美团正式发布 LongCat-Flash-Chat,并同步开源。LongCat-Flash 采用创新性混合专家模型(Mixture-of-Experts, MoE)架构,总参数 560 B,激活参数 18.6B~31.3B(平均 27B),实现了计算效率与性能的双重优化。
基准测试评估表明,作为一款非思考型基础模型,LongCat-Flash-Chat 在仅激活少量参数的前提下,性能比肩当下领先的主流模型,尤其在智能体任务中具备突出优势。并且,因为面向推理效率的设计和创新,LongCat-Flash-Chat 具有明显更快的推理速度,更适合于耗时较长的复杂智能体应用。
技术亮点
LongCat-Flash 模型在架构层面引入“零计算专家(Zero-Computation Experts)”机制,总参数量 560 B,每个token 依据上下文需求仅激活 18.6B~31.3 B 参数,实现算力按需分配和高效利用。为控制总算力消耗,训练过程采用 PID 控制器实时微调专家偏置,将单 token 平均激活量稳定在约 27 B。
此外,LongCat-Flash 在层间铺设跨层通道,使 MoE 的通信和计算能很大程度上并行,极大提高了训练和推理效率。配合定制化的底层优化,LongCat-Flash 在 30 天内完成高效训练,并在 H800 上实现单用户 100+ tokens/s 的推理速度。LongCat-Flash 还对常用大模型组件和训练方式进行了改进,使用了超参迁移和模型层叠加的方式进行训练,并结合了多项策略保证训练稳定性,使得训练全程高效且顺利。
针对智能体(Agentic)能力,LongCat-Flash 自建了Agentic评测集指导数据策略,并在训练全流程进行了全面的优化,包括使用多智能体方法生成多样化高质量的轨迹数据等,实现了优异的智能体能力。
通过算法和工程层面的联合设计,LongCat-Flash 在理论上的成本和速度都大幅领先行业同等规模、甚至规模更小的模型;通过系统优化,LongCat-Flash 在 H800 上达成了 100 tokens/s 的生成速度,在保持极致生成速度的同时,输出成本低至 5元/百万 token。
性能评估
![]()
-
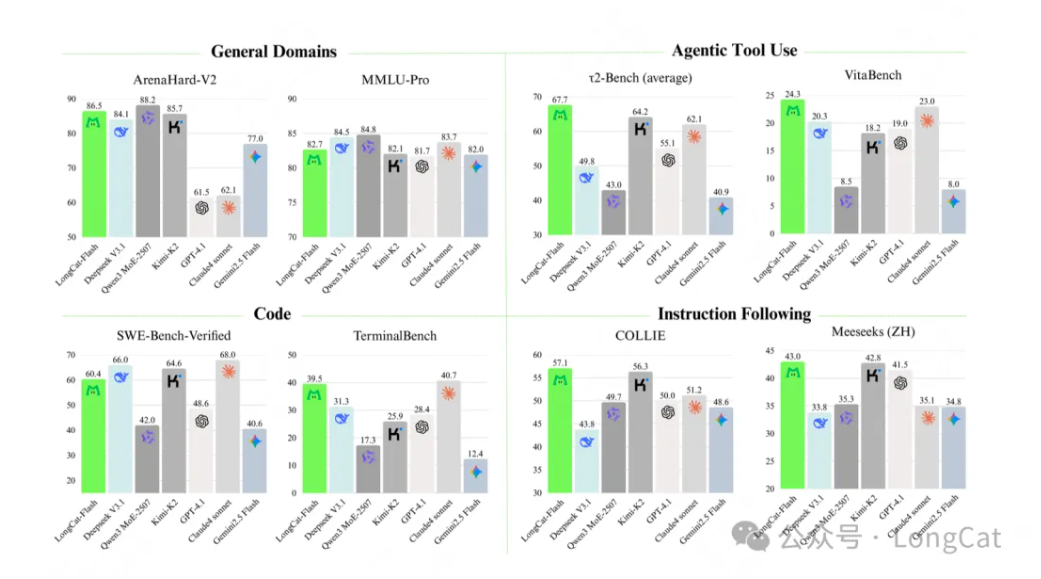
在通用领域知识方面,LongCat-Flash 表现出强劲且全面的性能:在 ArenaHard-V2 基准测试中取得 86.50 的优异成绩,位列所有评估模型中的第二名,充分体现了其在高难度“一对一”对比中的稳健实力。在基础基准测试中仍保持高竞争力,MMLU(多任务语言理解基准)得分为 89.71,CEval(中文通用能力评估基准)得分为 90.44。这些成绩可与目前国内领先的模型比肩,且其参数规模少于 DeepSeek-V3.1、Kimi-K2 等产品,体现出较高的效率。
-
在智能体(Agentic)工具使用方面,LongCat-Flash 展现出明显优势:即便与参数规模更大的模型相比,其在 τ2-Bench(智能体工具使用基准)中的表现仍超越其他模型;在高复杂度场景下,该模型在 VitaBench(复杂场景智能体基准)中以 24.30 的得分位列第一,彰显出在复杂场景中的强大处理能力。
-
在编程方面,LongCat-Flash 展现出扎实的实力:其在 TerminalBench(终端命令行任务基准)中,以 39.51 的得分位列第二,体现出在实际智能体命令行任务中的出色熟练度;在 SWE-Bench-Verified(软件工程师能力验证基准)中得分为 60.4,具备较强竞争力。
-
在指令遵循方面,LongCat-Flash 优势显著:在 IFEval(指令遵循评估基准)中以 89.65 的得分位列第一,展现出在遵循复杂且细致指令时的卓越可靠性;此外,在 COLLIE(中文指令遵循基准)和 Meeseeks-zh(中文多场景指令基准)中也斩获最佳成绩,分别为 57.10 和 43.03,凸显其在中英文两类不同语言、不同高难度指令集上的出色驾驭能力。
模型部署
同步提供了分别基于 SGLang 和 vLLM 的两种高效部署方案。以下为使用SGLang进行单机部署的示例:
python3 -m sglang.launch_server \ --model meituan-longcat/LongCat-Flash-Chat-FP8 \ --trust-remote-code \ --attention-backend flashinfer \ --enable-ep-moe \ --tp 8