秘塔AI搜索推出全新“极速”模型,响应速度最高400 tokens/秒
秘塔AI搜索推出了全新“极速”模型,新版模型不仅更快,准确率更高,逻辑也更清晰。 据介绍,秘塔AI团队通过在GPU上进行kernel fusion,以及在CPU上进行动态编译优化,在单张H800 GPU上实现了最高400 tokens/秒的响应速度,大部分问题2秒内就能答完。 用户可通过测速站点kuai.metaso.cn体验实际效果,但团队提示模型规模较小可能影响回答质量。
清华大学、腾讯混元、斯坦福大学及卡耐基梅隆大学的研究团队近日联合发布了一项新评估基准 ——RBench-V,专门针对多模态大模型的视觉推理能力进行测试。
RBench-V 基准测试包含803道题目,涉及多个领域,包括几何与图论、力学与电磁学、多目标识别和路径规划等。与以往只要求文字回答的评估不同,这次评测特别要求模型生成或修改图像内容,以支持推理过程。这意味着,模型不仅需要理解问题,还需要像人类一样,通过绘制辅助线或观察图形结构来进行思考。
测试结果显示,即便是表现最好的 o3模型,在 RBench-V 上的准确率也仅为25.8%,远低于人类专家的82.3%。Google 的 Gemini2.5模型紧随其后,仅获得20.2% 的得分。更令人担忧的是,许多开源模型的准确率在8% 至10% 之间,甚至有些模型的表现接近随机作答。
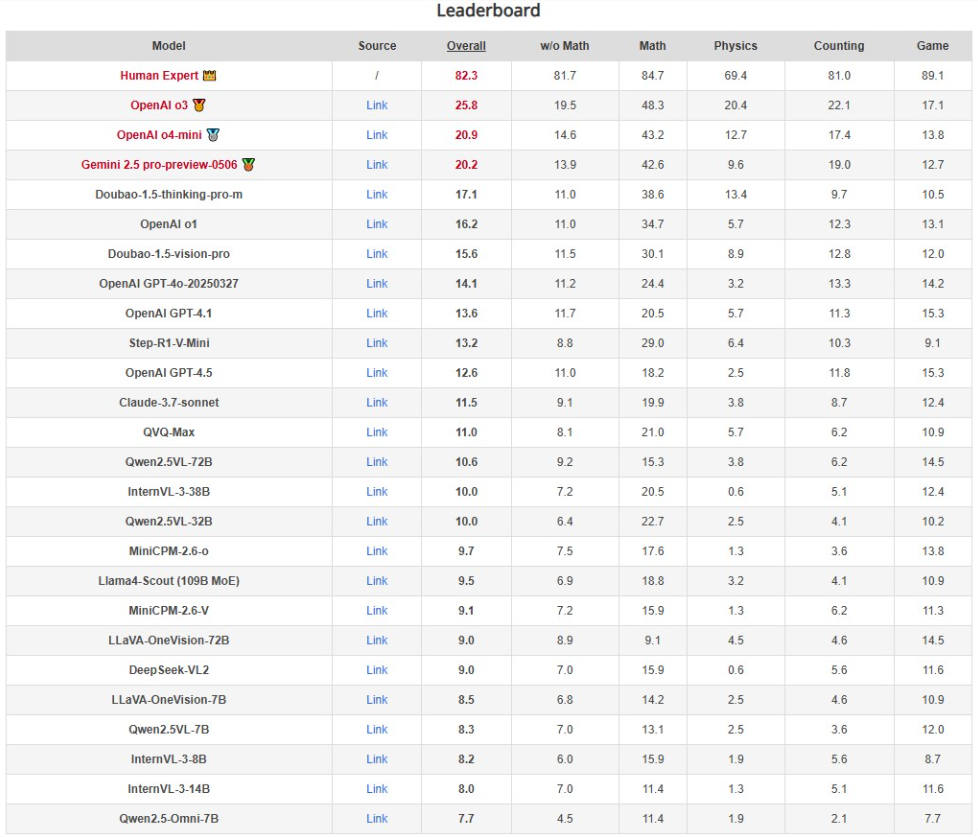
RBench-V 的研究表明,当前的多模态大模型在处理复杂的几何问题时,往往采取了简化的策略。与人类通过直观的可视化方法进行思考不同,大部分模型更倾向于将图形问题抽象为代数表达,用文本推理代替真实的图像操作。这一现象反映出它们在深层理解图像信息上的不足。
研究团队指出,未来的模型需要在推理过程中主动生成图像,以帮助思考,才能真正实现 “类人智能”。他们提到,多模态思维链和智能体推理等新方法,可能是人工智能发展的一条重要路径。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273