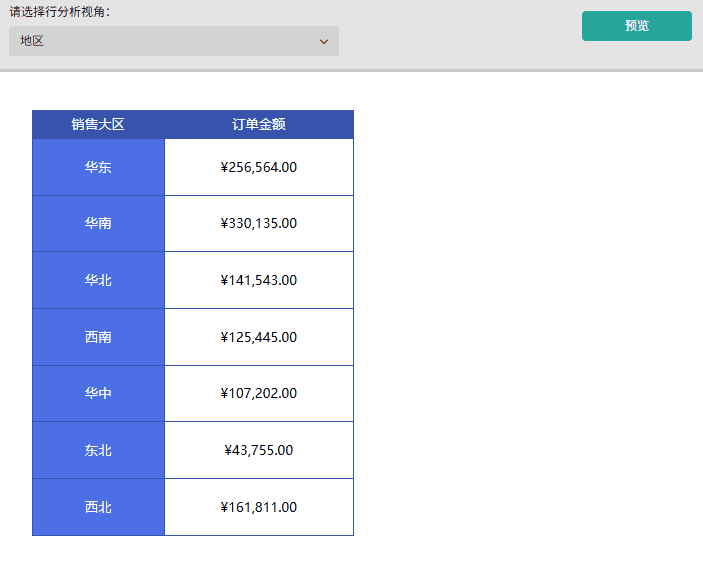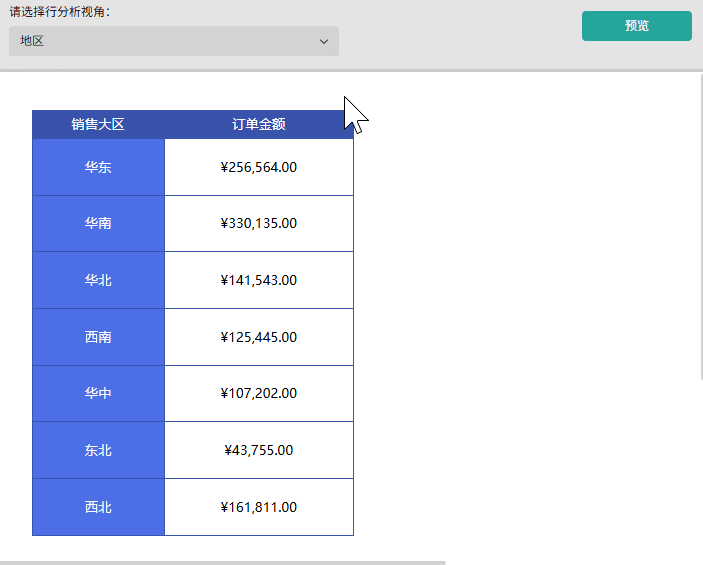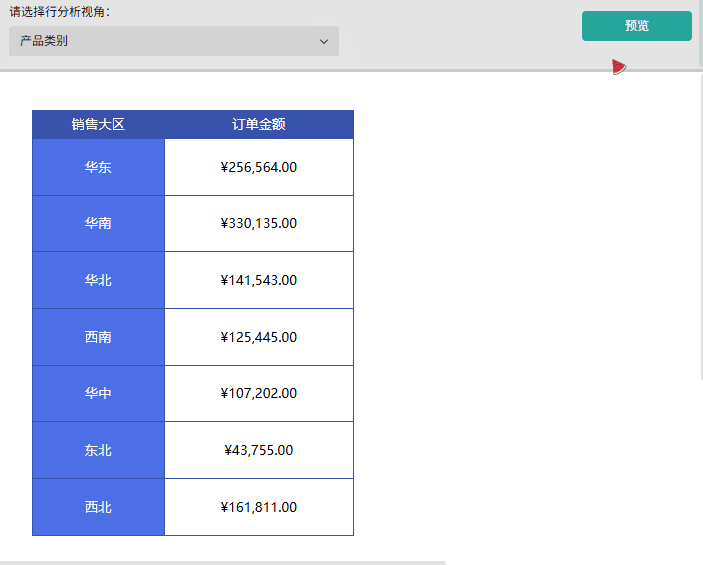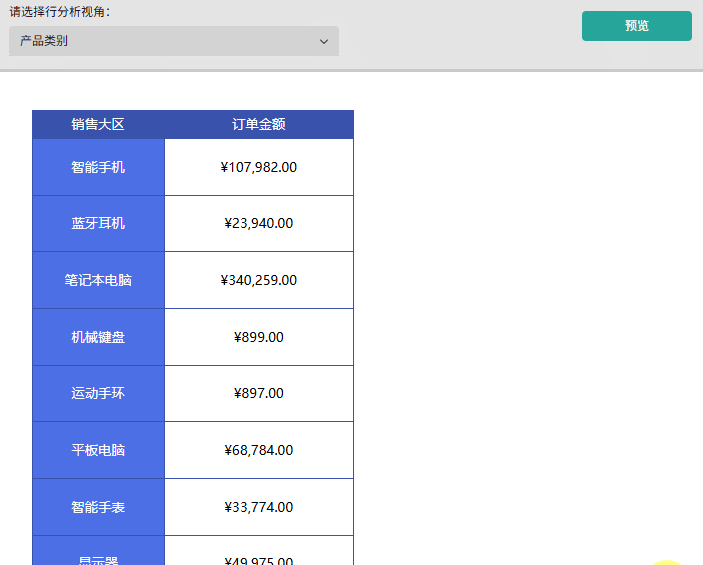
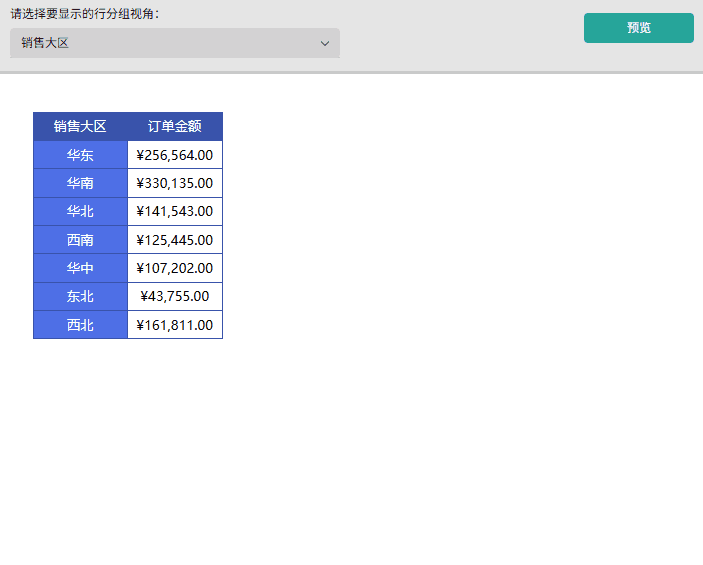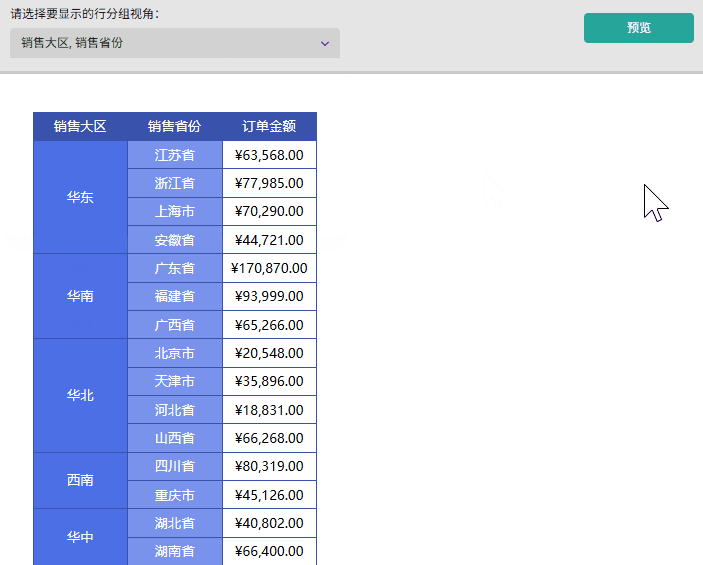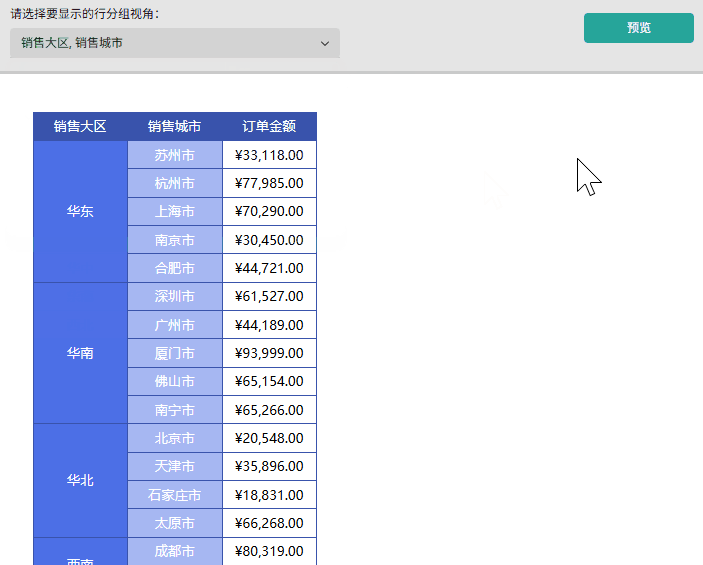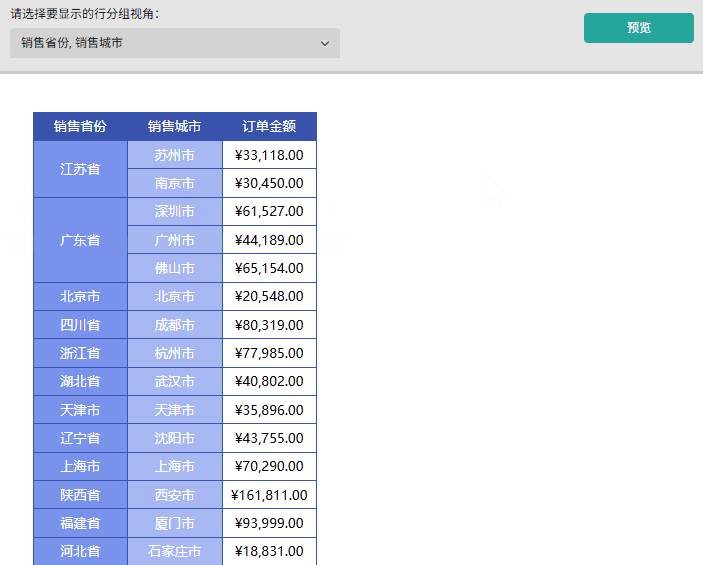
场景一: 动态切换行分析视角,快速查看各地区或各产品的销售情况。
实现步骤(以行分组为例):
- 数据准备:根据实际需求连接对应的数据源。
- **报表设计:**分析需求后,需使用矩表组件+参数。
- 创建单值参数(行分析视角)并设置可用数据为「地区」和「产品类别」。
- 在报表设计器中选择矩表组件并绑定对应数据源的字段,如行分组先绑定销售大区,数值绑定订单金额。
- **配置动态展示(核心步骤):**通过表达式实现行分组的分组条件与矩表数据展示和行分析视角参数有关联。
- 行分组动态条件:选中销售大区单元格,在右侧分组属性面板修改分组条件为:{IIF(@行分析视角 = "地区", 销售大区, 产品名称)},表达式含义:动态切换行分组条件,当参数值为"地区"时使用销售大区作为分组条件,否则使用产品名称作为分组条件。
- 行分组单元格动态显示:选中销售大区单元格,在右侧文本框属性面板修改数据属性为: {IIF(@行分析视角 = "地区", 销售大区, 产品名称)},表达式含义:动态显示行分组维度,当参数值为地区时显示销售大区,否则显示产品名称。
- 为展示直观,使用IIF表达式将订单金额空值显示为"-",并设置货币格式。
- 成果展示:预览报表,通过下拉行分析视角参数切换「地区」或「产品类别」,可观察到行分组维度实时响应参数变化,且数据内容同步更新。
![]()
场景二: 灵活查看「销售大区」、「销售省份」和「销售城市」的层级销售对比,支持任意组合显示。
实现步骤(以多级行分组为例):
- 准备数据:跟据实际需求连接对应的数据源。
- **报表设计:**分析需求后,需使用矩表组件+参数
- 创建多值参数(行分组视角)并设置参数的可选值为「销售大区」、「销售省份」和「销售城市」。
2)在报表设计器中选择矩表组件并绑定对应数据源的字段,如行分组分别绑定销售大区、销售省份和销售城市,数值绑定订单金额。
- **配置动态展示(核心步骤):**通过表达式实现行分组的分组条件与对应列的显示和行分析视角参数有关联。
- 动态显示列:以销售大区列为例,选中销售大区列,在右侧属性列面板中设置隐藏属性表达式为:{IIF(IndexOf(@行分组视角, "销售大区") >= 0, false, true)},其含义是:动态切换列的隐藏与显示,当参数值包含销售大区即显示销售大区对应列,否则隐藏列。
- 行分组动态条件:选中销售大区单元格,在右侧分组属性面板中修改分组条件为:{IIF(IndexOf(@行分组视角, "销售大区") < 0, 1, 销售大区)},其含义是:动态切换行分组,当参数值包含销售大区时,使用销售大区字段做为分组条件,否则使用1作为分组条件,此时所有值都会归于同一组。
3)为展示直观,使用IIF表达式将订单金额空值显示为"-",并设置货币格式。
- 成果展示:预览报表,通过下拉行分组视角参数切换「销售大区」、「产品省份」和「销售城市」,可观察到行分组维度和对应列均会实时响应参数变化,且数据内容同步更新,准确呈现对应维度的汇总结果。
![]()
本文演示虽以行分组为例,但其原理构成了一套完整的技术引擎,可无缝扩展至列分组及更复杂的多维分析场景。参数化动态分组的真正价值,在于它提供了一种可复用的技术架构,推动数据分析从"固定产出"的陈旧模式,迈向"灵活探索"的智能新时代。
扩展链接
AI对话分析,让数据会说话