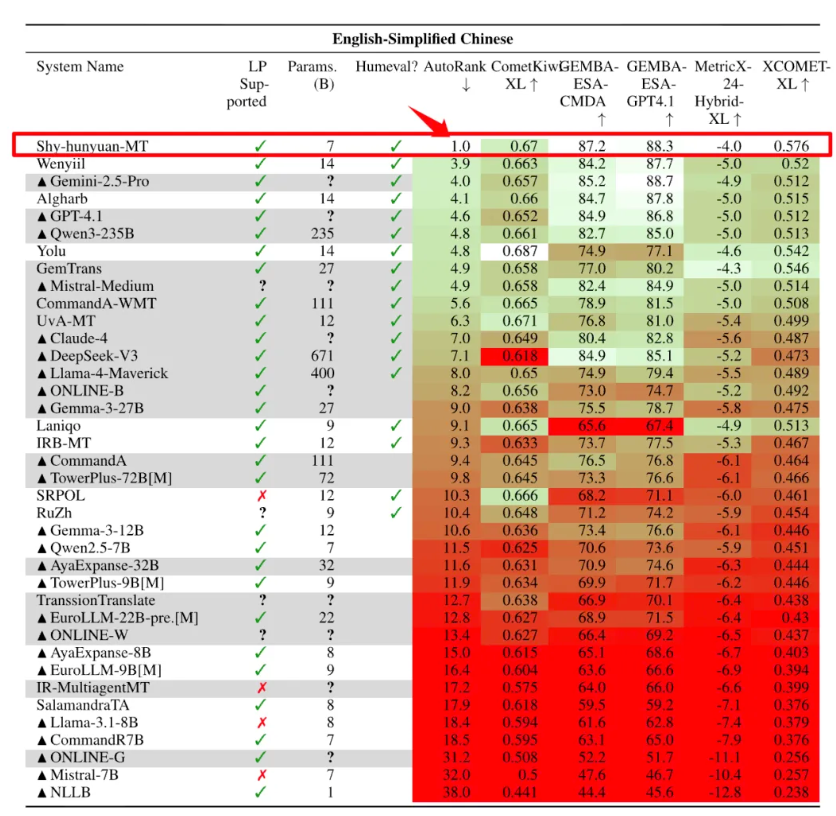
腾讯宣布开源在国际机器翻译比赛拿下30个第1名的翻译模型 Hunyuan-MT-7B,除了中文、英语、日语等常见语种,也包含捷克语、马拉地语、爱沙尼亚语、冰岛语等小语种。
Hunyuan-MT-7B 总参数量仅7B,支持33个语种、5种民汉语言/方言互译,是一个能力全面的轻量级翻译模型。
![]()
同时开源的还有一个翻译集成模型 Hunyuan-MT-Chimera-7B (奇美拉),是业界首个翻译集成模型,它能够根据原文和多个翻译模型给出的不同内容,再生成一个更优的翻译结果,不仅原生支持Hunyuan-MT-7B,也支持接入 deepseek 等模型,对于一些有专业翻译需求的用户和场景,可以提供更加准确的回复。
公告称,在业界常用的翻译能力测评数据集 Flores200上,腾讯混元Hunyuan-MT-7B模型也有卓越的效果表现,明显领先于同尺寸模型,与超大尺寸模型效果对比也不逊色。
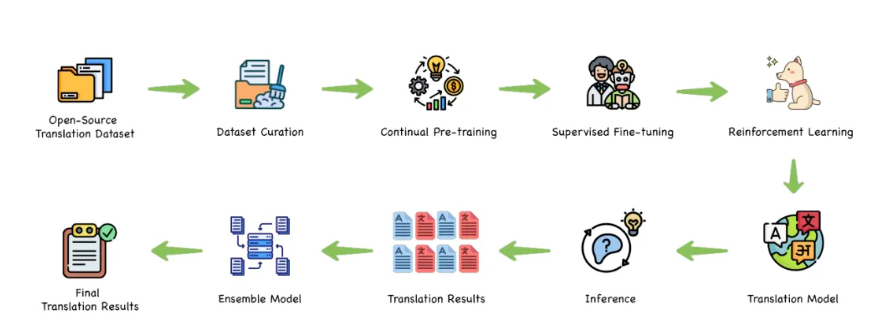
取得全面领先的成绩,离不开技术上的全面突破,针对翻译场景,腾讯混元提出了一个完整的翻译模型训练范式,覆盖从预训练、到CPT再到监督调参、翻译强化和集成强化全链条,使得模型的翻译效果达到业界最优。
![]()
Hunyuan-MT-7B的特点在于仅用少量的参数,就达到甚至超过了更大规模模型的效果,这也为模型的应用带来了众多优势。
首先是计算效率,7B模型的推理速度明显快于大型模型,在相同硬件条件下能够处理更多的翻译请求,并且,基于腾讯自研的AngelSlim大模型压缩工具对Hunyuan-MT-7B进行FP8量化压缩,推理性能进一步提升30%。
其次是部署友好性,Hunyuan-MT-7B能够在更多样化的硬件环境中部署,从高端服务器到边缘设备都能良好运行,并且模型的部署成本、运行成本和维护成本都相对更低,在保证翻译质量的前提下,为企业和开发者提供了更具吸引力的解决方案。
目前,腾讯混元翻译模型已经接入腾讯多个业务,包括腾讯会议、企业微信、QQ浏览器、翻译君翻译、腾讯海外客服翻译等,助力产品体验提升。