大家好呀!这里是你们的课代表懒懒~
RAG 课程进入高阶阶段啦📚!前面我们已经掌握了如何构建一个功能完备、性能强悍的RAG系统,但当RAG真正走进企业生产环境,还需要应对两个更现实的问题:
🙋♀️如何保障数据安全、权限可控,满足企业内部复杂的管理要求?
🙋♂️如何突破传统RAG的“单线程思维”,让多个智能体协同合作,共同完成复杂任务?
别急,这两讲,我们来一一攻克!
企业级RAG,做“可控”的RAG系统!
相比个人项目,企业级RAG的系统搭建面临更严苛的挑战。权限管理、数据隔离、共享机制、信息安全样样都不能少。
这节课我们从企业的真实业务需求出发,总结出企业级RAG的三大核心痛点,并用 LazyLLM 提供的机制逐个击破👇
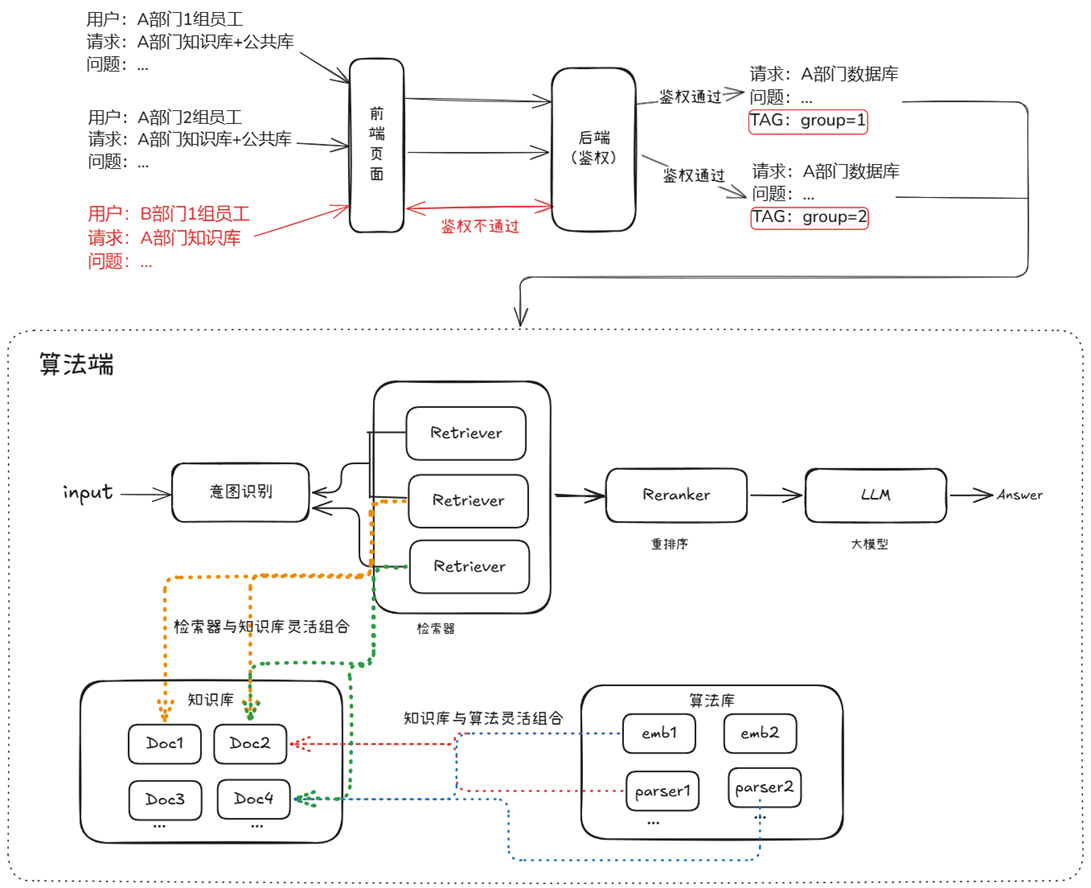
权限机制:从文件分组到权限注入,RAG如何控“谁能看”
在企业中,知识不是“谁想看就能看”的公共资源,而是必须具备访问边界、隔离机制与安全标签的内部资产。
这一节,我们重点讲解如何在 LazyLLM 中实现企业级权限管理能力,从“部门隔离”到“精细化访问控制”,帮你搞定复杂组织下的RAG系统权限策略!
支持多部门独立知识运营
企业中的文档通常分布在多个部门、团队或项目中,常见挑战包括:
- 如何高频更新各部门文档,保持知识库同步?
- 同一份文档被多个部门使用,是否要重复上传?
- 如何避免跨部门访问,确保敏感内容不外泄?
LazyLLM 提供了灵活的文档管理服务,通过 UI 或 API 即可完成文档的增删改查、实时检索与多分组管理:
from lazyllm.tools import Document
docs = Document("path/to/docs", manager='ui') # 启用文档管理界面
Document(path, name='法务文档组', manager=docs.manager)
Document(path, name='产品文档组', manager=docs.manager)
docs.start()
启动后将生成一个可视化界面,展示每个管理组的文档结构,支持在线上传、删除与修改。
![]()
权限细粒度控制:标签驱动 + 动态筛选
不同岗位、团队、项目成员的权限不一样,LazyLLM 提供了基于标签的权限控制机制,实现文档级访问控制:
上传文档时打标签(Metadata)
CUSTOM_DOC_FIELDS = {
"department": DocField(data_type=DataType.VARCHAR),
"permission_level": DocField(data_type=DataType.INT32, default_value=1)
}
上传文档同时标记权限等级:
files = [('files', ('普通文档.pdf', io.BytesIO(...)),
('files', ('敏感文档.pdf', io.BytesIO(...))]
metadatas=[{"department": "法务一部", "permisssion_level": 1},
{"department": "法务一部", "permisssion_level": 2}]))
📌 实现内容分类 + 安全等级绑定
检索时使用过滤条件(Filter)
nodes = retriever(query, filters={'department': ['法务一部'], "permission_level": [1,2]} )
📌 同一知识库中可按需“查自己能看的”,实现安全隔离。
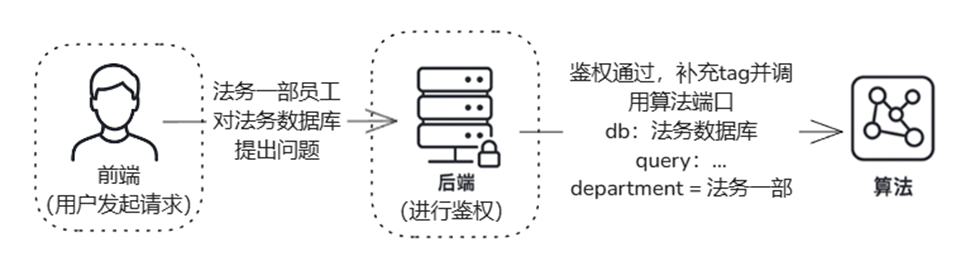
后端统一鉴权机制
在生产部署中,推荐将权限管理逻辑全部交由后端集中控制,而非由算法侧处理:
![]()
- 用户登录态决定其 filter 权限范围
- 检索模块仅调用带有 filter 的接口,不处理权限判断
- 保障安全、避免绕过、便于审计
多知识源统一检索:一库多召回,跨库协作不冲突
除了权限控制,企业在知识共享方面也面临多样化需求:一方面,不同团队间常需共享算法资源以提升复用效率;另一方面,多个部门之间也存在知识库交叉使用的需求,支持多对多的知识复用关系。这些场景对灵活的共享机制提出了更高要求。
共享灵活性:支持多源知识与算法自由适配
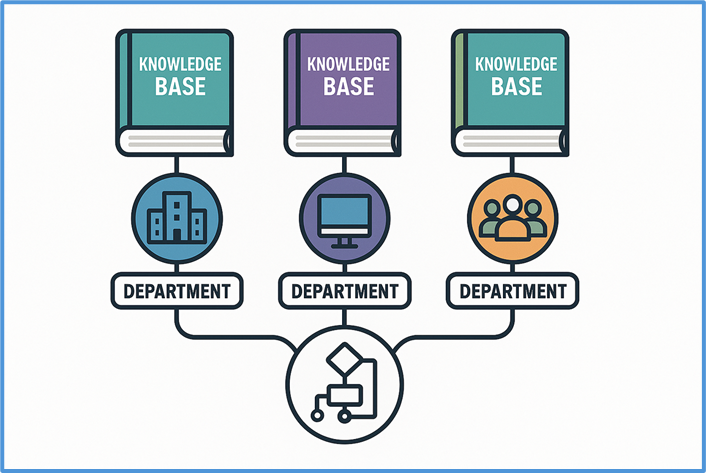
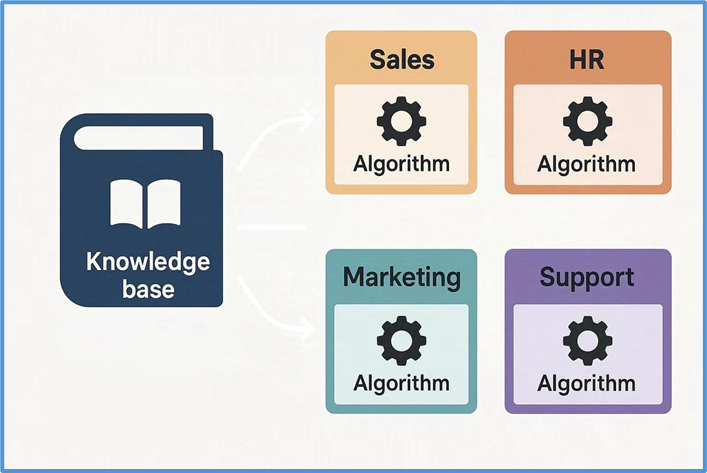
在企业中,各部门业务领域不同,存在两种情况。即 “一算法对多知识库” 和 “多算法对一知识库” 两种需求,系统需同时支持以适配业务。
![]()
📈 以金融公司为例,风控与市场分析部门或共用文本解析和嵌入算法预处理数据,前者知识库含历史交易与客户信用记录,后者含市场动态与竞品情报,系统需支持算法在不同知识库复用。
![]()
☕ 以电商企业为例,推荐系统与搜索优化部门分别用协同过滤嵌入、词向量相似度排序算法处理同一用户行为数据集,系统需支持在同一知识库独立运行不同算法以生成针对性结果。
同一套算法在多个知识库中的应用场景已在前面权限的部分讨论过。 接下来,我们实现在同一知识库中,通过不同文档分组实现算法多样化的场景。
为同一知识库注册分组,并模拟上传两篇文档:
docs = Document(path, manager=True, embed=OnlineEmbeddingModule())
# 注册分组
Document(path, name='法务文档管理组', manager=docs.manager)
Document(path, name='产品文档管理组', manager=docs.manager)
# 模拟文档上传
docs.start()�files = [('files', ('产品文档.txt', io.BytesIO("这是关于产品的信息。该文档由产品部编写。\n来自产品文档管理组".encode("utf-8")), 'text/plain'))]�files = [('files', ('法务文档.txt', io.BytesIO("这是关于法律事务的说明。该文档由法务部整理。\n来自法务文档管理组".encode("utf-8")), 'text/plain'))]
为同一知识库的不同文档组,分别定义不同的切分算法:
# 为 产品文档管理组 设置切分方式为按 段落 切分
doc1 = Document(path, name=‘产品文档管理组', manager=docs.manager)
doc1.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
retriever1 = Retriever([doc1], group_name="block", similarity="cosine", topk=3)
�# 为 法务文档管理组 设置切分方式为按 句子 切分
doc2 = Document(path, name=‘法务文档管理组’, manager=docs.manager)
doc2.create_node_group(name=“line”, transform=lambda s: s.split(“。") if s else ‘’)
retriever2 = Retriever([doc2], group_name="line", similarity="cosine", topk=3)
召回解耦:支持知识库与召回服务灵活协同
为应对复杂的知识共享与复用需求,企业越来越需要灵活而高效的知识组织结构与管理能力:
- 需要多对多的知识组织结构
- 需要多业务场景的知识复用能力
为满足上述需求,LazyLLM不仅提供灵活的文档管理模块,还将文档管理与 RAG 召回服务进行完全解耦,来满足企业知识管理和召回需求的多样性,这样做的好处具体体现在:
- 多对多管理模式:一个文档管理服务可以同时管理多个知识库,支持不同业务部门的知识存储需求。
- 多 RAG 适配:同一个知识库可以适用于多个 RAG 召回服务,一个 RAG 召回服务可以从多个知识库中检索数据。
得益于这种解耦设计,确保了企业能够在不同业务场景下,动态调整知识库和 RAG 召回服务的绑定关系,满足个性化的知识管理需求。
![]()
具体实现起来,仅需以下两步骤,可搭建多知识库管理和召回流程。
步骤一:初始化知识库
from lazyllm.tools import Document
from lazyllm import OnlineEmbeddingModule
import time
# =============================
# 方法1.通过定义路径的方式
# =============================
law_data_path = "path/to/docs/law"
product_data_path = "path/to/docs/product"
support_data_path = "path/to/docs/support"
law_knowledge_base = Document(law_data_path, name='法务知识库',embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
product_knowledge_base = Document(product_data_path,name='产品知识库',embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
support_knowledge_base = Document(support_data_path,name='客户服务知识库',embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
# =============================
# 方法2.通过文档上传方式
# =============================
data_path = "path/to/docs"
law_knowledge_base = Document(data_path, name='法务知识库', manager="ui",embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
# 通过法务知识库的 manager 共享管理器
product_knowledge_base = Document(
data_path,
name='产品知识库',
manager=law_knowledge_base.manager,
)
law_knowledge_base.start()
步骤二:启用 RAG 召回服务
from lazyllm import Retriever,SentenceSplitter
# 配置和定义数据处理算法, 可根据业务需要自定义
Document.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
# 组合法务 + 产品知识库,处理与产品相关的法律问题
retriever_product = Retriever(
[law_knowledge_base, product_knowledge_base],
group_name="sentences", # 分组名(根据业务需求选择)
similarity="cosine", # 相似度参数(根据模型配置)
topk=2 # 召回前2个最相关的结果
)
product_question = "A产品功能参数和产品合规性声明"
product_res_nodes = retriever_product(product_question)
# 组合法务 + 客户知识库,处理客户支持相关问题
retriever_support = Retriever(
[law_knowledge_base, support_knowledge_base],
group_name="sentences",
similarity="cosine",
topk=2
)
support_question = "客户投诉的处理方式以及会导致的法律问题"
support_res_nodes = retriever_support(support_question)
只需两步,快速搭建支持多知识源联合召回的高可用系统。
对话管理:支持历史记忆 × 多用户并发
一个真正实用的 RAG 系统,不只是“你问我答”,而是能记得住你说过的话、分得清谁在对话、回得上用户的速度。
LazyLLM 提供了强大的 对话管理机制,覆盖从上下文记忆到多用户隔离的全流程。
历史对话管理:让助手“懂上下文”
在用户提出“那苹果呢?”时,系统能自动联想上轮“香蕉的英文是什么?”并回复“apple”而不是困惑地问“你说什么苹果?”
这背后的关键,是通过 globals 全局上下文管理器,实现每个用户的独立历史记录维护:
from lazyllm import globals
# 初始化历史记录
def init_session_config(session_id, user_history):
globals._init_sid(session_id)
globals["global_parameters"]["history"] = user_history or DEFAULT_FEW_SHOTS
系统支持:
- ✅ few-shot 示例初始化对话风格
- ✅ 自动记录历史问答并更新
- ✅ 支持上下文汇总、改写等复合任务
📸 示例:
用户1:香蕉的英文?
助手:banana
用户1:那苹果呢?
助手:apple ✅(准确关联历史)
用户2:机器学习是什么?
助手:...(定义)
用户2:它有什么用?
助手:...(回答应用) ✅
多用户隔离:50路并发也不乱
在企业应用中,系统必须支持多个用户同时提问、独立上下文、不卡顿不串线。
LazyLLM 通过线程池 + slot 管理机制,实现:
- 每个会话绑定一个独立 session_id
- 会话上下文
globals 自动隔离
- 使用
@with_session 装饰器确保上下文正确切换
@with_session
def handle_request(session_id: str, user_input: str):
chat = SessionResponder()
for chunk in chat.respond_stream(session_id, user_input):
print(chunk, end='', flush=True)
✔️ 多用户并发对话,历史不混、响应实时,体验如微信聊天般流畅自然。
安全机制:私有部署 × 敏感过滤,全链路护航
RAG 系统要落地企业,安全必须从“选项”变为“底座”。
企业内安全:多重防护,稳如泰山
✅ 数据加密全链路
- 文档存储:支持加密存储,防数据泄漏
- 网络传输:HTTPS + 权限认证
- 模型调用:加密上下文传递,保护隐私数据
✅ 私有化部署支持
- 本地模型推理,不依赖外部API
- 内网封闭部署,确保“数据不出墙”
- 支持角色权限、操作审计
✅ 全信创生态兼容
- 麒麟/统信UOS 操作系统
- 龙芯/鲲鹏 CPU 架构
- 达梦/人大金仓 数据库系统
从“硬件芯片”到“数据库驱动”,全栈国产可替代,合规部署更放心!
公共安全:内容合规,全方位监控
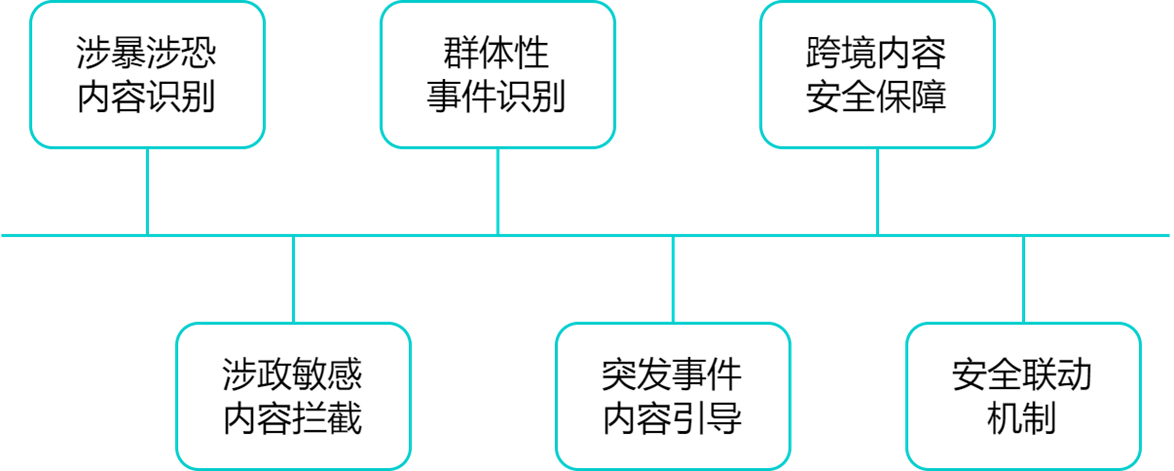
系统生成内容,也需要“守规矩”!LazyLLM 支持公共安全模块,涵盖六大能力:
![]()
👨✈️ 通过公共安全模块的建设,企业可有效防控大模型在生成内容过程中可能引发的社会层面风险,提升企业数字治理能力,践行平台责任。
企业级RAG的总体实现思路
在前文中,我们逐一拆解了企业级RAG在权限控制、知识共享、安全防护、对话记忆、敏感过滤等多个模块的设计难点与解决方案。
现在,是时候将这些“点”连成“线”,构建一个完整、落地可用的 企业级RAG系统架构蓝图。
![]()
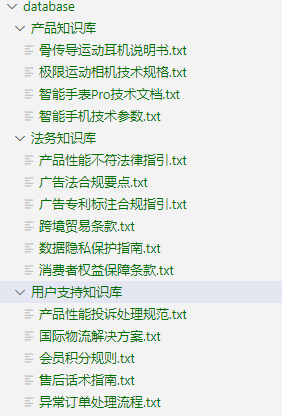
接下来,以一个电商场景为例,我们将构建一个具备上述功能的 RAG 问答系统。本次示例中共使用三个知识库,数据准备如图所示。
![]()
我们将产品知识库与法务知识库联合检索,用于处理产品及法务相关问题;同时将法务知识库与用户支持知识库组合,以应对用户支持类问题。为此,首先构建两条独立的 RAG pipeline。
with pipeline() as product_law_ppl:
product_law_ppl.retriever = retriever = Retriever(
[doc_law, doc_product],
group_name="dfa_filter",
topk=5,
embed_keys=['dense'],
)
product_law_ppl.reranker = Reranker(name="ModuleReranker",
model=OnlineEmbeddingModule(type='rerank'),
topk=2, output_format="content", join=True) | bind(query=product_law_ppl.input)
product_law_ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=product_law_ppl.input)
product_law_ppl.llm = OnlineChatModule().prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
with pipeline() as support_law_ppl:
support_law_ppl.retriever = retriever = Retriever(
[doc_law, doc_support],
group_name="dfa_filter",
topk=5,
embed_keys=['dense'],
)
support_law_ppl.reranker = Reranker(name="ModuleReranker",
model=OnlineEmbeddingModule(type='rerank'),
topk=2, output_format="content", join=True) | bind(query=support_law_ppl.input)
support_law_ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=support_law_ppl.input)
support_law_ppl.llm = OnlineChatModule().prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
为用户提供统一的问答入口,并实现不同知识库间的无缝切换,我们引入了用户意图识别模块,能够根据查询内容自动选择合适的 RAG pipeline 进行处理。
def build_ecommerce_assistant():
llm = OnlineChatModule(source='qwen', stream=False)
intent_list = [
"产品法务问题",
"用户支持问题",
]
with pipeline() as ppl:
ppl.classifier = IntentClassifier(llm, intent_list=intent_list)
with lazyllm.switch(judge_on_full_input=False).bind(_0, ppl.input) as ppl.sw:
ppl.sw.case[intent_list[0], product_law_ppl]
ppl.sw.case[intent_list[1], support_law_ppl]
return ppl
为了实现多用户并发会话请求并维护独立的上下文,我们通过 globals 管理器封装了 EcommerceAssistant,确保用户问答的隔离性。
def init_session(session_id, user_history: Optional[List[ChatHistory]] = None):
globals._init_sid(session_id)
if "global_parameters" not in globals or "history" not in globals["global_parameters"]:
globals["global_parameters"]["history"] = []
if not globals["global_parameters"]["history"]:
# 初始化为 default few-shot
globals["global_parameters"]["history"].extend(DEFAULT_FEW_SHOTS)
if user_history:
for h in user_history:
globals["global_parameters"]["history"].append({"role": "user", "content": h.user})
globals["global_parameters"]["history"].append({"role": "assistant", "content": h.assistant})
def build_full_query(user_input: str):
"""根据 globals 里的历史,生成带历史的 full query文本"""
history = globals["global_parameters"]["history"]
history_text = ""
for turn in history:
role = "用户" if turn["role"] == "user" else "助手"
history_text += f"{role}: {turn['content']}\n"
full_query = f"{history_text}用户: {user_input}\n助手:"
return full_query
class EcommerceAssistant:
def __init__(self):
self.main_pipeline = build_ecommerce_assistant()
def __call__(self, session_id: str, user_input: str, user_history: Optional[List[ChatHistory]] = None):
init_session(session_id, user_history)
full_query = build_full_query(user_input)
# 把带历史的 query 输入主 pipeline
response = self.main_pipeline(full_query)
# 更新历史到 globals
globals["global_parameters"]["history"].append({"role": "user", "content": user_input})
globals["global_parameters"]["history"].append({"role": "assistant", "content": response})
return response
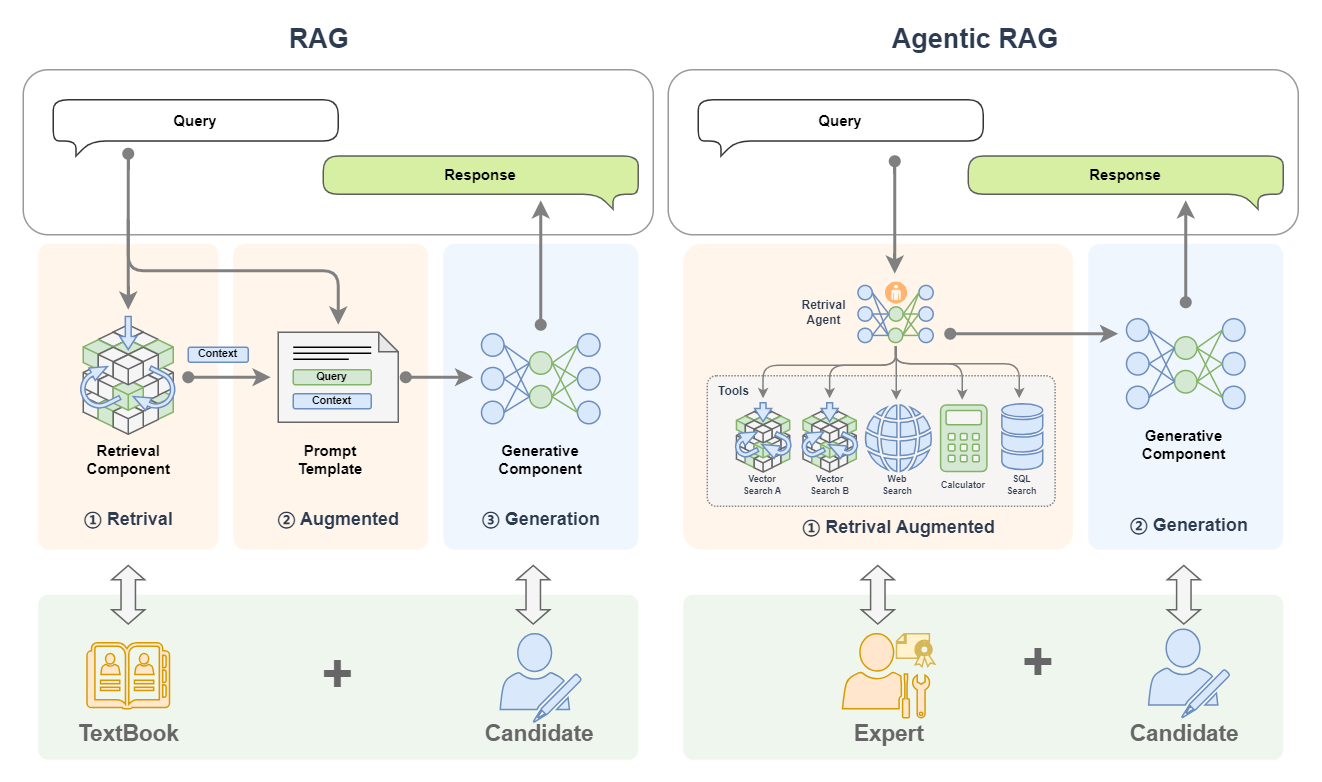
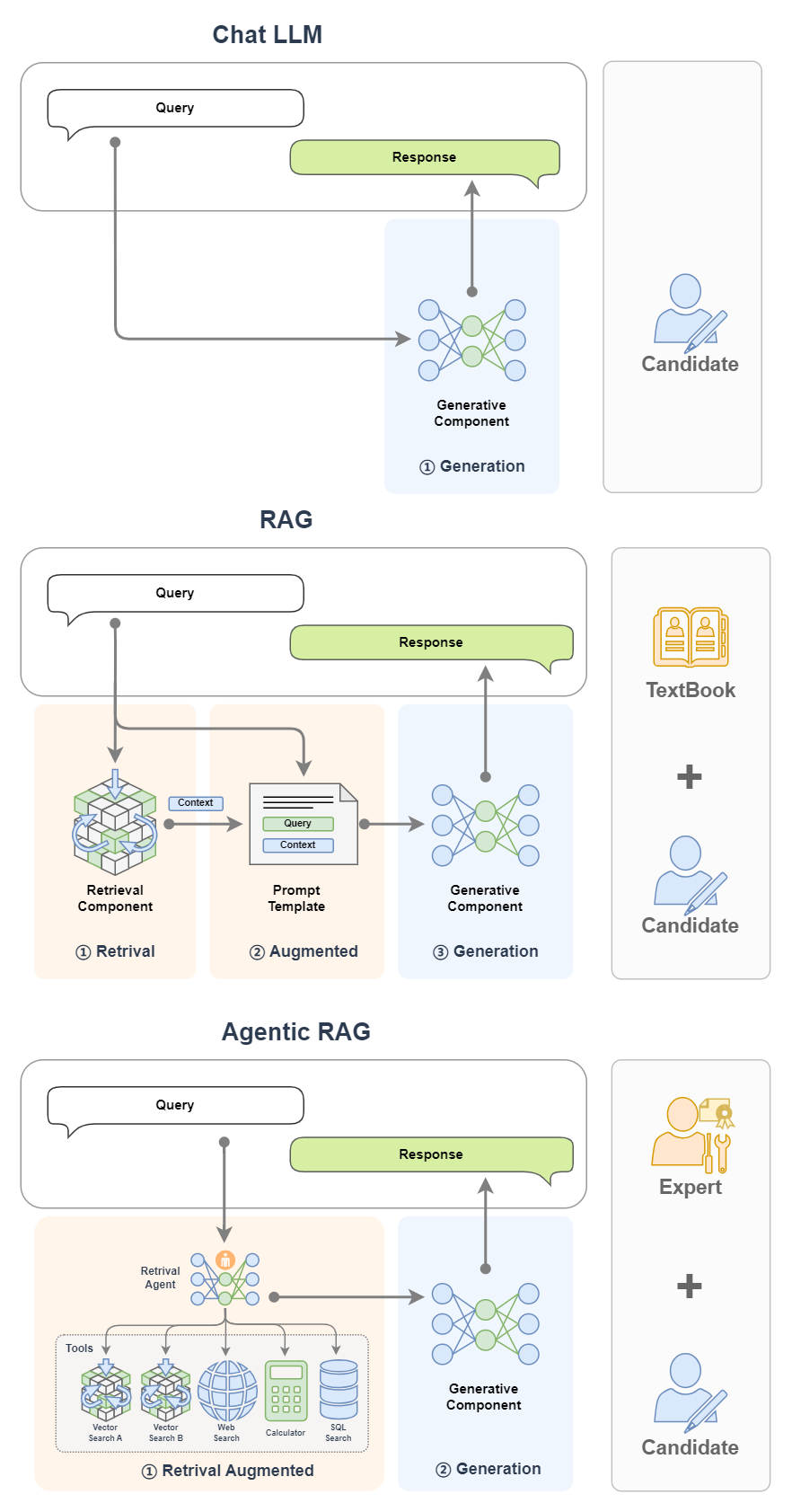
Agentic RAG,让RAG变聪明了!
传统RAG系统像是“工具人”——你提问,它查资料,再原样回复。而Agentic RAG则更进一步,它像一个智能助理,具备思考、计划、行动、反馈的完整智能体能力。
如果把 RAG 比作带着书本去考试的考生,那么 Agentic RAG 就是同时带着老师和书一起去考试的考生!
![]()
Agent能力觉醒:思考+行动+反馈的智能体式RAG
什么是 AI Agent?
从广义来看,AI Agent 是一个具备“自主性 + 执行力”的智能体,核心能力包括:
- LLM(大脑):负责理解任务、输出策略;
- Memory(记忆):记录历史对话与任务上下文;
- Planning(计划):能分解任务、灵活调整执行路径;
- Tools(工具):调用各类 API、函数、外部数据源达成任务目标。
在企业级应用中,这种Agent能力意味着你不需要写死流程,而是构建一个“会干活的员工”。
多类型智能体工作流
LazyLLM 提供了多种智能体实现方式,每一种代表一种“做事风格”:
|
|
Function Call Agent
|
ReAct
|
PlanAndSolve
|
ReWOO
|
|
工作流程
|
最大循环次数内循环:
- 试参调用工具;
- 观察工具输出,完成任务就结束循环。
|
最大循环次数内循环:
- 思考;
- 试参调用工具;
- 观察工具输出,完成任务就结束循环。
|
最大循环次数内循环:
- (重)计划并分解任务;
- 调用工具解处理当前前子任务;
- 观察工具输出,确定是否完成子任务,完成整个任务就结束循环
|
- 计划并分解任务;
- 调用工具逐步解决所有子任务
- 综合所有步骤结果进行反馈
|
|
工作特点
|
简单直接,思考过程不可见
|
引入思考环节,思考可见
|
强调任务的分解和任务的动态调整
|
强调整体规划和综合反馈
|
比如一个复杂问句:「汤姆的同桌的姐姐的家乡明天的气温是多少?」
- FunctionCall 只能一次查;
- ReAct 会尝试一步步思考;
- PlanAndSolve 会拆分成子问题串行执行;
- ReWOO 会并行跑完子任务再统一汇报。
工具动态调度:统一工具协议MCP让RAG自由调用世界
实践中的Agent开发与简化
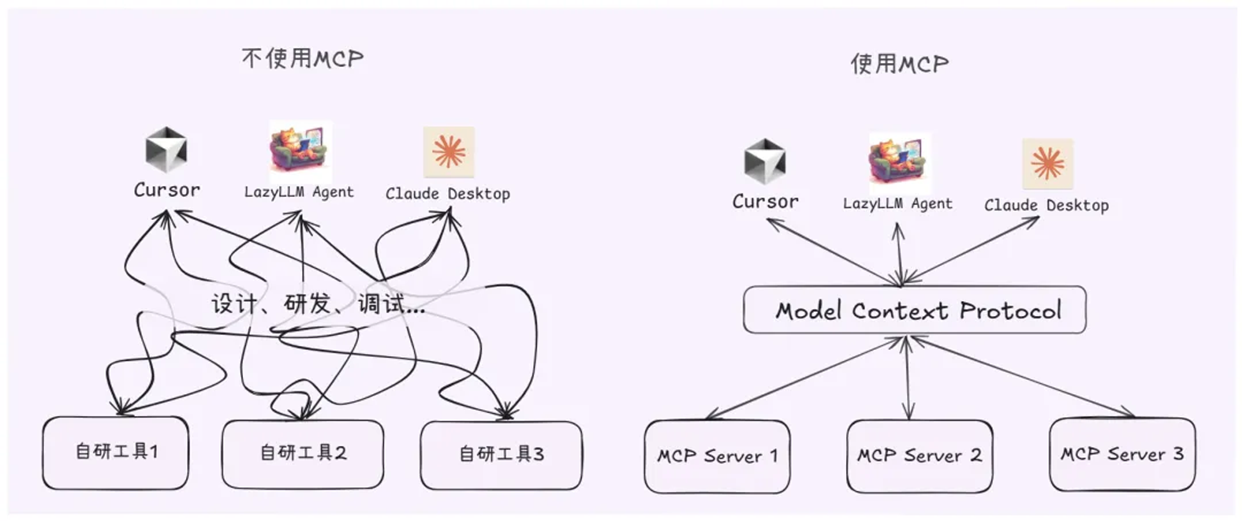
虽然智能体功能强大,但开发时常常面临工具重复定义、接口不统一、上下文难管理的问题。
MCP协议(Model Context Protocol) 是一个统一接口规范,像是智能体的“USB-C”。通过 MCP,模型能自动识别可用工具、资源、模板,极大简化了Agent开发流程。
![]()
在 LazyLLM 中,MCP 接入方式灵活,支持:
- ✅ 本地直接接入(Stdio 模式)
- ✅ 远程 Server 部署(SSE 模式)
通过 MCP,开发者无需反复写 Tool 定义,只需连接好一个 MCP Server,便可一键获得所有工具与接口信息,再搭配 LazyLLM 的 Agent 模块,即可快速搭建具备高阶“思维+执行”能力的 Agentic RAG 系统。
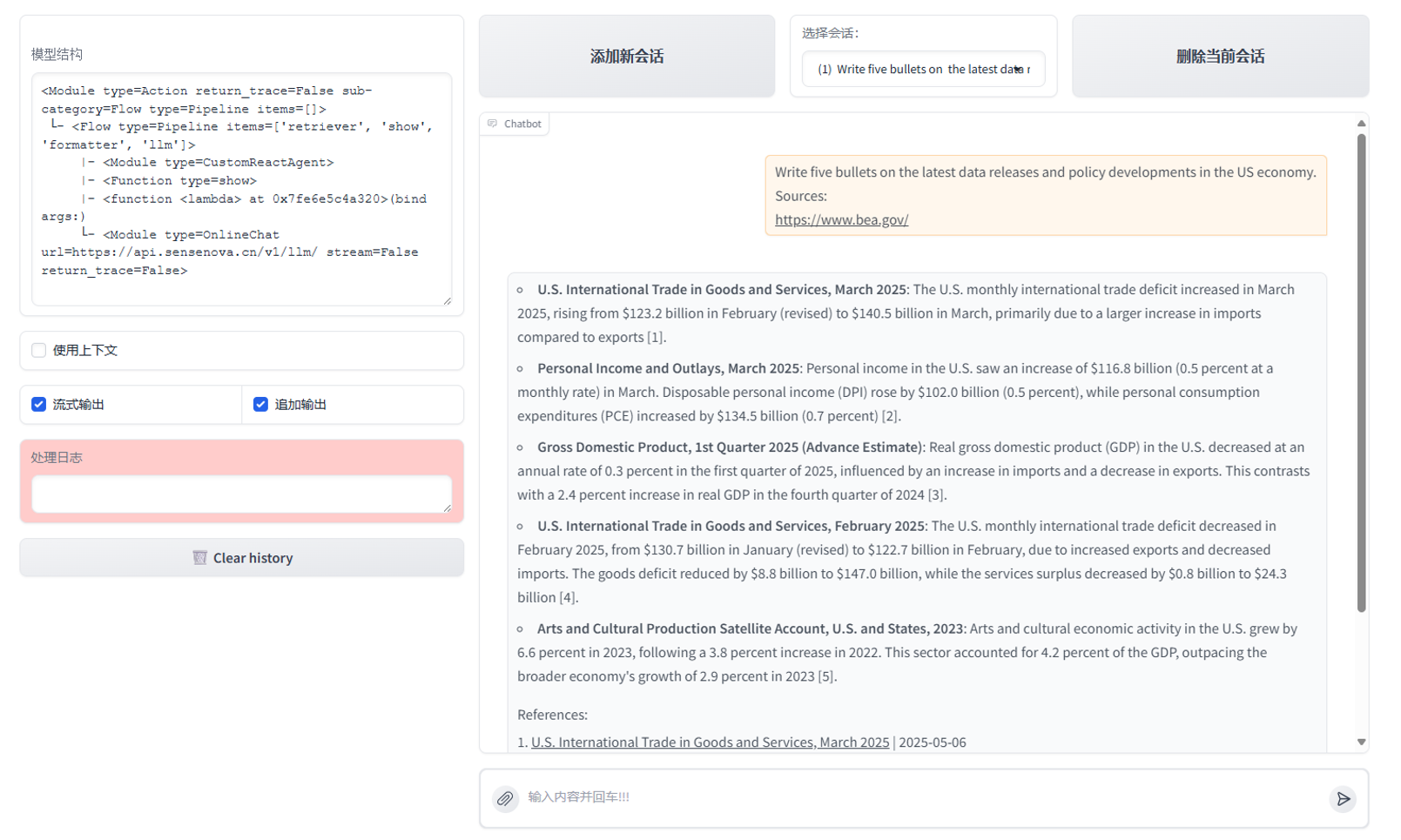
实战Demo:读文件+上网+本地保存
借助 LazyLLM + MCP + ReactAgent,你可以轻松构建这样的系统:
import lazyllm
from lazyllm.tools.agent
import ReactAgentfrom lazyllm.tools
import MCPClient
if __name__ == "__main__":
mcp_configs = {
"file_system": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@modelcontextprotocol/server-filesystem",
"./"
]
},
"play_wright": {
"url": "http://127.0.0.1:11244/sse"
}
}
client1 = MCPClient(command_or_url=mcp_configs["file_system"]["command"], args=mcp_configs["file_system"]["args"])
client2 = MCPClient(command_or_url=mcp_configs["play_wright"]["url"])
llm = lazyllm.OnlineChatModule(source="deepseek")
agent = ReactAgent(llm=llm.share(), tools=client1.get_tools()+client2.get_tools(), max_retries=15)
print(agent("浏览谷歌新闻,并写一个今日新闻简报,以markdown格式保存至本地。"))
系统会:
- ✅ 自动打开浏览器工具查新闻;
- ✅ 提取关键摘要;
- ✅ 用 Markdown 排版;
- ✅ 写入本地文件系统。
Agentic RAG:从检索到决策,激活智能体思维
在传统的 RAG 系统中,用户提出问题,大模型从知识库中检索文档,再基于这些文档生成答案。这种流程虽然简单高效,但局限也很明显:
- 检索只能进行一次,如果没查准就凉了;
- 数据来源单一,只能靠预先构建好的知识库;
- 模型只能“应答”,无法“思考”或“迭代”任务过程。
这正是 Agentic RAG 登场的意义所在。Agentic RAG 是 RAG 的“进化形态”,它将系统的关键组件替换为 AI 智能体,让模型不仅“查”还能“想”“试”“选”“再查”。
![]()
工作流程进化:从机械检索到智能规划
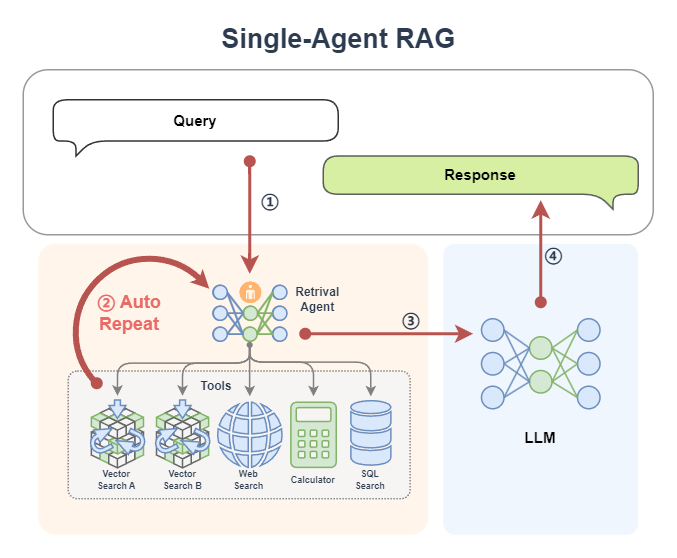
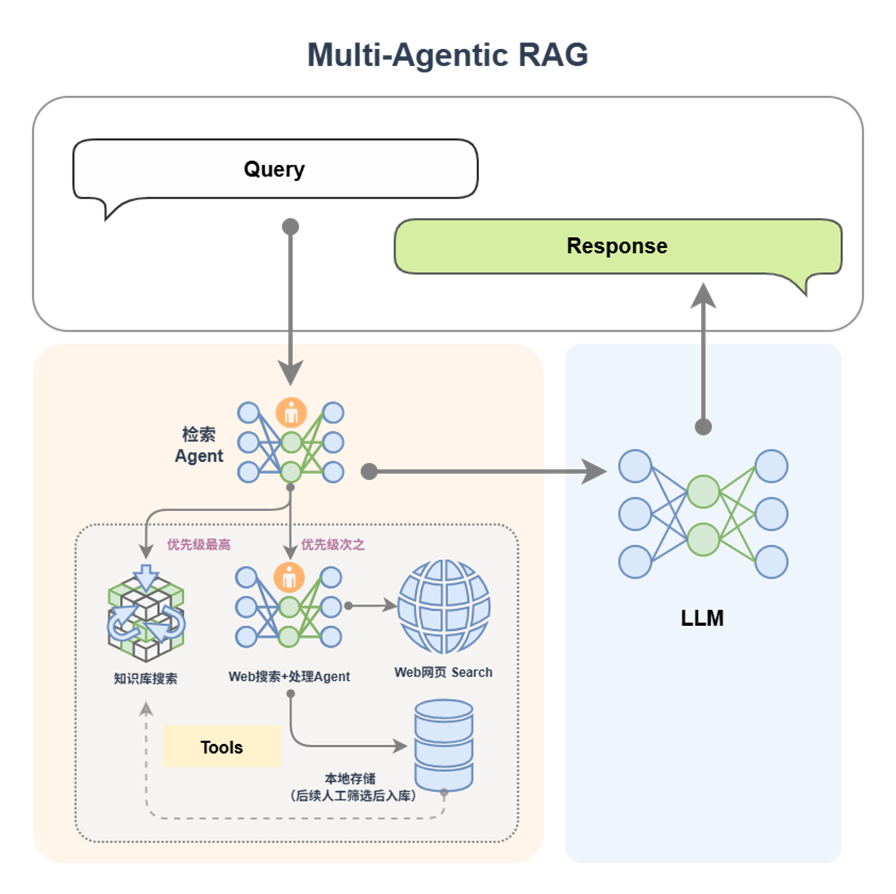
在 Agentic RAG 中,检索不再是“一次性事件”,而是一个由智能体动态控制的过程:
![]()
更进一步,系统可支持:
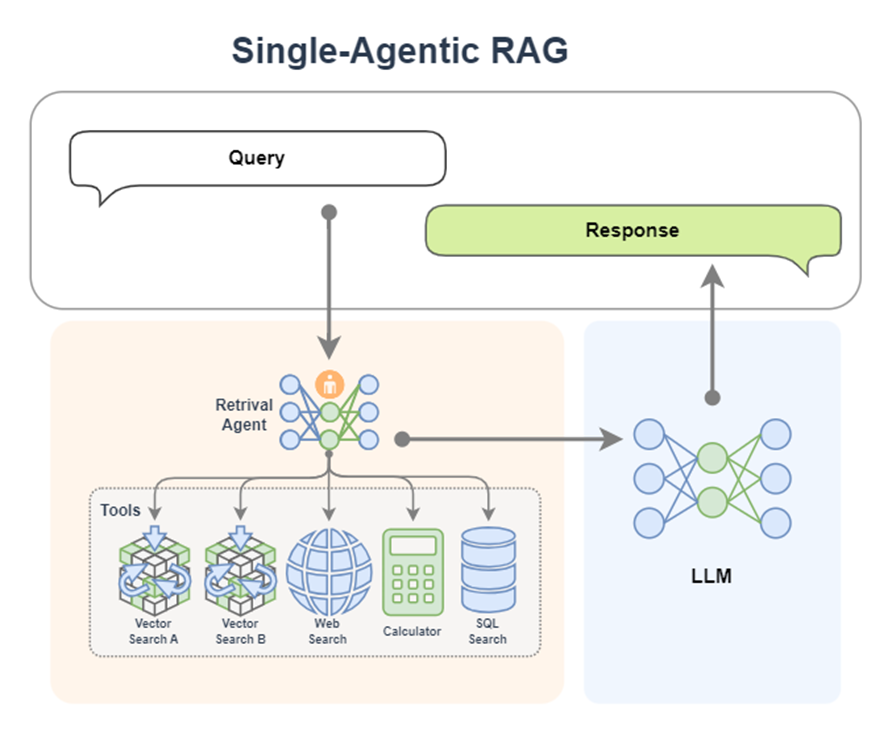
- 单Agent检索+LLM生成(例如一个带有知识库搜索能力的 ReactAgent)
![]()
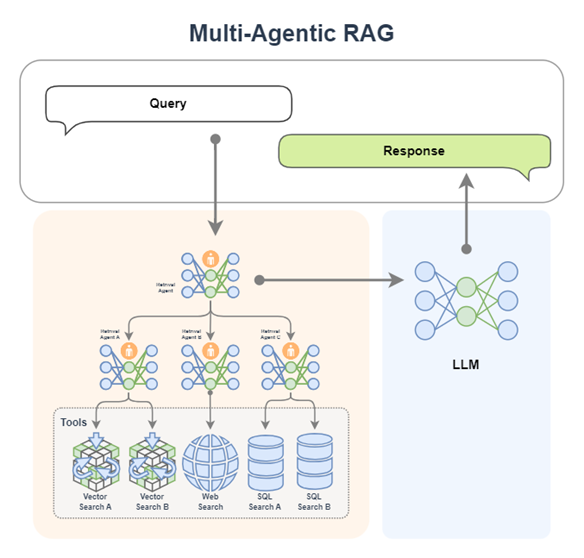
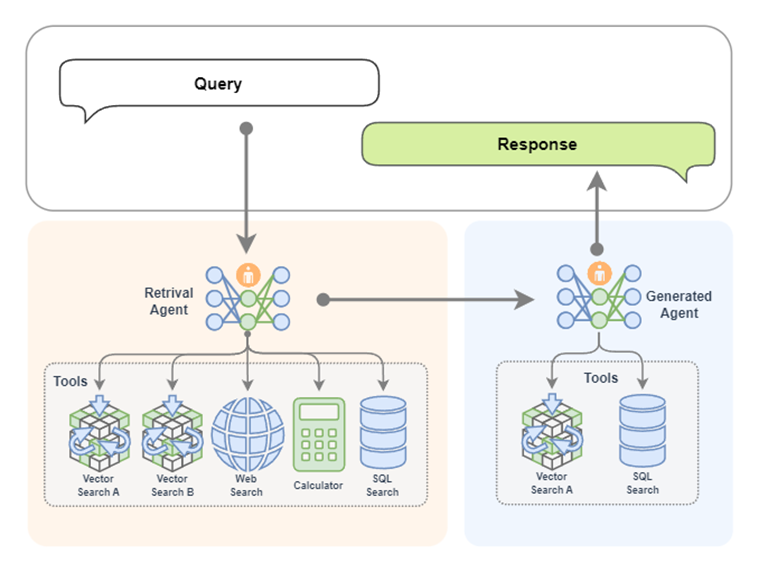
- 多Agent协作:每个Agent掌握不同工具,如网页搜索、数据库连接等,由主Agent协调调度
![]()
Retrieval Agent A 专家负责两个知识库的检索,Retrieval Agent B 专家负责网络搜索,Retrieval Agent C 专家负责两个数据库的搜索,最后Retrieval Agent 专家作为总指挥,他擅长搜索任务的分配。
![]()
也可以把生成模块给替换为一个 AI 智能体。这样我们就拥有了两个专家,一个专家负责检索,另外一个专家负责生成内容。检索专家拥有很多途径来自主决策检索信息,生成专家也可以边搜索边生成内容,如果它觉得生成的内容不满意,还会自动重新生成。
实践:从基础 RAG 到 Agentic RAG 的三步走
1️⃣ 基础 RAG 构建:使用 Retriever + Reranker + LLM 形成经典三段式流程
import lazyllm
from lazyllm import pipeline, bind, OnlineEmbeddingModule, SentenceSplitter, Document, Retriever, Reranker
prompt = 'You will play the role of an AI Q&A assistant and complete a dialogue task. In this task, you need to provide your answer based on the given context and question.'
documents = Document(dataset_path="rag_master", embed=OnlineEmbeddingModule(), manager=False)
documents.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
with pipeline() as ppl:
ppl.retriever = Retriever(documents, group_name="sentences", similarity="cosine", topk=1)
ppl.reranker = Reranker("ModuleReranker", model=OnlineEmbeddingModule(type="rerank"), topk=1, output_format='content', join=True) | bind(query=ppl.input)
ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=ppl.input)
ppl.llm = lazyllm.OnlineChatModule(stream=False).prompt(lazyllm.ChatPrompter(prompt, extro_keys=["context_str"]))
if __name__ == "__main__":
lazyllm.WebModule(ppl, port=range(23467, 24000)).start().wait()
2️⃣ 工具注册:将 RAG 流程注册为一个“知识库检索工具”
import lazyllm
from lazyllm import (pipeline, bind, OnlineEmbeddingModule, SentenceSplitter, Reranker,
Document, Retriever, fc_register, ReactAgent)
documents = Document(dataset_path="rag_master", embed=OnlineEmbeddingModule(), manager=False)
documents.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
with pipeline() as ppl_rag:
ppl_rag.retriever = Retriever(documents, group_name="sentences", similarity="cosine", topk=3)
ppl_rag.reranker = Reranker("ModuleReranker", model=OnlineEmbeddingModule(type="rerank"), topk=1, output_format='content', join=True) | bind(query=ppl_rag.input)
@fc_register("tool")
def search_knowledge_base(query: str):
'''
Get info from knowledge base in a given query.
Args:
query (str): The query for search knowledge base.
'''
return ppl_rag(query)
tools = ["search_knowledge_base"]
llm = lazyllm.OnlineChatModule(stream=False)
agent = ReactAgent(llm, tools)
if __name__ == "__main__":
res = agent("何为天道?")
print("Result: \n", res)
3️⃣ 构建 ReactAgent:用这个工具 + Agent 组合成 Agentic RAG,完成问答任务
import lazyllm
from lazyllm import (pipeline, bind, OnlineEmbeddingModule, SentenceSplitter, Reranker,
Document, Retriever, fc_register, ReactAgent)
prompt = 'You will play the role of an AI Q&A assistant and complete a dialogue task. In this task, you need to provide your answer based on the given context and question.'
documents = Document(dataset_path="rag_master", embed=OnlineEmbeddingModule(), manager=False)
documents.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
with pipeline() as ppl_rag:
ppl_rag.retriever = Retriever(documents, group_name="sentences", similarity="cosine", topk=3)
ppl_rag.reranker = Reranker("ModuleReranker", model=OnlineEmbeddingModule(type="rerank"), topk=1, output_format='content', join=True) | bind(query=ppl_rag.input)
@fc_register("tool")
def search_knowledge_base(query: str):
'''
Get info from knowledge base in a given query.
Args:
query (str): The query for search knowledge base.
'''
return ppl_rag(query)
tools = ["search_knowledge_base"]
with pipeline() as ppl:
ppl.retriever = ReactAgent(lazyllm.OnlineChatModule(stream=False), tools)
ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=ppl.input)
ppl.llm = lazyllm.OnlineChatModule(stream=False).prompt(lazyllm.ChatPrompter(prompt, extro_keys=["context_str"]))
if __name__ == "__main__":
lazyllm.WebModule(ppl, port=range(23467, 24000)).start().wait()
📌你也可以把 ReactAgent 替换为 FunctionCallAgent、PlanAndSolveAgent 或 ReWOOAgent,快速对比不同 Agent 行为的效果。
多 Agent 协作:专家组式 RAG 架构
![]()
- 检索Agent:根据查询内容确定检索工具(本地知识库/网络搜索)。
- Agent A(知识库专家):负责本地知识库的高效检索,优先处理结构化、稳定信息。
- Agent B(网络搜索专家):执行网页搜索、数据内容提取,并写入本地。
MCP网络搜索工具定义与注册:
# MCP-Search Web and Save Local
mcp_client1 = lazyllm.tools.MCPClient(command_or_url="python", args=["-m", "mcp_server_fetch"],)
search_agent = CustomReactAgent(llm=lazyllm.OnlineChatModule(source="sensenova", stream=False),
stream=False, custom_prompt=search_prompt, tools=mcp_client1.get_tools())
@fc_register("tool")
def search_web(query: str):
'''
Perform targeted web content retrieval using a combination of search terms and URL.
This tool processes both natural language requests and specific webpage addresses
to locate relevant online information.
Args:
query (str): Combined input containing search keywords and/or target URL
(e.g., "AI news from https://example.com/tech-updates")
'''
query += search_prompt
res = search_agent(query)
return res
RAG工具定义与注册+应用编排:
# RAG-Retriever
documents = Document(dataset_path='path/to/kb', manager=False)
documents.add_reader('*.json', process_json)
with pipeline() as ppl_rag:
ppl_rag.retriever = Retriever(documents, Document.CoarseChunk,
similarity="bm25", topk=1, output_format='content', join='='*20)
@fc_register("tool")
def search_knowledge_base(query: str):
'''
Get info from knowledge base in a given query.
Args:
query (str): The query for search knowledge base.
'''
res = ppl_rag(query)
return res
# Agentic-RAG:
tools = ['search_knowledge_base', 'search_web']
with pipeline() as ppl:
ppl.retriever = CustomReactAgent(lazyllm.OnlineChatModule(stream=False), tools, agent_prompt, stream=False)
ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=ppl.input)
ppl.llm = lazyllm.OnlineChatModule(stream=False).prompt(lazyllm.ChatPrompter(gen_prompt, extra_keys=["context_str"]))
# Launch: Web-UI
lazyllm.WebModule(ppl, port=range(23467, 24000), stream=True).start().wait()
![]()
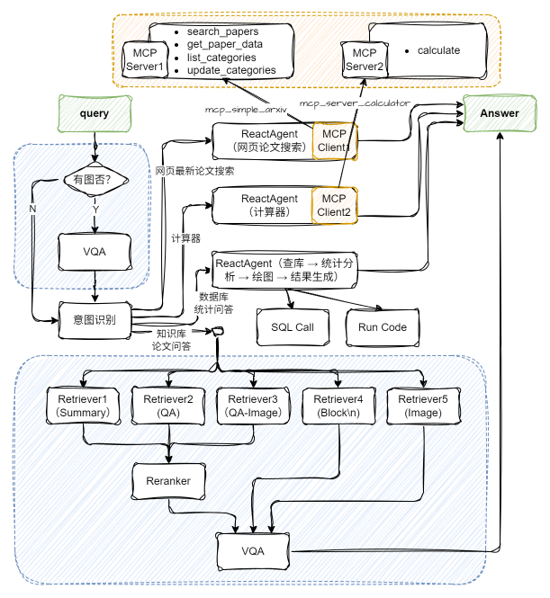
多模态Agentic RAG论文系统
![]()
配置两个MCP工具及Agent:
import json
import lazyllm
from lazyllm import ReactAgent
mcp_client1 = lazyllm.tools.MCPClient(
command_or_url="python",
args=["-m", "mcp_simple_arxiv"],
)
mcp_client2 = lazyllm.tools.MCPClient(
command_or_url="python",
args=["-m", "mcp_server_calculator"],
)
llm = lazyllm.OnlineChatModule(stream=False)
paper_agent = ReactAgent(llm, mcp_client1.get_tools(), return_trace=True)
calculator_agent = ReactAgent(llm, mcp_client2.get_tools(), return_trace=True)
别忘了提前安装这两个工具:
pip install mcp-simple-arxiv
pip install mcp-server-calculator
应用编排👇:
# 构建 rag 工作流和统计分析工作流
rag_ppl = build_paper_rag()
sql_ppl = build_statistical_agent()
# 搭建具备知识问答和统计问答能力的主工作流
def build_paper_assistant():
llm = OnlineChatModule(source='qwen', stream=False)
vqa = lazyllm.OnlineChatModule(source="sensenova",\
model="SenseNova-V6-Turbo").prompt(lazyllm.ChatPrompter(gen_prompt))
with pipeline() as ppl:
ppl.ifvqa = lazyllm.ifs(
lambda x: x.startswith('<lazyllm-query>'),
lambda x: vqa(x), lambda x:x)
with IntentClassifier(llm) as ppl.ic:
ppl.ic.case["论文问答", rag_ppl]
ppl.ic.case["统计问答", sql_ppl]
ppl.ic.case["计算器", calculator_agent]
ppl.ic.case["网页最新论文搜索", paper_agent]
return ppl
if __name__ == "__main__":
main_ppl = build_paper_assistant()
lazyllm.WebModule(main_ppl, port=23459, static_paths="./images", encode_files=True).start().wait()
更多技术交流,欢迎移步“LazyLLM”GZH!