阿里巴巴通义实验室宣布正式开源其首款音频生成模型ThinkSound,将 CoT(Chain-of-Thought,思维链)应用到音频生成领域,让 AI 学会一步步“想清楚”画面事件与声音之间的关系,从而实现高保真、强同步的空间音频生成——不只是“看图配音”,而是真正“听懂画面”。
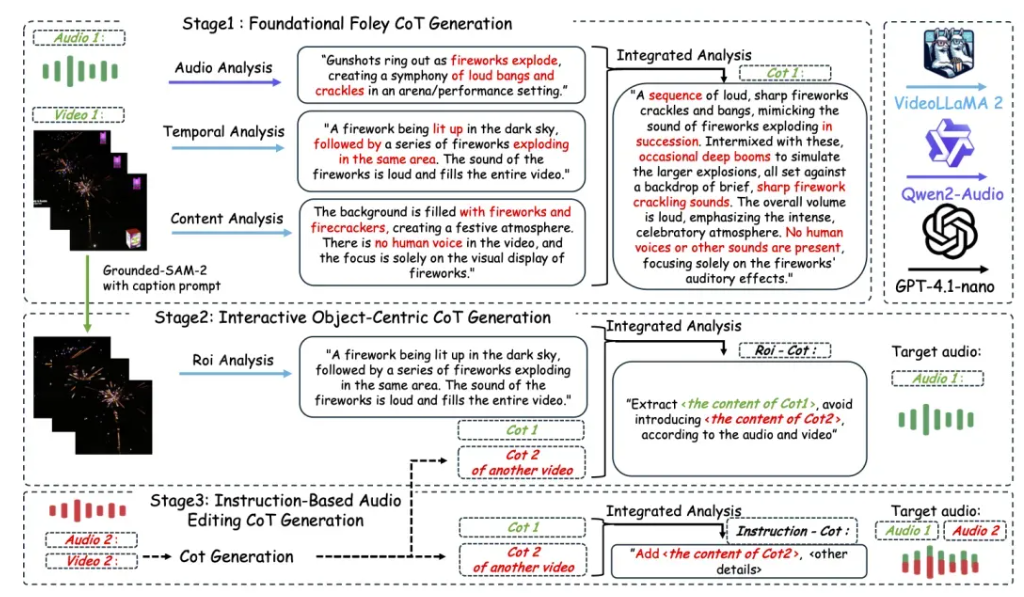
根据介绍,为了让 AI 学会“有逻辑地听”,通义实验室语音团队构建了首个支持链式推理的多模态音频数据集 AudioCoT。
AudioCoT 融合了来自 VGGSound、AudioSet、AudioCaps、Freesound 等多个来源的 2531.8 小时高质量样本。这些数据覆盖了从动物鸣叫、机械运转到环境音效等多种真实场景,为模型提供了丰富而多样化的训练基础。为了确保每条数据都能真正支撑 AI 的结构化推理能力,研究团队设计了一套精细化的数据筛选流程,包括多阶段自动化质量过滤和不少于 5% 的人工抽样校验,层层把关以保障数据集的整体质量。
在此基础上,AudioCoT 还特别设计了面向交互式编辑的对象级和指令级样本,以满足 ThinkSound 在后续阶段对细化与编辑功能的需求。
![]()
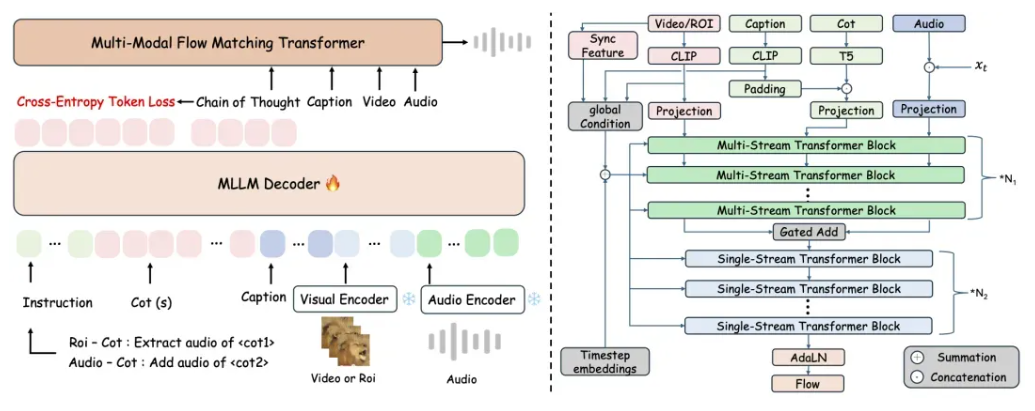
ThinkSound 由两个关键部分组成:一个擅长“思考”的多模态大语言模型(MLLM),以及一个专注于“听觉输出”的统一音频生成模型。正是这两个模块的配合,使得系统可以按照三个阶段逐步解析画面内容,并最终生成精准对位的音频效果——从理解整体画面,到聚焦具体物体,再到响应用户指令。
下图展示了 ThinkSound 的完整技术架构,包括多模态大语言模型和基于流匹配的统一音频生成模型的工作流程。
![]()
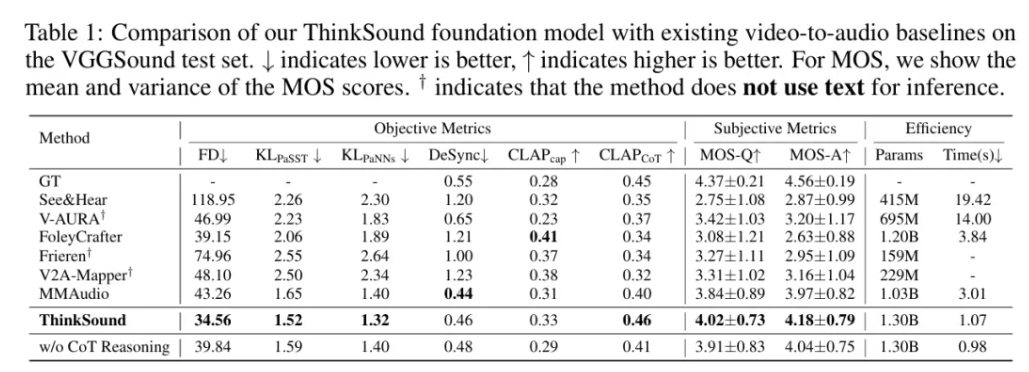
测试结果表明,在 VGGSound 测试集上,ThinkSound的核心指标相比 MMAudio、V2A-Mappe、V-AURA 等现有主流方法均实现了 15% 以上的提升。例如,在 openl3 空间中 Fréchet 距离(FD)上,ThinkSound 相比 MMAudio 的 43.26 降至 34.56(越低越好),接近真实音频分布的相似度提高了 20% 以上;在代表模型对声音事件类别和特征判别精准度的KLPaSST 和 KLPaNNs两项指标上分别取得了 1.52 和 1.32 的成绩,均为同类模型最佳。
![]()
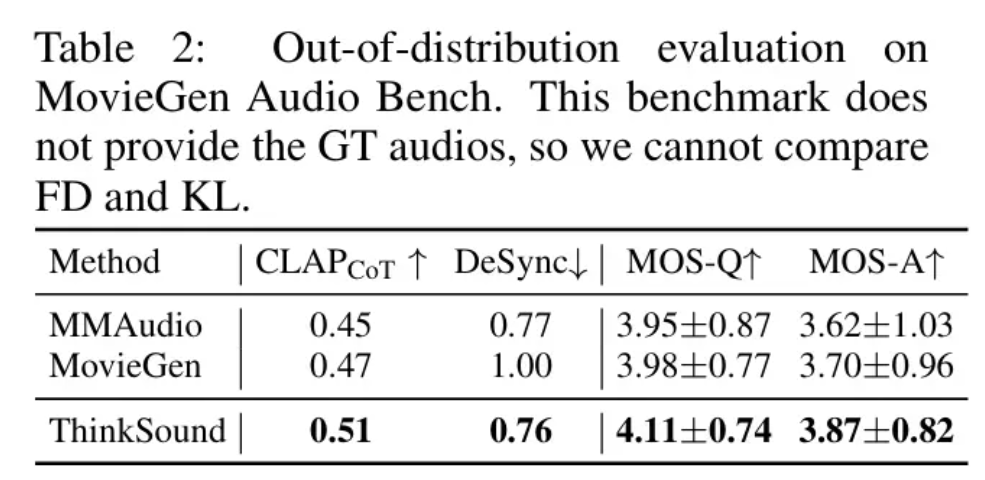
在 MovieGen Audio Bench 测试集上,ThinkSound 的表现大幅领先 Meta 推出的音频生成模型 MovieGenAudio。
![]()
接下来,ThinkSound 计划在模型能力、数据构建和应用场景三大方向持续拓展:包括提升推理精度、增强对复杂声学环境的理解、集成更多模态数据以提高泛化能力,并逐步向游戏开发、虚拟现实(VR)、增强现实(AR)等沉浸式交互场景延伸,为大家带来更丰富的声音体验。