EXCEL导入—设计与思考
一、案例信息与设计
1.1、案例需求与背景
B2BTC同城二期有一个Excel导入的功能,单次数据量小于一千,使用频次不高。但涉及到多个字段组成唯一约束,即每条数据操作时要根据唯一性组合字段来操作,要确保数据表中的数据不违反唯一性。
每条数据涉及到多次查询其他业务RPC来校验、补充信息的诉求,即使有缓存,但也可能涉及到缓存不命中问题,即单条数据的校验和导入的时效性保障不了。
1.2、整体解决方案
以下四个方案为开发过程中依次思考的四个方案,没有绝对利弊。
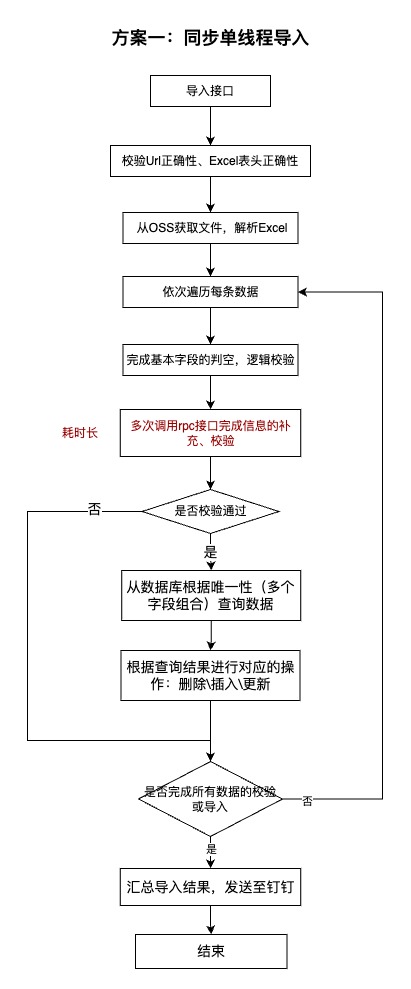
1.2.1、初始构思开发方案(同步导入)
首先想到的方案为常用的同步导入,即在一台容器的一个线程中完成Excel中数据的解析、校验、导入、发送通知消息三部分流程。
问题:
1.当数据量过大时,在单台服务器上操作时对服务器造成比较大的内存压力。
2.流程比较长,每条数据涉及多次RPC查询,总体时间很长。接口TP99会比较高 + 用户体验很差。
优点:
1.可以让前端同步获取导入结果。
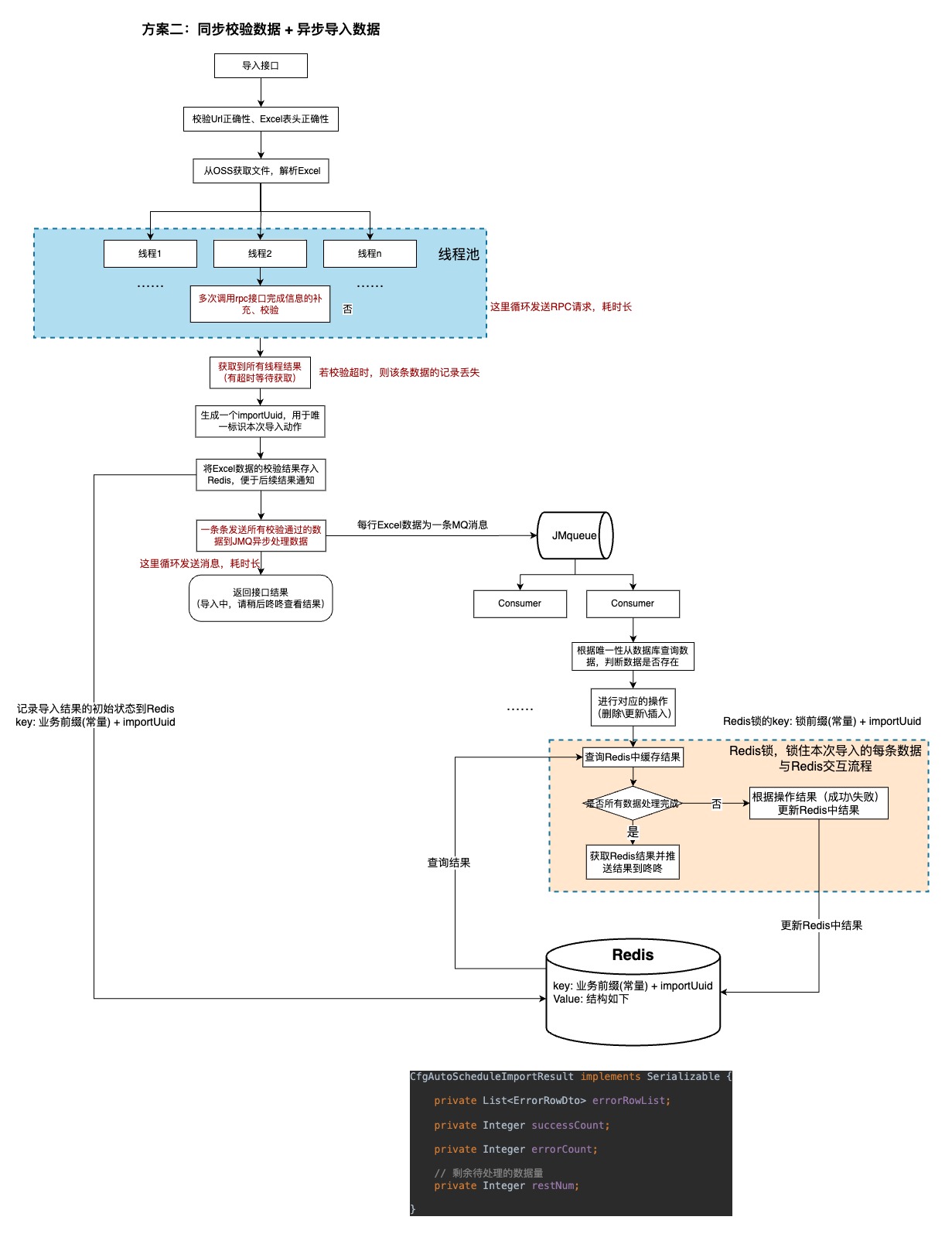
1.2.2、方案二(改进版)
由于方案一时效不可控制,在参考了另外一个Excel导入场景后设计了以下方案:
基于原有的方案,该方案使用了线程池来校验数据并通过MQ来异步地处理每条数据,这样基于原有的方案有一定的效率提升。
但由于当时思考不充分,开发完成之后发现和实际场景不适配,并可能有TP99超时风险,只作为记录。
问题:
1.业务可以结束完全的异步,所有的导入结果都通过。
优点:
1.可以让前端同步获取校验结果。
2.线程池和异步处理一定程度上提升了数据处理效率。
适用场景:
本方案适用于前端需要同步获取导入的结果,后端不涉及唯一性校验(有单号等唯一主键信息)的场景,可以校验数据之后进行批量插入(不用MQ来发消息异步处理数据)。
方案本身没有什么问题,问题在于方案和引用场景不是最佳适配:本次导入不要求前端能即时获取到导入的结果,因此无需在这里同步获取到结果之后再异步处理数据,可以将 excel解析 + 数据校验 + 处理消息统一均异步处理。
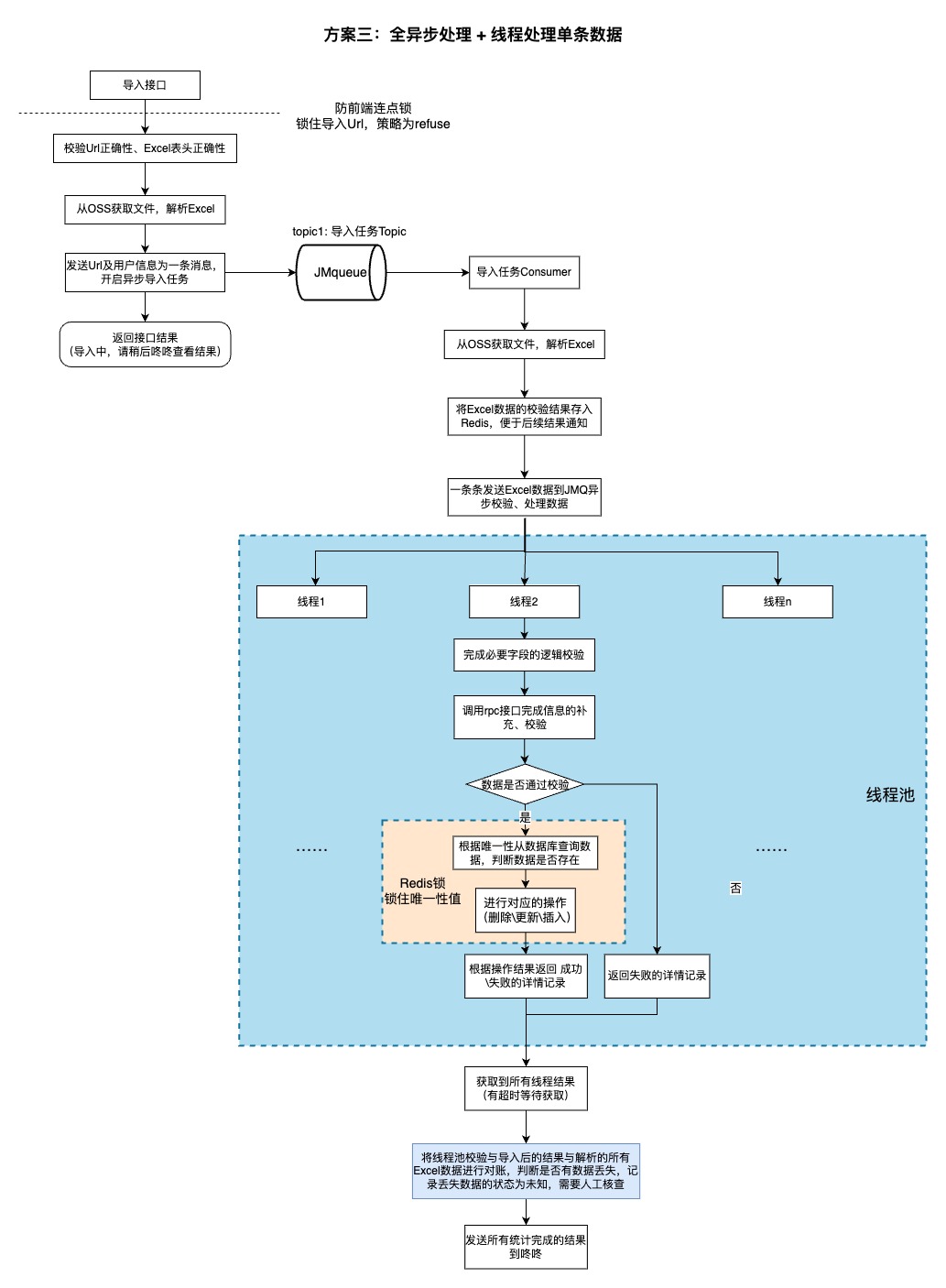
1.2.3、方案三(最终版)
由于业务方没有同步获取导入结果或者校验结果的任何诉求,因此这里将 excel解析 + 数据校验 + 处理消息统一均异步处理(JMQ发消息给消费者来处理这些流程),只对必要的参数进行校验。
对于数据处理,将Excel数据拆分为每条的粒度,用 线程池来进行 数据校验并处理,最终由主线程统计结果。
此外,在进行数据 查询唯一性数据 + 操作数据(增加\删除\修改) 的最小并发影响粒度加上Redis锁来保障数据表的唯一性不会被破坏。
问题:
1.所有的 excel解析 + 数据校验 + 处理消息 均在一台服务器上执行,对服务器的压力会比较大。
优点:
1.用线程池处理消息,大大缩短了消息处理的时间,减少了单个服务器压力。
2.有兜底策略,可确保数据不丢失,导入流程可以正常且按时结束,不会无上限等待。
3.除必要校验的所有流程均异步处理,接口的TP99可靠且较快。
适用场景:
1.对数据完整性要求比较的业务。
2.数据量不会太大的业务。(避免对单个容器造成较大压力)
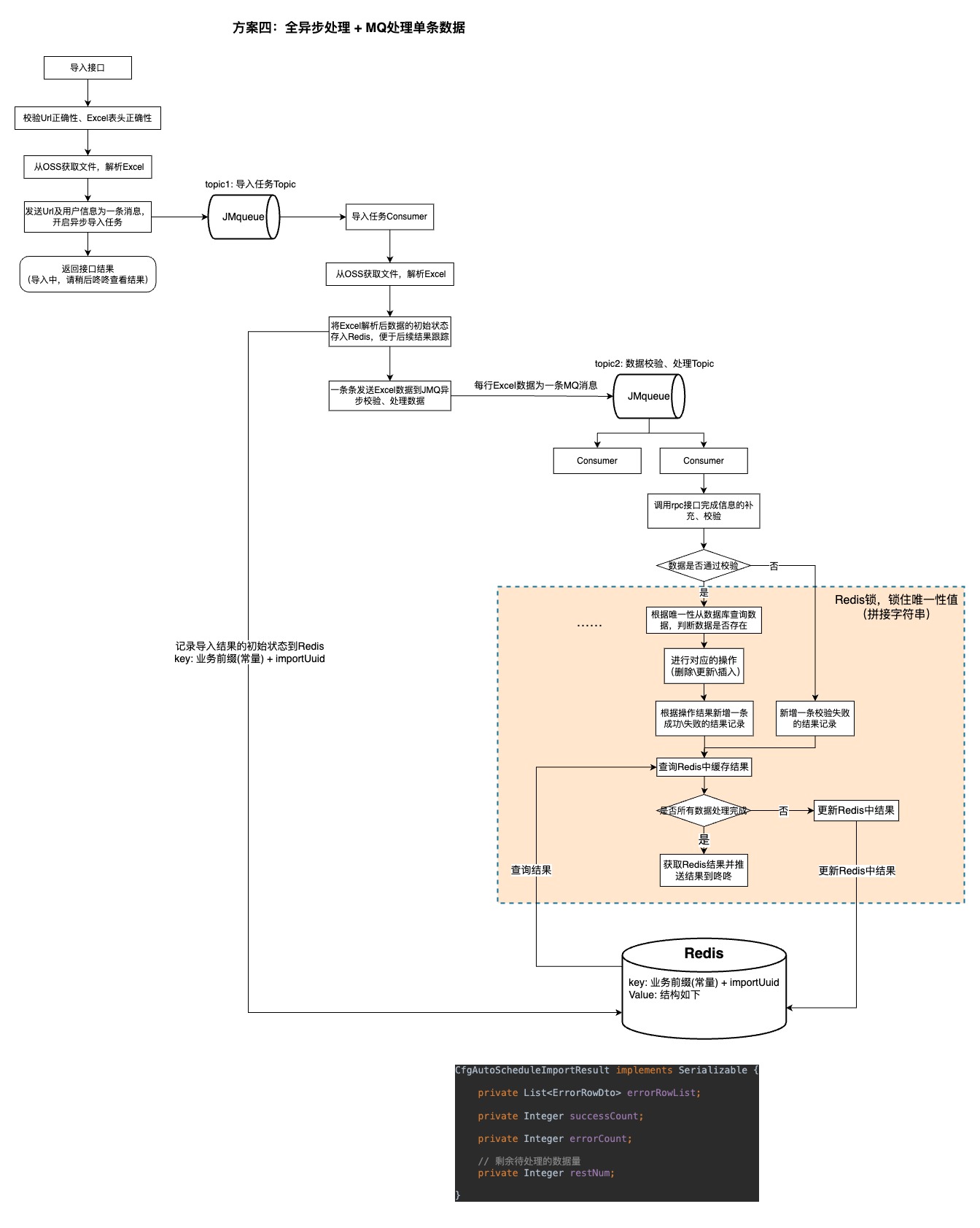
1.2.4、方案四(理想版)
对于方案三,将所有的数据校验 + 处理的流程都给一台服务器执行,造成单台服务器压力比较大,且并发度不够高,总体流程时效性可能得不到保障。因此设想了一个较为理想的方案四场景,适用于数据量大、对数据可靠性要求不高、时效性要求高的场景。
相比方案三,方案四减少了对应的对账、兜底机制,整体的流程还是异步进行。相比于线程池,用 JMQ 发送消息给 数据校验并处理的consumer来处理消息并记录结果到Redis来跟踪导入进度。此外,在进行数据 查询唯一性数据 + 操作数据(增加\删除\修改)+ 更新Redis中最终结果 的最小并发影响粒度加上Redis锁来保障数据表的唯一性不会被破坏。
问题:
1.没有兜底策略,数据校验处理的流程中可能出现有一条消息阻塞\丢失\意外结束,导致最终没有线程统计结果并发送咚咚消息。
优点:
1.除必要校验的所有流程均异步处理,接口的TP99可靠且较快。
2.利用拆分导入数据 + 多个Consumer处理消息,大大缩短了消息处理的时间。
3.拆分数据为消息异步处理,用了JMQ的重试机制来提升了数据处理的可靠性。
适用场景:
1.本方案适用于前端无需同步获取导入的结果,后端可以完全异步处理数据的场景。
2.对数据可靠性要求不是极高的业务,可接受小概率容错。
3.对导入结果失效有一定诉求的业务。
4.数据量比较大或操作比较频繁的业务。
二、持续思考
2.1 中间件的合理使用
合理利用JMQ来解耦、拆分业务逻辑可以 减少单台服务器实例内存或CPU的压力、提高数据处理并发量,同时可以利用MQ的重试机制来尽可能保障对应业务的可用性。
同时,异步处理可能存在结果丢失的情况,在数据可靠性要求不高的场景可以合理舍弃这种小概率场景发生的问题(因为有重试还一直失败)。但在数据可靠性要求比较高的场景,需要有对应的对账机制 + 兜底机制来统计数据的处理情况。(如Excel导入,可以将解析完成的数据 和 最终导入的数据进行一个数据对账,如果有数据丢失或者无响应,发出告警,让定时任务 或 人工进行二次核验来确保数据可靠不丢失)
但中间件的过度使用使得服务过度依赖中间件的可靠性,问题追踪定位难度会进一步加大,需要结合实际业务场景综合权衡。
2.2 业务充分适配场景
在进行方案的技术设计时,不要只是照葫芦画瓢,要结合自己的业务场景、业务数据量、可靠性要求等场景充分考虑,借鉴其他方案的可用之处。
如本文档中方案二借鉴了之前的方案设计,但没有考虑自己的业务场景是不是与其适配,没有充分适配自己的实际业务,还可能引入新的问题。
没有最好的技术方案,只有适配于当前业务场景的最佳方案。